一种基于智能合约和评分卡设备自动报废的方法和系统与流程
本发明涉及区块链,具体为一种基于智能合约和评分卡设备自动报废的方法和系统。
背景技术:
1、本发明是通过融合区块链、机器学习、规则引擎等多种技术,基于各自的技术特点和要解决的业务问题进行深度融合而产生的,主要是为了提高业务处置效率和错误率,通过以机代人的模式,极大减少人工判断和处理的工作。通过评分卡模型提供可量化的评估依据,形成评分卡,利于积累和传递相关专业人员的知识。在执行评分卡阶段,引入了规则引擎,可以灵活调整业务规则而不用做软件升级等复杂流程。基于智能合约的自动执行,可以实现全流程、全时段自动化判断决策和决策记录的不可篡改性。通过利用区块链的技术手段解决追溯监管难题。
2、现有的技术的缺点如下:传统方案中的设备鉴定、报废申请、审批和处理等环节大多需要人工操作,处理效率相对较低。在传统方案中,人为操作较多,因此可能会出现错误或疏漏的情况,导致设备报废不及时或者处理不当等问题。不同城市或地区对于设备报废的处理方式和标准可能存在差异,导致资源利用不充分、环保处理不当等问题。传统方案中对于设备的回收和再利用效率不高,缺乏有效的分类和处理方式,导致部分可再利用的设备无法得到合理的处理。传统方案中对于设备报废的处理过程难以进行跟踪和监控,缺乏有效的信息化手段和工具,导致处理过程不透明、监管难度较大。传统方案中对于设备的环保和安全问题难以保障,缺乏有效的监管机制和技术手段,可能导致设备处理不当对环境造成污染或引发安全事故等问题。
技术实现思路
1、本发明的目的在于提供一种基于智能合约和评分卡设备自动报废的方法和系统,以解决上述背景技术中提出的问题。
2、为了解决上述技术问题,本发明提供如下技术方案:
3、一种基于智能合约和评分卡设备自动报废的方法,步骤如下:
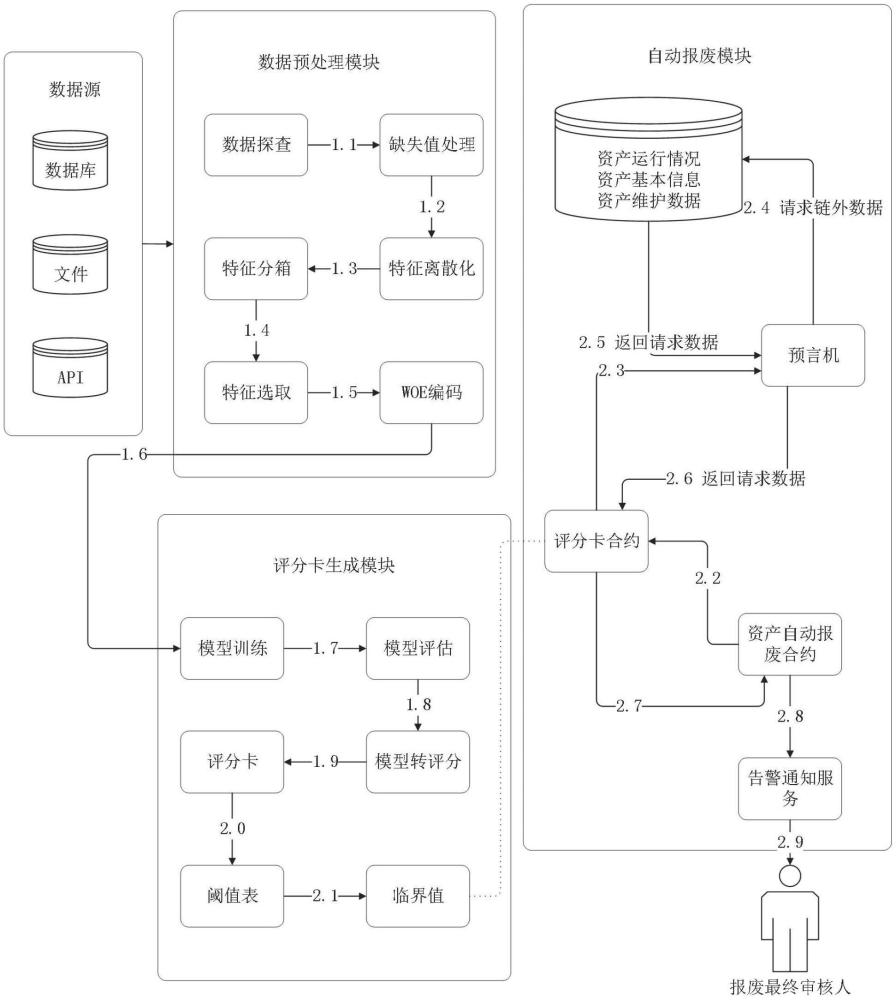
4、s1.1、基于报废数据源进行数据探查,对探查发现的缺失值进行处理;
5、s1.2、对于经过缺失值处理完成后的数据,针对连续性变量进行特征离散化处理;
6、s1.3、针对已使用年限进行特征分箱,将已使用年限进行特征分箱;
7、s1.4、分箱完成后,基于相关算法计算特征重要度,从而选择后续作为逻辑回归的参数;
8、s1.5、计算特征woe映射表,按照特征woe映射表,把特征的组别映射成对应的woe值;
9、s1.6、对变量对应的woe值进行归一化处理,然后采用逻辑回归和选择的入模变量进行模型训练;训练完成后,得到各个特征的权重和阈值;
10、s1.7、进入模型评估阶段,通过auc指标分别计算训练样本和测试样本的auc,然后根据auc进行评估模型是否可投产,只有auc>w时,模型才符合生产要求,其中w是一个正小数;
11、s1.8、逻辑回归模型的输出是一个概率值,表示为p(y=1),其中y是二分类问题中的目标变量,1表示正类别报废,0表示负类别不报废;评分模型的目标是将所述概率值转换为一个分数,所述分数用于决策;
12、s1.9、将基础分与各个特征结合woe映射表,通过代入模型训练好的得分计算公式生产对应的资产健康情况评分卡;
13、s2.0、模型投产时,先设定一个评分阈值,将低于评分阈值的客户拒绝;先统计阈值表,再参考评分阈值表的相关信息后,结合业务数据情况设定;
14、s2.1、基于历史数据和当前的物联设备报废阈值表的统计分布信息,确定一个具体的报废临界值;超过临界值的设备作为需要报废的资产,没有超过临界值的设备则拒绝报废,进入下一个周期;
15、s2.2、资产自动报废合约周期性执行,执行过程中需要调用评分卡合约;
16、s2.3、评分卡合约基于内置的逻辑,如果涉及到查询设备当前的各种状况的数据,会向预言机发送请求;
17、s2.4、预言机接受到链上请求后,进行异步执行,调用具体的数据查询接口获取数据,所述数据查询接口包括资产实时运行状况查询、资产基本信息查询、资产运维信息查询;
18、s2.5、查询到设备的运行情况、基本信息的链下数据后,返回给预言机;
19、s2.6、预言机异步将从链下获取到的数据回调给评分卡调用合约;
20、s2.7、相关依赖的数据都获取到后,基于评分卡合约计算出的设备评分,自动决策是同意报废还是拒绝报废,最终所有的执行过程都上链存储,确保可追溯可监管;
21、s2.8、资产自动报废合约封装最终的执行结果,调用告警通知服务;
22、s2.9、订阅了资产报废告警信息的相关人员,会自动收到合约报废模块执行的结果。
23、根据步骤s1.1,所述处理通过使用均值、中位数、新类别的处理方式,对具有缺失值的样本,进行剔除或者重新核实数据源的真实性;数据集读取并存储到变量train,然后通过train.isnull().sum()按列求缺失值并汇总,直接统计出各列特征的缺失值情况;然后遍历样本检查是否有缺失值,并将缺失值用均值填充,填充方法为:train.fillna(train.mean());其中mean表示一组数字的平均值,平均值的计算公式为:sum/n,其中sum是总和,n是数据的数量。fillna函数是python中的pandas库中常用的数据处理方法之一,用于填充dataframe中的缺失值或nan值,并将其替换为指定的数值或使用特定的填充方法。
24、根据步骤s1.2,特征离散化的步骤如下:
25、s3-1、将出厂日期转换为日期类型;
26、s3-2、确定离散化的时间单位,当前将出厂日期离散化为年份;核心代码:data['出厂年份']=data['出厂日期'].dt.year
27、s3-3、创建离散化的时间特征。核心代码:data['出厂年份离散化']=pd.cut(data['出厂年份'],bins=bins,labels=['2000以前','2001-2010','2011-2020']),经过以上处理后,出厂日期就离散化处理到3个离散的类别了。
28、根据步骤s1.3,进行特征分箱的步骤如下:
29、s4-1、将已使用年限转换成数值型;
30、s4-2、使用等频分箱,等频分箱将连续型特征的值分成固定数量的箱子,但每个箱子内包含的样本数量相等;
31、s4.3、创建分箱,将已使用年限等频分为4个箱子,使用pd.qcut进行等频分箱。核心代码:num_bins=4;data['已使用年限等频分箱']=pd.qcut(data['已使用年限'],q=num_bins,labels=false,duplicates='drop')
32、根据步骤s1.4,通过计算特征的协方差矩阵,筛选出排名前g的特征作为入模变量,其中g是一个正整数;协方差矩阵的具体计算过程如下:
33、首先,计算原始数据集的协方差矩阵,所述协方差矩阵描述了特征之间的线性关系,使用numpy库的np.cov()函数计算协方差矩阵;接着,对协方差矩阵进行特征值分解,以获得特征值和特征向量;所述特征值表示了每个特征的重要性,所述特征向量表示了新的特征空间中的主要方向;最后,对特征值进行排序,按降序排列,选择前g个最大的特征值对应的特征向量。
34、根据步骤s1.5,根据变量x第i组xi的每个取值,将数据分成bad组和good组;基于报废数据,资产报废为坏样本,反之则为好样本;对于bad组中的每个特征取值xi,计算badx=xi,表示特征xi在bad组中的累积值;对于good组中的每个特征取值xi,计算goodx=xi,表示特征xi在good组中的累积值;变量x第i组的woe值计算公式为:
35、woei=ln((badx=xi/badtotal)/(goodx=xi/goodtotal))
36、其中,badtotal是坏样本总个数,badx=xi是坏样本且x为第i组的个数,goodtotal是好样本总个数,goodx=xi是好样本且x为第i组的个数。
37、根据步骤s1.6,所述归一化是将数据缩放到[0,1],避免量级不同导致的误差,采用的归一化公式为:
38、xnorm=(x-xmin)/(xmax-xmin)
39、其中,x是变量的woe原始值,xmax是变量对应的woe最大值,xmin是变量对应的woe最小值;将选出的变量,放入逻辑回归模型中建模,直接调用sklearn里的逻辑回归模型进行训练。
40、核心代码:clf=logisticregression(penalty='none');
41、clf.fit(x_train[:,select_fetures_idx],y_train)
42、其中logisticregression是机器学习库中的逻辑回归模型的类。这里通过创建一个逻辑回归模型的实例,将其分配给clf变量。penalty='none'表示不使用正则化,即训练一个没有正则项的逻辑回归模型。clf.fit()是逻辑回归模型的训练函数,用于将模型拟合到给定的训练数据上。
43、x_train是训练数据集的特征矩阵,包含了训练样本的特征信息。每行代表一个样本,每列代表一个特征。
44、y_train是训练数据集的目标变量,包含了训练样本的标签或类别信息。当前对应为是否报废这一列。
45、x_train[:,select_features_idx]表示从训练数据集中选择特定列(特征)。select_features_idx是一个变量,包含了要选择的特征的索引。改索引为前面通过协方差排序后挑选的相关性较强的特征。
46、y_train是与训练数据集对应的目标变量(标签-是否报废)。
47、根据步骤s1.7,所述auc是评估roc曲线拱度的指标,roc代表成本与收益的变化,auc的计算过程如下:
48、s8-1、计算模型的预测概率:使用训练好的模型,对测试集中的样本进行预测,得到每个样本属于正类别的概率值;
49、s8-2、绘制roc曲线:根据模型的预测概率值,在不同的阈值下计算tpr和fpr,并绘制roc曲线;其中tpr为真正率,fpr为假正率,tpr=tp/(tp+fn),fpr=fp/(fp+tn),tp表示模型正确预测为正类别的样本数量,fn表示模型错误预测为负类别的样本数量,fp表示模型错误预测为正类别的负类别的样本数量,tn表示模型正确预测为负类别的样本数量;
50、s8-3、计算auc:将roc曲线下的面积近似分成若干个小梯形,计算每个小梯形的面积,对所有小梯形的面积进行累加,得到auc值。
51、根据步骤s1.8,将所述概率值转换为一个分数的公式是一个线性变换,公式如下:
52、score=offset+factor*(wx+b)
53、其中,score是转换后的分数,offset是偏移项,用于调整分数的基准值;factor是缩放因子,用于调整分数的尺度;wx是逻辑回归模型的线性部分,表示特征权重与特征值的线性组合;b是逻辑回归模型的截距项。
54、根据步骤s1.9,特征转分数步骤如下:
55、针对每个特征,首先需要计算特征的woe值,将特征的每个取值分成bad组和good组,并计算woe值;
56、对于每个特征,创建一个woe映射表,将特征的每个取值映射到对应的woe值,所述映射表将用于后续的分数计算;
57、计算基础分:基础分是一个常数,用于调整评分卡的整体范围,基础分没有实际的意义,本方案设置为p分,其中p是用户设置的正整数。
58、根据步骤s2.0,具体实现如下:统计阈值表:创建一个阈值表,包括不同评分阈值下的总设备数量,不同评分阈值下的被拒绝设备数量,不同评分阈值下的通过设备数量,不同评分阈值下的拒绝率,不同评分阈值下的通过率;其中拒绝率是被拒绝设备数除以总设备数,通过率是通过设备数除以总设备数。
59、根据步骤s2.3,预言机是区块链外信息写入区块链内的一种机制,当前方案考虑使用fisco-bcos微众银行开源的预言机组件实现。预言机允许区块链智能合约获取链外数据,主要由数据源、预言机合约、链上智能合约、链外api、链外数据处理器几个组件构成。本方案对应的数据源为资产管理系统,涉及的预言机合约为获取资产基本信息、获取资产实时运行状况、获取资产运维信息,分开实现主要考虑数据的独立性和可扩展性。链外api对应的是提供资产相关数据的接口。
60、系统包括数据预处理模块、评分卡生成模块、自动报废模块;
61、所述数据预处理模块负责对收集到的数据按需要进行预处理和特征提取,所述预处理包括数据探查、数据清洗、数据格式转换、缺失值处理、异常值检测;数据探查:数据探查根据数据来源进行数据量、数据质量、数据分布情况的基本统计分析;数据清洗:不同来源的数据进行标准化处理;数据格式转换,针对资产的日期类字段,将数据的日期型转换成类别型;缺失值处理,对于资产的部分信息缺失的,通过缺失值处理完善数据;异常值检测,通过变量和样本分布图,能够找到离群点,对于个别偏离的样本数据,能够选择性剔除,从而提升样本的数据质量。
62、所述评分卡生成模块利用机器学习算法和历史数据生成评分卡模型,所述评分卡模型是一种量化的评估工具,用于根据设备的特征对设备进行健康状况评估;通过对历史数据进行特征工程、模型训练和验证生成评分卡;在模型训练过程中,使用逻辑回归实现权重的计算;
63、所述自动报废模块利用智能合约技术将评分卡模型嵌入到报废流程中,通过资产自动报废合约,系统自动根据评分卡模型对物联设备进行评分,并根据设定的阈值自动判断是否通过审批;智能合约能够确保审批过程的透明性、安全性和不可篡改性;自动报废模块通过智能合约与其他模块进行交互,自动发送最终的资产报废情况给到报废最终审核人。
64、与现有技术相比,本发明所达到的有益效果是:
65、本发明通过智能合约和评分卡技术,实现了城市物联设备的自动报废处理,提高了处理效率,避免了人为操作失误和延误。
66、本发明通过智能合约的规则化处理,实现了设备报废的统一标准和规范,减少了不同城市或地区的差异,提高了资源利用和环保处理的科学性和合理性。
67、本发明通过智能合约和区块链技术的结合,实现了设备报废处理过程的跟踪和监控,提高了处理过程的透明度和监管效率,有利于保障环保和安全问题的落实。
68、本发明通过智能合约和评分卡技术,能够提高设备报废的鉴定和处理效率,缩短了处理周期,减少了不必要的浪费。
- 还没有人留言评论。精彩留言会获得点赞!