一种基于改进CBAM注意力机制的YOLOv7道路坑洼检测方法
本发明涉及道路坑洼目标检测,特别是一种基于改进cbam注意力机制的yolov7道路坑洼检测方法。
背景技术:
1、随着城市化进程的加速和交通运输的蓬勃发展,道路坑洼问题已成为城市交通管理和市容提升的一大难题。道路坑洼不仅会影响驾驶者的行车安全,还会导致车辆损坏、交通拥堵以及不适当的维护成本。传统的人工巡查方法虽然被广泛采用,但其效率低下、主观性强以及可能的遗漏等问题使得其无法满足现代城市交通管理的需求。
2、为了解决这些问题,计算机视觉领域逐渐引入深度学习技术来实现自动化的坑洼检测。然而,现有技术在应对复杂实际环境时仍存在一系列挑战:
3、1.数据获取和标注困难:深度学习模型通常需要大量的标注数据来进行训练。然而,采集并准确标注大规模的道路坑洼图像数据是一项耗时且费力的工作,而且可能受到光照、天气等因素的影响。
4、2.复杂背景和光照条件:道路坑洼通常位于复杂多变的背景之上,而且光照条件可能在不同时间和天气下发生变化。这导致现有模型在检测坑洼时容易受到背景干扰,从而产生误检或漏检现象。
5、3.坑洼形态多样性:道路坑洼的形状、大小和深度各不相同,有些坑洼可能很小,而有些可能很大,甚至可能呈现不规则形状。现有模型在适应各种不同形态的坑洼上仍然存在一定的困难。
6、4.实时性要求:城市交通管理需要实时监测道路情况,特别是在高交通流量的情况下。现有方法在检测速度方面可能无法满足快速响应的需求。
7、综上所述,尽管基于深度学习的坑洼检测方法在一定程度上取得了进展,但仍然存在诸多技术挑战和局限性。因此,为了提高坑洼检测的准确性、实时性和适应性,引入改进之后的cbam注意力机制、改进损失函数来改进yolov7算法是当前研究中的一项重要举措。通过这种方法,可以望文生义改进模型对动态背景、不同形态坑洼以及复杂光照条件的适应能力,为城市交通管理和道路维护提供更有效的解决方案。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种基于改进cbam注意力机制的yolov7道路坑洼检测方法,能够准确有效地进行道路坑洼目标检测。
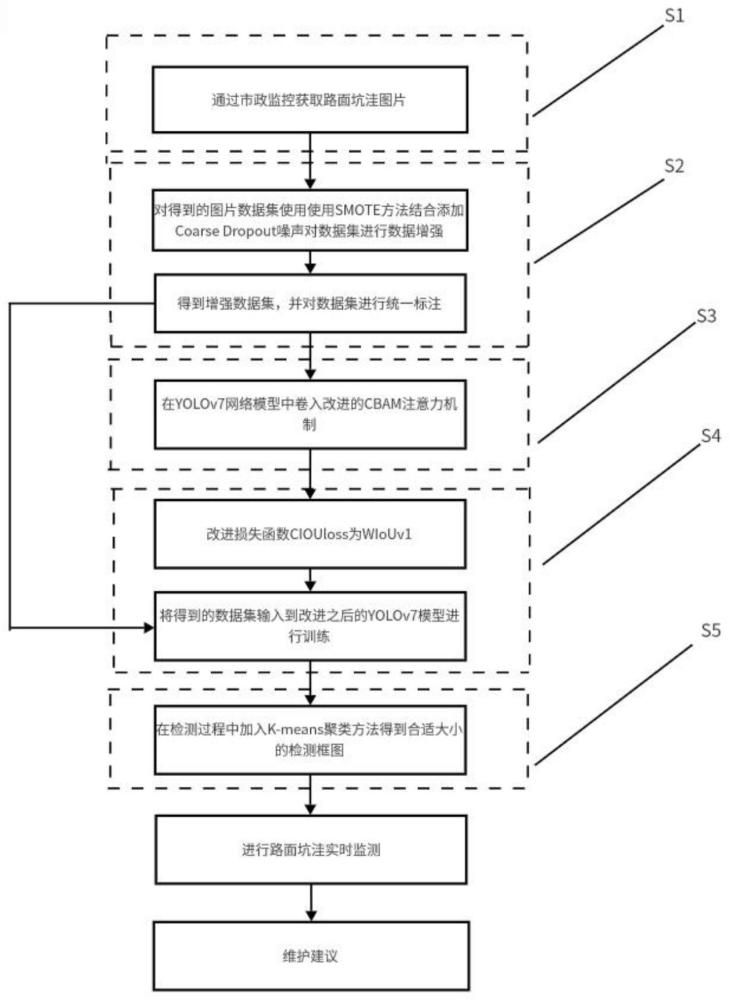
2、为实现上述目的,本发明采用如下技术方案:一种基于改进cbam注意力机制的yolov7道路坑洼检测方法,包括以下步骤:
3、步骤s1:通过市政监控采集道路坑洼图像数据,构建道路坑洼数据集;
4、步骤s2:对道路坑洼数据集使用smote方法结合添加coarse dropout噪声对数据集进行数据增强,通过人工合成新样本来处理数据不平衡的问题,从而提升分类器的性能;
5、步骤s3:构建基于yolov7算法的道路坑洼检测网络,该网络包括引入改进之后的注意力机制cbam;
6、步骤s4:将增强后的道路坑洼数据集输入到道路坑洼检测网络中进行模型训练,将预测结果与真实结果进行比对,利用wiouv1损失函数进行迭代,得到训练的模型并更新网络权重,获得训练后的改进yolov7目标检测模型;
7、步骤s5:将待检测的道路图像输入至训练后的坑洼检测模型中,在进行道路坑洼检测的过程中使用k-means方法对坑洼边界框尺寸进行聚类,获得合适的预设框尺寸,输出包含坑洼区域检测框的检测图像。
8、在一较佳的实施例中:所述步骤s1中具体包括以下步骤:
9、步骤s11:通过摄像头拍摄和查询资料,采取大量监控视角下的路面坑洼数据集;
10、步骤s12:将收集到的路面坑洼图像利用labelimg标注为yolo格式,构建初始数据集。
11、在一较佳的实施例中:所述步骤s2包括:
12、步骤s21:定义好特征空间,将每个样本对应到特征空间中的某一点,根据样本不平衡比例确定好一个采样倍率n;
13、步骤s22:对每一个小样本类样本(x_conv,y_conv),按欧氏距离找出k个最近邻样本,从中随机选取一个样本点,假设选择的近邻点为(xn,yn);在特征空间中样本点与最近邻样本点的连线段上随机选取一点作为新样本点(xnew,ynew),满足以下公式:
14、(xnew,ynew)=(x_conv,y_conv)+rand(0-1)*((xn-x_conv),(yn-y_conv))
15、其中rand(0-1)表示在(0-1)的范围内生成一个随机数;
16、步骤s23:重复以上的步骤,直到大、小样本数量平衡;
17、步骤s24:在原来数据集的基础上添加coarse dropout噪声,在面积大小可选定、位置随机的矩形区域上丢弃像素产生黑色矩形块,产生彩色噪声。
18、在一较佳的实施例中:所述步骤s3具体包括以下步骤:
19、步骤s31:在yolov7的网络中卷入改进之后cbam模块,cbam注意力机制模块分为通道注意力模块和空间注意力模块,计算过程如下:
20、步骤s32:在通道注意力模块中,输入特征图,分别经过最大池化和平均池化后输入到一个多层感知机mlp中,再将输出的特征进行加和操作输入到sigmoid激活函数中,获得归一化通道注意力权重,最后将该权重逐通道加权到输入特征图上,这样就完成了通道注意力对输入特征图的重新标定;通道注意力为
21、mc(f)=σ(mlp(avgpool(f))+mlp(maxpool(f)))
22、=σ(w1(w0(favg))+w1(w0(fmax)))
23、式中,f表示输入的特征图;avgpool(f)表示对特征图进行平均池化;maxpool(f)表示对特征图进行最大池化;mlp()表示将经过平均池化和最大池化后的特征图输入到多层感知机中;mc(f)表示通道注意力;表示sigmoid函数;w0表示多层感知机的第1层;w1表示多层感知机的第2层;favg和fmax分别表示对特征图f的平均池化和最大池化;
24、步骤s33:在空间注意力模块中,将通道注意力模块的输出特征图作为空间注意力模块的输入特征图,之后对输入特征图做基于通道的最大池化和平均池化,将这两者的结果做concat操作;之后利用一个卷积操作将通道数降为1,再经过sigmoid函数生成归一化空间注意力权重,最后将该权重与输入特征图做乘法,完成空间注意力对输入特征图的标定;空间注意力如下式,其中f7×7表示7×7的卷积层;
25、ms(f)=σ(f7×7([avgpool(f);maxpool(f)])
26、=σ(f7×7([favg;fmax]))
27、其中ms(f)表示空间注意力,avgpool(f)代表平均池化,maxpool(f)表示最大池化,σ表示sigmoid激活函数,favg代表经过平均池后的特征图,fmax代表经过最大池化后的特征图;
28、步骤s34:在空间注意力模块中,使用7x7卷积核感受野具有局限性,因此改进串行使用3个3x3大小的卷积层,改进之后的空间注意力公式如下:
29、ms_update(f)=σ(f1×1(concat((f3×3(avgpool(f);maxpool(f)),3))))
30、=σ(f1×1(concat((f3×3(favg;fmax),3))))
31、其中表示改进之后的空间注意力,avgpool(f)代表平均池化,maxpool(f)表示最大池化,concat(f3×3([favg;fmax]),3)表示对3个3x3的卷积层进行联结操作,f1×1表示1×1的卷积层,f3×3表示3×3的卷积层,σ表示sigmoid激活函数,favg代表经过平均池后的特征图,fmax代表经过最大池化后的特征图。
32、在一较佳的实施例中:步骤s4具体包括以下步骤:
33、步骤s41:将增强后的道路坑洼数据集输入到道路坑洼检测网络中进行模型训练,将预测结果与真实结果进行比对,利用wiouv1损失函数进行迭代,得到训练的模型并更新网络权重,获得训练后的改进yolov7目标检测模型;相关公式如下:
34、
35、liou=1-iou
36、
37、lwlouv1=rwlouliou
38、式中:其中iou表示预测边界框和真实边界框之间的并交比损失,a_t表示预测边界框,b_t表示真实边界框;rwiou∈[0,e)这将显著放大普通锚框的liou,liou∈[0,1],这将显著降低高质量锚框的ewiou;并在锚框与目标框重合较好的情况下显著降低其对中心点距离的关注;wg,hg分别为最小外接矩形的宽和高;*表示将wg,hg从计算图中分离,作用是为了防止rwiou产生阻碍收敛的梯度;(xpredict,ypredict)表示预测框的中心点,(xgt,ygt)表示真实框的中心点,liou表示iou的损失,lwlouv1表示wiouv1的损失函数。
39、在一较佳的实施例中:步骤s5具体包括以下步骤:
40、步骤s51:对每一张坑洼图片的坑洼进行标注,获得包含标记框位置和类别的
41、文本文件,每行的格式为:(x_idx,y_idx,w_idx,h_idx),idx∈[1,n],分别表示标记框相对原图的中心坐标和宽、高,n表示所有标记框的数量;
42、步骤s52:随机选择k个聚类中心点(w_idx,h_idx),idx∈[1,k],中心点坐标表示预设框的宽和高;
43、步骤s53:计算每个标记框和每个聚类中心点的距离d;距离定义为d=1-iou,iou表示预测边界框和真实边界框之间的并交比损失,将标记框分配给距离最近的聚类中心;
44、步骤s54:所有标记框分配结束后,对每个簇重新按式(1)计算聚类中心;
45、步骤s55:重复步骤s53、步骤s54,直到聚类中心不再变化,所得标记框即为所求预设框的尺寸;式(1)如下:
46、
47、nt表示所有标记框的数量,wnew为计算得到的新的聚类中心的宽,hnew为计算得到的新的聚类中心的高,wrt、hrt分别指不同聚类中心点预设框的宽和高
48、步骤s56:将k设置为3,然后在坑洼数据集上使用k-means聚类技术生成对应的预设框尺寸,具体的尺寸为(30×13)、(35×21)、(52×18)。
49、与现有技术相比,本发明具有以下有益效果:
50、1.本发明在yolov7算法的基础上添加了改进之后的cbam注意力机制。改进之后的cbam注意力机制能够聚焦于图像中的关键区域,通过动态调整通道权重,增强了坑洼区域的特征表达。这使得模型在复杂背景和多样坑洼形态的情况下能够更准确地定位坑洼目标。
51、2.由于道路坑洼的外观和纹理在不同情况下变化多端,改进之后的cbam注意力机制能够根据不同的背景和光照条件自适应地调整通道权重,从而提升了模型对不同场景的适应性。
52、3.结合了yolov7的高效性能,使得算法在实时性要求较高的城市交通监测场景下依然能够迅速响应,及时捕捉坑洼等道路问题。
53、4.同时,使用k-means方法对坑洼边界框尺寸进行聚类,获得合适的预设框尺寸;
54、5.并使用wiouv1的损失函数对原来的损失函数进行代替,wiou是基于动态非单调的聚焦机制设计的,动态非单调聚焦机制使用“离群度”替代iou对锚框进行质量评估,并提供了明智的梯度增益分配策略,使得模型更聚焦于低质量的锚框,提高模型的定位能力。
- 还没有人留言评论。精彩留言会获得点赞!