一种图像渲染模型训练方法、设备以及可读存储介质与流程
本申请涉及模型训练,尤其涉及一种图像渲染模型训练方法、设备以及可读存储介质。
背景技术:
1、随着图像处理技术的深入发展,当前可以通过图像渲染模型生成图像。通过向图像渲染模型输入图像的参数,图像渲染模型就可以对该参数进行处理,从而生成对应的图像。如何让图像渲染模型在绘制图像中的文本,是技术人员日益关注的问题。
技术实现思路
1、本申请实施例提供一种图像渲染模型训练方法、设备以及可读存储介质,解决了图像渲染模型不能在图像中渲染文字的问题。
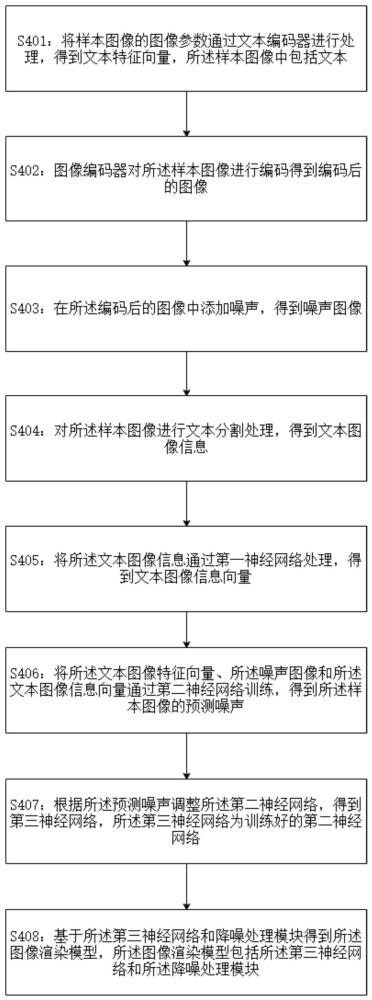
2、第一方面,本申请实施例提供一种图像渲染模型训练方法,包括:将样本图像的图像参数通过文本编码器进行处理,得到文本特征向量,样本图像中包括文本;对样本图像进行编码加噪处理,得到加噪后的图像;对样本图像进行文本分割处理,得到文本图像信息;将文本图像信息通过第一神经网络处理,得到文本图像信息向量;将文本图像特征向量、噪声图像和文本图像信息向量通过第二神经网络训练,得到样本图像的预测噪声;基于预测噪声调整第二神经网络的网络参数和/或结构,得到第三神经网络,第三神经网络是训练好的神经网络;根据第三神经网络和降噪处理模块得到图像渲染模型。
3、在上述实施例中,通过将图像的特征信息、添加噪声的图像以及文本图像信息(包括文本在图像中的位置信息)作为训练样本输入到神经网络中进行训练,从而使得神经网络可以输出图像的预测噪声。然后将该神经网络与降噪处理模块进行进行耦合,形成图像渲染模型。这样,当向该神经网络输入噪声图像、基于图像特征信息得到的文本特征向量、基于文本图像信息得到的文本图像信息向量之后,该神经网络就可以输出带有噪声的渲染图像。然后,该带有噪声的渲染图像通过降噪处理模块进行降噪,就可以得到带有文本的渲染图像。通过这种方式,可以训练出能够渲染文本图像的图像渲染模型。
4、结合第一方面,在一种可能实现的方式中,对样本图像进行编码加噪处理,得到加噪后的图像,具体包括:将样本图像通过图像编码器进行处理,得到编码后的图像;根据公式对编码后的图像进行加噪处理,得到加噪后的图像;其中,xi为第i次加噪后的图像,xi-1为第i-1次加噪后的图像,∈i是给图像xi所添加的噪声,αi为在给图像xi进行加噪时的数列参数。
5、结合第一方面,在一种可能实现的方式中,对样本图像进行编码加噪处理,得到加噪后的图像,具体包括:将样本图像通过图像编码器进行处理,得到编码后的图像;根据公式x′=x0*k,所述x′为加噪后的图像,所述x0为样本图像,所述k为加噪参数。
6、结合第一方面,在一种可能实现的方式中,将文本图像信息通过第一神经网络处理,得到文本图像信息向量,具体包括:将文本图像信息通过第一神经网络的映射层进行处理,得到处理后的文本图像信息xcond;将xcond通过公式进行处理,得到第一信息;其中,k=wk·ψ(x),v=wv·ψ(x),ψ(.)是将二维图像处理成多个一维token的函数,包括一层卷积和拉平(flatten)操作,wq,wk,wv是第一神经网络的transformer层中线性层的参数;将x′cond通过第一神经网络中unetencoder和zeroconv进行处理,得到和编码后的图像通道数相同的文本图像信息向量。
7、结合第一方面,在一种可能实现的方式中,将文本图像信息通过第一神经网络处理,得到文本图像信息向量,具体包括:将文本图像信息通过第一神经网络的映射层进行处理,得到处理后的文本图像信息xcond;将xcond通过第一神经网络中unetencoder和zeroconv进行处理,得到和编码后的图像通道数相同的文本图像信息向量。
8、结合第一方面,在一种可能实现的方式中,基于预测噪声调整第二神经网络的网络参数和/或结构,具体包括:通过公式计算样本图像中第i行、第j列对应的像素的第一噪声损失值;其中,l1_ij为样本图像中第i行、第j列对应像素的第一噪声损失值,∈pred_ij为样本图像中第i行、第j列对应像素的预测噪声,∈ij为样本图像中第i行、第j列对应像素添加的噪声;根据样本图像中每个像素的第一噪声损失值调整第二神经网络的网络参数和/或结构。
9、结合第一方面,在一种可能实现的方式中,基于预测噪声调整第二神经网络的网络参数和/或结构,具体包括:通过公式计算样本图像中第i行、第j列对应的像素的第一噪声损失值;其中,l1_ij为样本图像中第i行、第j列对应像素的第一噪声损失值,∈pred_ij为样本图像中第i行、第j列对应像素的预测噪声,∈ij为样本图像中第i行、第j列对应像素添加的噪声;根据公式计算样本图像中第i行、第j列对应的像素的第二噪声损失值;wt=1+gaussianfilter(resize(xseg)),xseg为文本图像信息;根据样本图像中每个像素的第二噪声损失值调整第二神经网络的网络参数和/或结构。
10、结合第一方面,在一种可能实现的方式中,基于预测噪声调整第二神经网络的网络参数和/或结构,具体包括:通过公式计算样本图像中第i行、第j列对应的像素的第一噪声损失值;其中,l1_ij为样本图像中第i行、第j列对应像素的第一噪声损失值,∈pred_ij为样本图像中第i行、第j列对应像素的预测噪声,∈ij为样本图像中第i行、第j列对应像素添加的噪声;根据公式计算样本图像中第i行、第j列对应的像素的第二噪声损失值;wij为样本图像第i行、第j列对应像素的权重值,wij是基于公式wij=prelu(l1_ij+μ)得到的,μ为取值在0~1之间的第一参数,prelu参数校正线性单元函数;根据样本图像中每个像素的第二噪声损失值调整第二神经网络的网络参数和/或结构。
11、第二方面,本申请实施例提供了一种图像渲染模型训练设备,包括存储器和处理器;
12、其中,所述存储器用于存储程序代码,所述处理器用于调用所述存储器存储的程序代码,执行上述第一方面及其各种可能实现的方式中的图像渲染模型训练方法。
13、第三方面,本申请实施例提供了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时,实现上述第一方面及其各种可能实现的方式中图像渲染模型训练方法。
14、第四方面,本申请实施例提供了一种计算机程序,该计算机程序包括指令,当所述计算机程序被计算机执行时,使得该计算机可以执行上述第二方面及其各种可能实现的方式中图像渲染模型训练设备所执行的流程。
技术特征:
1.一种图像渲染模型训练方法,其特征在于,包括:
2.如权利要求1所述的方法,其特征在于,所述对所述样本图像进行编码加噪处理,得到加噪后的图像,具体包括:
3.如权利要求1所述的方法,其特征在于,所述将所述文本图像信息通过第一神经网络处理,得到文本图像信息向量,具体包括:
4.如权利要求1所述的方法,其特征在于,所述基于所述预测噪声调整所述第二神经网络的网络参数和/或结构,具体包括:
5.如权利要求1所述的方法,其特征在于,所述基于所述预测噪声调整所述第二神经网络的网络参数和/或结构,具体包括:
6.如权利要求1所述的方法,其特征在于,所述基于所述预测噪声调整所述第二神经网络的网络参数和/或结构,具体包括:
7.一种图像渲染模型训练设备,其特征在于,包括:存储器和处理器,其中:
8.一种计算机可读存储介质,其特征在于,所述计算机可读存储介质存储有计算机程序,该计算机程序被处理器执行时,实现如权利要求1-6任意一项所述的方法。
技术总结
本申请提供了一种图像渲染模型训练方法、设备以及可读存储介质,该方法包括:将样本图像的图像参数通过文本编码器进行处理,得到得到文本特征向量,样本图像中包括文本;对样本图像进行编码加噪处理,得到加噪后的图像;对样本图像进行文本分割处理,得到文本图像信息;将文本图像信息通过第一神经网络处理,得到文本图像信息向量;将文本图像特征向量、噪声图像和文本图像信息向量通过第二神经网络训练,得到样本图像的预测噪声;基于预测噪声调整第二神经网络的网络参数和/或结构,得到第三神经网络,第三神经网络是训练好的神经网络;根据第三神经网络和降噪处理模块得到图像渲染模型。
技术研发人员:张天宇,杨青
受保护的技术使用者:度小满科技(北京)有限公司
技术研发日:
技术公布日:2024/2/29
- 还没有人留言评论。精彩留言会获得点赞!