一种人脸特征的生成方法、系统以及电子设备与流程
本技术涉及人脸识别,特别是一种人脸特征的生成方法、系统以及电子设备。
背景技术:
1、人脸特征生成模型能够根据任意人的语音,生成与“人脸渲染模型”稳定适配的系数,必须具备普适性/泛化性,无论输入谁的语音都能生成稳定的人脸特征系数。因此,为提高人脸特征生成模型的泛化能力,通常使用多套不同说话人的数据集合联合训练该模型,以求在训练阶段让模型见识到尽可能多变的语音。
2、但是,为追求泛化性,现有“人脸特征生成模型”虽然使用多套不同说话人的数据集合联合训练,但并没有针对性地弥平人际之间的差异从而提高其泛化性。实际效果的泛化性不足,对于输入不同人的语音,识别效果波动较大,对于输入与训练数据接近的语音时识别效果较好,输入与训练数据差异大的语音时,识别效果较差。
3、因此,亟需一种新的人脸特征的生成方法。
技术实现思路
1、鉴于上述问题,本技术实施例提供了一种人脸特征的生成方法、系统以及电子设备,以便克服上述问题或者至少部分地解决上述问题。
2、本技术实施例第一方面,提供了一种人脸特征的生成方法,所述方法包括:
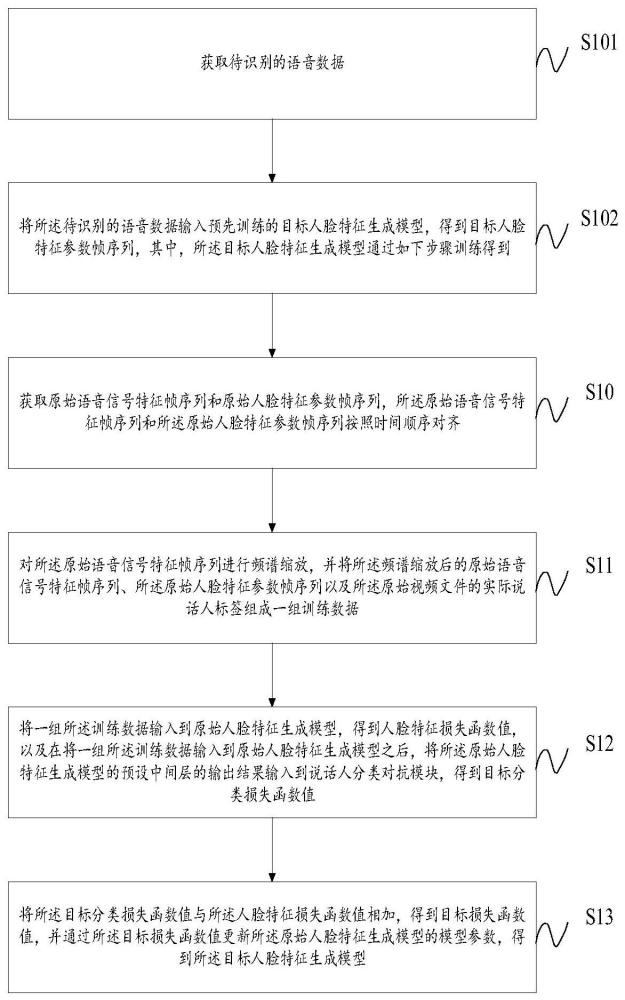
3、获取待识别的语音数据;
4、将所述待识别的语音数据输入预先训练的目标人脸特征生成模型,得到目标人脸特征参数帧序列,其中,所述目标人脸特征生成模型通过如下步骤训练得到:
5、获取原始语音信号特征帧序列和原始人脸特征参数帧序列,所述原始语音信号特征帧序列和所述原始人脸特征参数帧序列按照时间顺序对齐;
6、对所述原始语音信号特征帧序列进行频谱缩放,并将所述频谱缩放后的原始语音信号特征帧序列、所述原始人脸特征参数帧序列以及所述原始视频文件的实际说话人标签组成一组训练数据;
7、将一组所述训练数据输入到原始人脸特征生成模型,得到人脸特征损失函数值,以及在将一组所述训练数据输入到原始人脸特征生成模型之后,将所述原始人脸特征生成模型的预设中间层的输出结果输入到说话人对抗分类模块,得到目标分类损失函数值;
8、将所述目标分类损失函数值与所述人脸特征损失函数值相加,得到目标损失函数值,并通过所述目标损失函数值更新所述原始人脸特征生成模型的模型参数,得到所述目标人脸特征生成模型。
9、可选地,所述说话人对抗分类模块依次包括:梯度反转层、多层下采样卷积层、全局均值池化层以及logit映射层;所述将所述原始人脸特征生成模型的预设中间层的输出结果输入到说话人对抗分类模块,得到目标分类损失函数值,包括:
10、将所述原始人脸特征生成模型的所述预设中间层的输出结果输入所述说话人对抗分类模块,依次经过所述梯度反转层、所述多层下采样卷积层、所述全局均值池化层以及所述logit映射层,并经过softmax激活函数计算,得到预测说话人标签;
11、计算所述预测说话人标签与所述实际说话人标签之间的损失函数值,得到分类损失函数值;
12、将所述分类损失函数值执行梯度反向回传,并在所述梯度反转层对所述分类损失函数值的梯度值进行取反,得到所述目标分类损失函数值。
13、可选地,所述将一组所述训练数据输入到原始人脸特征生成模型,得到人脸特征损失函数值,包括:
14、从一组所述训练数据中选取所述频谱缩放后的原始语音信号特征帧序列,并将所述频谱缩放后的原始语音信号特征帧序列输入到原始人脸特征生成模型,得到预测人脸特征参数帧序列;
15、从同一组所述训练数据中选取所述原始人脸特征参数帧序列,并计算所述预测人脸特征参数帧序列与所述原始人脸特征参数帧序列之间的损失函数值,得到所述人脸特征损失函数值。
16、可选地,所述对所述原始语音信号特征帧序列进行频谱缩放,包括:
17、获取随机缩放比例;
18、根据所述随机缩放比例,对所述原始语音信号特征帧序列中的每一帧语音信号特征分别进行线性插值缩放,并在任一帧所述语音信号特征完成线性插值缩放之后,返回到各个所述语音信号特征各自的原始维度。
19、可选地,所述根据所述随机缩放比例,对所述原始语音信号特征帧序列中的每一帧语音信号特征分别进行线性插值缩放,并在任一帧所述语音信号特征完成线性插值缩放之后,返回到各个所述语音信号特征各自的原始维度,包括:
20、在所述随机缩放比例大于0且小于1的情况下,对任一帧所述语音信号特征进行线性插值缩减,得到缩减后的语音信号特征;
21、获取所述缩减后的语音信号特征中的最后一维语音信号特征,并将所述最后一维语音信号特征加上随机数得到新的语音信号特征,以对所述缩减后的语音信号特征进行补足,直到所述缩减后的语音信号特征的维度达到所述原始维度。
22、可选地,所述根据所述随机缩放比例,对所述原始语音信号特征帧序列中的每一帧语音信号特征分别进行线性插值缩放,并在任一帧所述语音信号特征完成线性插值缩放之后,返回到各个所述语音信号特征各自的原始维度,包括:
23、在所述随机缩放比例大于等于1的情况下,对任一帧所述语音信号特征中的所有维度的语音信号特征依次进行线性插值放大,得到放大后的语音信号特征,并将放大后的所述语音信号特征超出所述原始维度的部分进行删减,所述放大后的语音信号特征中包括原始语音信号特征和所述原始语音信号特征按照所述随机缩放比例放大后的语音信号特征。
24、可选地,所述对所述原始语音信号特征帧序列进行频谱缩放,并将所述频谱缩放后的原始语音信号特征帧序列、所述原始人脸特征参数帧序列以及所述原始视频文件的实际说话人标签组成一组训练数据,包括:
25、获取多个说话人的原始视频文件;
26、将各个所述说话人的原始视频文件分别分解成各个所述说话人的原始语音信号特征帧序列和原始人脸特征参数帧序列;
27、分别对各个所述说话人的原始语音信号特征帧序列进行频谱缩放,并将各个所述说话人的频谱缩放后的原始语音信号特征帧序列以及各自对应的原始人脸特征参数帧序列以及各自对应的实际说话人标签组成各个所述说话人的训练数据。
28、可选地,在得到目标人脸特征参数帧序列,所述方法还包括:
29、从预设视频模板中获取原始图像序列;
30、将所述目标人脸特征参数帧序列和所述原始图像序列输入预先训练好的人脸渲染模型,生成目标图像。
31、本技术实施例第二方面,提供了一种人脸特征的生成系统,所述系统包括:
32、第一获取模块,用于获取待识别的语音数据;
33、第一输入模块,用于将所述待识别的语音数据输入预先训练的目标人脸特征生成模型,得到目标人脸特征参数帧序列,其中,所述目标人脸特征生成模型通过如下步骤训练得到:
34、第二获取模块,用于获取原始语音信号特征帧序列和原始人脸特征参数帧序列,所述原始语音信号特征帧序列和所述原始人脸特征参数帧序列按照时间顺序对齐;
35、缩放模块,用于对所述原始语音信号特征帧序列进行频谱缩放,并将所述频谱缩放后的原始语音信号特征帧序列、所述原始人脸特征参数帧序列以及所述原始视频文件的实际说话人标签组成一组训练数据;
36、第二输入模块,用于将一组所述训练数据输入到原始人脸特征生成模型,得到人脸特征损失函数值,以及在将一组所述训练数据输入到原始人脸特征生成模型之后,将所述原始人脸特征生成模型的预设中间层的输出结果输入到说话人对抗分类模块,得到目标分类损失函数值;
37、更新模块,用于将所述目标分类损失函数值与所述人脸特征损失函数值相加,得到目标损失函数值,并通过所述目标损失函数值更新所述原始人脸特征生成模型的模型参数,得到所述目标人脸特征生成模型。
38、可选地,所述说话人对抗分类模块依次包括:梯度反转层、多层下采样卷积层、全局均值池化层以及logit映射层;所述将所述原始人脸特征生成模型的预设中间层的输出结果输入到说话人对抗分类模块,得到目标分类损失函数值,所述第二输入模块,包括:
39、第一输入子模块,用于将所述原始人脸特征生成模型的所述预设中间层的输出结果输入所述说话人对抗分类模块,依次经过所述梯度反转层、所述多层下采样卷积层、所述全局均值池化层以及所述logit映射层,并经过softmax激活函数计算,得到预测说话人标签;
40、第一计算子模块,用于计算所述预测说话人标签与所述实际说话人标签之间的损失函数值,得到分类损失函数值;
41、反向回传子模块,用于将所述分类损失函数值执行梯度反向回传,并在所述梯度反转层对所述分类损失函数值的梯度值进行取反,得到所述目标分类损失函数值。
42、可选地,所述将一组所述训练数据输入到原始人脸特征生成模型,得到人脸特征损失函数值,所述第一输入模块,包括:
43、第一选取子模块,用于从一组所述训练数据中选取所述频谱缩放后的原始语音信号特征帧序列,并将所述频谱缩放后的原始语音信号特征帧序列输入到原始人脸特征生成模型,得到预测人脸特征参数帧序列;
44、第二选取子模块,用于从同一组所述训练数据中选取所述原始人脸特征参数帧序列,并计算所述预测人脸特征参数帧序列与所述原始人脸特征参数帧序列之间的损失函数值,得到所述人脸特征损失函数值。
45、可选地,所述对所述原始语音信号特征帧序列进行频谱缩放,所述缩放模块,包括:
46、第一获取子模块,用于获取随机缩放比例;
47、缩放子模块,用于根据所述随机缩放比例,对所述原始语音信号特征帧序列中的每一帧语音信号特征分别进行线性插值缩放,并在任一帧所述语音信号特征完成线性插值缩放之后,返回到各个所述语音信号特征各自的原始维度。
48、可选地,所述根据所述随机缩放比例,对所述原始语音信号特征帧序列中的每一帧语音信号特征分别进行线性插值缩放,并在任一帧所述语音信号特征完成线性插值缩放之后,返回到各个所述语音信号特征各自的原始维度,所述缩放子模块,包括:
49、缩减子单元,用于在所述随机缩放比例大于0且小于1的情况下,对任一帧所述语音信号特征进行线性插值缩减,得到缩减后的语音信号特征;
50、补足子单元,用于获取所述缩减后的语音信号特征中的最后一维语音信号特征,并将所述最后一维语音信号特征加上随机数得到新的语音信号特征,以对所述缩减后的语音信号特征进行补足,直到所述缩减后的语音信号特征的维度达到所述原始维度。
51、可选地,所述根据所述随机缩放比例,对所述原始语音信号特征帧序列中的每一帧语音信号特征分别进行线性插值缩放,并在任一帧所述语音信号特征完成线性插值缩放之后,返回到各个所述语音信号特征各自的原始维度,所述缩放子模块,包括:
52、放大子单元,用于在所述随机缩放比例大于等于1的情况下,对任一帧所述语音信号特征中的所有维度的语音信号特征依次进行线性插值放大,得到放大后的语音信号特征,并将放大后的所述语音信号特征超出所述原始维度的部分进行删减,所述放大后的语音信号特征中包括原始语音信号特征和所述原始语音信号特征按照所述随机缩放比例放大后的语音信号特征。
53、可选地,所述对所述原始语音信号特征帧序列进行频谱缩放,并将所述频谱缩放后的原始语音信号特征帧序列、所述原始人脸特征参数帧序列以及所述原始视频文件的实际说话人标签组成一组训练数据,包括:
54、第二获取子模块,用于获取多个说话人的原始视频文件;
55、分解子模块,用于将各个所述说话人的原始视频文件分别分解成各个所述说话人的原始语音信号特征帧序列和原始人脸特征参数帧序列;
56、组成子模块,用于分别对各个所述说话人的原始语音信号特征帧序列进行频谱缩放,并将各个所述说话人的频谱缩放后的原始语音信号特征帧序列以及各自对应的原始人脸特征参数帧序列以及各自对应的实际说话人标签组成各个所述说话人的训练数据。
57、可选地,在得到目标人脸特征参数帧序列,所述方法还包括:
58、第三获取子模块,用于从预设视频模板中获取原始图像序列;
59、生成子模块,用于将所述目标人脸特征参数帧序列和所述原始图像序列输入预先训练好的人脸渲染模型,生成目标图像。
60、本技术实施例第三方面,提供了一种电子设备,包括存储器、处理器及存储在所述存储器上的计算机程序,所述处理器执行所述计算机程序以实现如本技术第一方面所述的人脸特征的生成方法。
61、本技术的有益效果:
62、本技术实施例提供了一种人脸特征的生成方法,所述方法包括:获取待识别的语音数据;将所述待识别的语音数据输入预先训练的目标人脸特征生成模型,得到目标人脸特征参数帧序列,其中,所述目标人脸特征生成模型通过如下步骤训练得到:获取原始语音信号特征帧序列和原始人脸特征参数帧序列,所述原始语音信号特征帧序列和所述原始人脸特征参数帧序列按照时间顺序对齐;对所述原始语音信号特征帧序列进行频谱缩放,并将所述频谱缩放后的原始语音信号特征帧序列、所述原始人脸特征参数帧序列以及所述原始视频文件的实际说话人标签组成一组训练数据;将一组所述训练数据输入到原始人脸特征生成模型,得到人脸特征损失函数值,以及在将一组所述训练数据输入到原始人脸特征生成模型之后,将所述原始人脸特征生成模型的预设中间层的输出结果输入到说话人对抗分类模块,得到目标分类损失函数值;将所述目标分类损失函数值与所述人脸特征损失函数值相加,得到目标损失函数值,并通过所述目标损失函数值更新所述原始人脸特征生成模型的模型参数,得到所述目标人脸特征生成模型。本技术在预先训练目标人脸特征生成模型时,对模型的训练数据增加一套损失函数,该函数通过梯度反转的底层方法,致力于故意让模型分不清楚谁是谁,也即消弭不同发音人的个人特色,同时,对训练数据进行随机增强,通过对训练数据中的音频做频谱的随机缩放,改变音频的发音人音色,促使模型在输入音色变化的情况下还能照旧输出原人脸特征参数,从而提高模型对输入变化的稳定性。通过本技术预先训练得到的目标识别模型,具有更好的泛化性和稳定性。
- 还没有人留言评论。精彩留言会获得点赞!