一种潮汐算力治理方法和装置与流程
本发明涉及计算机软件领域,特别涉及一种潮汐算力治理方法和装置。
背景技术:
1、对于证券行业相关单位特别是券商的技术部门部门任务而言,通常需要大量的计算资源来支持公司的交易、风险管理、分析和报告等任务。随着云计算的快速发展,多家券商公司的数据中心大规模使用了云计算平台、本地物理机、高性能计算及边缘计算等计算资源。事实上,券商业务对计算资源的使用需求变化往往类似于潮汐的涨落;故为确保交易等业务的性能及效率,需要开发一种治理技术,具有对数据中心各类算力自动按照业务需求进行分配的能力,使算力的分配和使用更加智能、高效和灵活,提高效率并降低成本。
技术实现思路
1、为了解决券商业务对计算资源的使用需求变化的算力计算和分配的问题,本发明提出了如下技术方案:
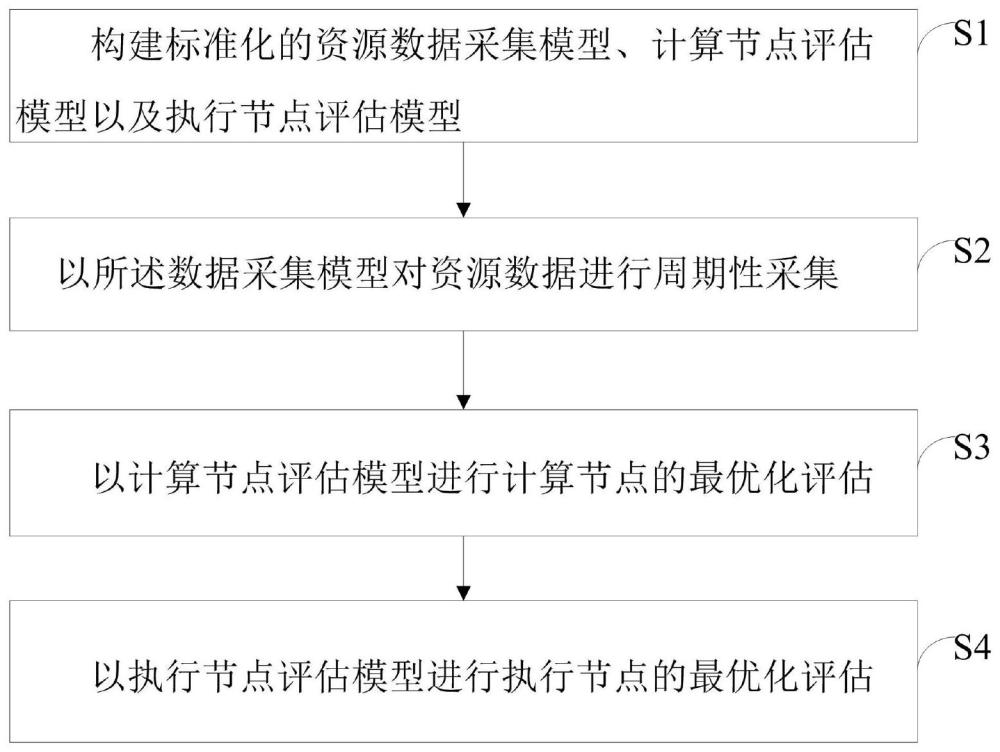
2、一种潮汐算力治理方法,包括步骤:
3、构建标准化的资源数据采集模型、计算节点评估模型以及执行节点评估模型;
4、以所述数据采集模型对资源数据进行周期性采集,所述资源数据包括计算节点资源数据和执行节点资源数据;
5、以计算节点评估模型进行计算节点的最优化评估;
6、以执行节点评估模型进行执行节点的最优化评估。
7、进一步地,所述的潮汐算力治理方法中,所述计算节点资源数据具体包括各个计算节点中执行编排任务的系统平均负载global_sysloadavg、全局多级缓冲池global_syscachevg、系统全局io性能以及子网ip的平均利用率global_sysiopsavg;所述“周期性采集”具体为:在随机时间t内,按照时间t为周期采集。
8、进一步地,所述的潮汐算力治理方法中,所述“以计算节点评估模型进行计算节点的最优化评估”具体包括:rscore数值越高则计算节点选择越优,所述rscore数值通过如下公式获取:
9、rscore=(100-nodeutil×w4×100)×score_系统平均负载×score_memory×score_storage×100;
10、其中,w4,w5,w6分别为由用户根据场景进行设置的系统平均负载global_sysloadavg、全局多级缓冲池global_syscachevg、系统全局io性能以及子网ip的平均利用率global_sysiopsavg的二次加权权值;
11、nodeutil为计算节点的服务利用率,由以下公式获取:nodeutil=((1-global_sysloadavg)×w1)×((1-global_syscachevg)×w2)×((1-global_storageavg)×w3×100;其中w1+w2+w3=1,w1、w2、w3分别为系统平均负载global_sysloadavg、全局多级缓冲池global_syscachevg、系统全局io性能以及子网ip的平均利用率global_sysiopsavg的一次加权权值,由用户根据场景进行设置;
12、score_系统平均负载为选择当前计算节点进行部署系统平均负载的匹配分,其获取公式为:score_sysloadavg=(1-(global_sysload_allocated+request_sysloadavg)/global_sysload)×w1,其中global_sysload_allocated为当前计算节点的已分配系统平均负载总量,request_sysloadavg为当前部署资源所需要的系统平均负载总量,global_sysload为当前计算节点的系统平均负载总量;
13、score_memory为选择当前计算节点进行部署时的memory匹配分,其获取公式为:score_memory=(1-(global_globalbuf_allocated+request_memmory)/global_globalbuf)×w5,其中global_globalbuf_allocated为当前计算节点的已分配的全局多级缓冲池总量;request_memmory为当前部署资源所需要的全局多级缓冲池总量;global_globalbuf为当前计算节点的已分配的全局多级缓冲池总量;score_storage为当前部署资源所需要的系统全局io性能总量,其获取公式为:score_storage=(1-(global_storage-global_sysiops_allocated-request_storage)/global_storage)×w6,其中global_sysiops为当前计算节点的某一种系统全局io性能类型总量;global_sysiops_allocated为当前计算节点的某一种系统全局io性能类型总量的已分配系统全局io性能;request_storage为当前部署资源所需要的系统全局io性能总量
14、进一步地,所述的潮汐算力治理方法中,所述执行节点资源数据具体包括各个执行节点的:系统平均负载srv_global_sysloadavg、全局多级缓冲池srv_global_syscachevg和进程池使用率srv_global_processavg;所述“周期性采集”具体为:在随机时间t内,按照时间t为周期采集。
15、进一步地,所述的潮汐算力治理方法中,所述“以执行节点评估模型进行执行节点的最优化评估”具体包括:tscore数值越高则执行节点选择越优,所述tscore数值通过如下公式获取:
16、tscore=(srv_sysloadavg-task_sysloadavg/srv_total_sysloadavg)×wt1×100×(srv_mem–task_mem)/global_srv_total_mem×wt2×100×(srv_process–task_process)/srv_total_process×wt3×100,其中wt1、wt2、wt3分别为由用户根据场景进行设置的执行节点系统平均负载、全局多级缓冲池和系统全局io性能参数的对应权值且wt1+wt2+wt3=1;
17、srv_sysloadavg为一次周期性采集中执行节点的当前可用系统平均负载数量;
18、task_sysloadavg为当前执行部署任务时所需要的可用系统平均负载数量;
19、srv_total_sysloadavg为一次周期性采集中执行节点的当前可用系统平均负载;
20、srv_mem为一次周期性采集中任务执行节点的全局多级缓冲池的可用全局多级缓冲池数;
21、task_mem为当前执行部署任务时所需要的可用全局多级缓冲池数;
22、srv_total_mem为一次周期性采集中任务节点的总内存数;
23、srv_process为一次周期性采集中任务节点的任务进程池的可用进程数;
24、task_process为当前执行部署任务需要的进程池的可用进程数;
25、srv_total_process一次周期性采集中任务节点的任务进程池的总进程数。
26、发明人同时提供了一种潮汐算力治理装置,包括模型构建单元、数据采集单元和评估单元;
27、所述模型构建单元用于构建标准化的资源数据采集模型、计算节点评估模型以及执行节点评估模型;
28、所述数据采集单元用于以所述数据采集模型对资源数据进行周期性采集,所述资源数据包括计算节点资源数据和执行节点资源数据;
29、所述评估单元用于以计算节点评估模型进行计算节点的最优化评估;
30、所述评估单元还用于以执行节点评估模型进行执行节点的最优化评估。
31、进一步地,所述的潮汐算力治理装置中,所述计算节点资源数据具体包括各个计算节点中执行编排任务的系统平均负载global_sysloadavg、全局多级缓冲池global_syscachevg、系统全局io性能以及子网ip的平均利用率global_sysiopsavg;数据采集单元所述“周期性采集”具体为:在随机时间t内,按照时间t为周期采集。
32、进一步地,所述的潮汐算力治理装置中,所述“以计算节点评估模型进行计算节点的最优化评估”具体包括:rscore数值越高则计算节点选择越优,所述rscore数值通过如下公式获取:
33、rscore=(100-nodeutil×w4×100)×score_系统平均负载×score_memory×score_storage×100;
34、其中,w4,w5,w6分别为由用户根据场景进行设置的系统平均负载global_sysloadavg、全局多级缓冲池global_syscachevg、系统全局io性能以及子网ip的平均利用率global_sysiopsavg的二次加权权值;
35、nodeutil为计算节点的服务利用率,由以下公式获取:nodeutil=((1-global_sysloadavg)×w1)×((1-global_syscachevg)×w2)×((1-global_storageavg)×w3×100;其中w1+w2+w3=1,w1、w2、w3分别为系统平均负载global_sysloadavg、全局多级缓冲池global_syscachevg、系统全局io性能以及子网ip的平均利用率global_sysiopsavg的一次加权权值,由用户根据场景进行设置;
36、score_系统平均负载为选择当前计算节点进行部署系统平均负载的匹配分,其获取公式为:score_sysloadavg=(1-(global_sysload_allocated+request_sysloadavg)/global_sysload)×w1,其中global_sysload_allocated为当前计算节点的已分配系统平均负载总量,request_sysloadavg为当前部署资源所需要的系统平均负载总量,global_sysload为当前计算节点的系统平均负载总量;
37、score_memory为选择当前计算节点进行部署时的memory匹配分,其获取公式为:score_memory=(1-(global_globalbuf_allocated+request_memmory)/global_globalbuf)×w5,其中global_globalbuf_allocated为当前计算节点的已分配的全局多级缓冲池总量;request_memmory为当前部署资源所需要的全局多级缓冲池总量;global_globalbuf为当前计算节点的已分配的全局多级缓冲池总量;score_storage为当前部署资源所需要的系统全局io性能总量,其获取公式为:score_storage=(1-(global_storage-global_sysiops_allocated-request_storage)/global_storage)×w6,其中global_sysiops为当前计算节点的某一种系统全局io性能类型总量;global_sysiops_allocated为当前计算节点的某一种系统全局io性能类型总量的已分配系统全局io性能;request_storage为当前部署资源所需要的系统全局io性能总量。
38、进一步地,所述的潮汐算力治理装置中,所述执行节点资源数据具体包括各个执行节点的:系统平均负载srv_global_sysloadavg、全局多级缓冲池srv_global_syscachevg和进程池使用率srv_global_processavg;所述“周期性采集”具体为:在随机时间t内,按照时间t为周期采集。
39、进一步地,所述的潮汐算力治理装置中,所述评估单元“以执行节点评估模型进行执行节点的最优化评估”具体包括:tscore数值越高则执行节点选择越优,所述tscore数值通过如下公式获取:
40、tscore=(srv_sysloadavg-task_sysloadavg/srv_total_sysloadavg)×wt1×100×(srv_mem–task_mem)/global_srv_total_mem×wt2×100×(srv_process–task_process)/srv_total_process×wt3×100,其中wt1、wt2、wt3分别为由用户根据场景进行设置的执行节点系统平均负载、全局多级缓冲池和系统全局io性能参数的对应权值且wt1+wt2+wt3=1;
41、srv_sysloadavg为一次周期性采集中执行节点的当前可用系统平均负载数量;
42、task_sysloadavg为当前执行部署任务时所需要的可用系统平均负载数量;
43、srv_total_sysloadavg为一次周期性采集中执行节点的当前可用系统平均负载;
44、srv_mem为一次周期性采集中任务执行节点的全局多级缓冲池的可用全局多级缓冲池数;
45、task_mem为当前执行部署任务时所需要的可用全局多级缓冲池数;
46、srv_total_mem为一次周期性采集中任务节点的总内存数;
47、srv_process为一次周期性采集中任务节点的任务进程池的可用进程数;
48、task_process为当前执行部署任务需要的进程池的可用进程数;
49、srv_total_process一次周期性采集中任务节点的任务进程池的总进程数。
50、区别于现有技术,本发明技术方案适用于多云数据中心的大规模计算节点资源的潮汐算力治理,通过任务的编排模型,可以对大规模高并发的算力进行动态的规划和编排。各种企业和组织可以利用这一策略,实现算力智能编排及治理。
- 还没有人留言评论。精彩留言会获得点赞!