一种面向移动推荐的基于语义的联邦学习方法
本发明涉及移动推荐,特别涉及一种面向移动推荐的基于语义的联邦学习方法。
背景技术:
1、随着移动设备的广泛应用,移动推荐系统成为一个重要的研究领域。传统的移动推荐系统将用户的历史轨迹数据集中存储在中央服务器上,来训练一个高效的推荐模型。然而,用户的历史签到数据中包含了用户的隐私信息,例如用户的位置、社交关系以及职业等。这导致了极大的隐私泄露的风险。近年来,联邦学习已成为解决用户隐私和安全性问题的有效方法。mcmahan等人提出了fedavg,它允许多个客户端在不共享本地数据的情况下共同训练一个机器学习模型。duan等人提出了一个自平衡联邦学习框架astraea,通过数据扩展和多客户端的重新调度来缓解训练数据的局部和全局不平衡问题。
2、随着联邦学习的发展,移动推荐领域中的用户数据隐私和安全性问题也得到了关注。guo等人提出了一个针对兴趣点(points of interest,poi)推荐的边缘加速联邦学习框架prefer,它通过解耦推荐过程来保护用户隐私并提高模型的效率。huang et al.提出了一种地理poi推荐的联邦学习方法,通过构建地理信息矩阵来量化物联网中的位置信息,并将联邦学习引入到物联网环境中poi推荐的矩阵分解中来保护用户隐私。
3、然而,直接将通用的联邦学习方法应用到移动推荐系统中可能会导致推荐性能下降以及计算和通信过载等问题。一方面,在现有的联邦学习设置下,为保护用户隐私,客户端数据均存储在本地。这导致客户端本地数据之间相互孤立,并且客户端本地数据中的许多用户特征无法直接上传给服务器用于全局模型训练。一些上下文信息已经被利用来训练一个高效的移动推荐模型。然而,用户轨迹数据中丰富的语义知识尚未得到充分利用。另一方面,在联邦学习中,由于需要统筹所有客户端的计算和通信任务,服务器经常出现计算过载和通信受阻等问题。而在移动推荐场景中,客户端大多数是手机、平板或车载系统等移动终端。客户端不仅数量十分庞大,并且频繁的进行跨域的动态移动。这进一步加剧了服务器的计算和通信压力。
技术实现思路
1、针对现有技术存在的上述问题,本发明要解决的技术问题是:如何缓解联邦学习在移动推荐场景中存在的模型性能下降以及计算和通信过载的问题。
2、为解决上述技术问题,本发明采用如下技术方案:一种面向移动推荐的基于语义的联邦学习方法,包括如下步骤:
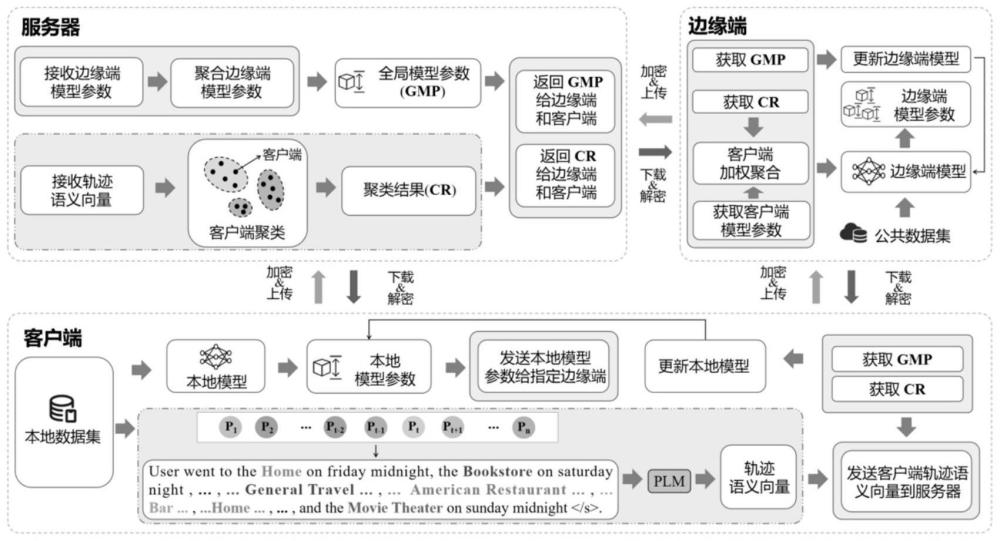
3、s1:客户端使用本地数据训练本地模型,得到训练后的本地模型参数,同时客户端根据本地数据计算本地轨迹语义向量,本地训练结束后,客户端首先将本地轨迹语义向量加密上传至服务器。
4、s2:服务器利用解密得到的客户端语义向量,并且基于相似度聚类对客户端近进行聚类,得到聚类结果,根据聚类结果,客户端将训练后的本地模型参数加密上传给指定边缘端。
5、s3:边缘端接收并解密得到训练后的本地模型参数后,对训练后的本地模型参数进行聚合,并将聚合后的模型参数加载到边缘端模型上,然后边缘端使用公共数据集对边缘端模型进行训练,得到训练后的边缘端模型参数,每个边缘端将训练后的模型参数加密上传。
6、s4:服务器对边缘端训练后的模型参数解密并进行全局聚合,得到全局模型参数,服务器向所有客户端和边缘端广播全局模型参数。
7、s5:判断是否达到预设迭代次数,如果没有达到则返回s1,否则结束。
8、作为优选,所述s1中训练本地模型得到训练后的本地模型参数的步骤包括:
9、客户端会接收来自服务器的全局模型参数,并初始化客户端ci的本地模型参数,客户端使用本地数据集进行本地训练:
10、
11、其中,表示客户端ci训练后的本地模型参数,是客户端ci的本地模型参数,η是学习率,nh表示轨迹点的数量,xi和yi分别是第i个用户的轨迹数据和标签,表示的梯度,是交叉熵损失。表示在模型参数为时的本地模型的输出函数,λ是正则化因子。
12、作为优选,所述s1中计算本地轨迹语义向量的步骤包括:
13、使用prompt工程将用户的轨迹数据重构为文本即提示句子:将一天划分为五个时段,分别为midnight,early morning,noon,aftemoon和night。
14、制作了一个文本模板,并填充输入插槽,template=“user went to the[]on[][],the[]on[][],...,and the[]on[][]”。然后,生成客户端ci的prompt文本即提示句子
15、
16、其中,表示输入的轨迹序列,fprompt(·)是一个带有插槽的模板句子,中的轨迹点将被填充在相应的插槽中。
17、使用微调过的预训练语言模型来学习提示句子的语义特征表示:
18、
19、其中,fptm(·)是经过微调后的预训练语言模型,表示微调后的预训练语言模型的参数。表示ptm输出的表示向量,即客户端ci的轨迹语义向量,其中,b是batch size,sl是序列长度,d是ptm的输出特征维度,r是实数集。
20、作为优选,所述s1中得到微调过的预训练语言模型的步骤如下:
21、对于公共数据集中用户ui的轨迹使用公式(1)将其重构为自然语言句子将ec定义为语义地点类别,用于存储轨迹中的语义信息,nc表示地点类别数,d是维度。将轨迹中最后一个轨迹点的地点类别作为标签,表示为lablec。然后,计算地点类别分布:
22、
23、
24、其中,disc表示地点类别分布,fce(·)表示交叉熵损失函数。
25、在地点类别集中为每个轨迹随机选择一些不同于lablec的地点类别,作为负样本negc。对于负样本negc,计算其地点类别分布:
26、
27、
28、其中,表示负样本的地点类别分布,nneg是负样本的个数,fbce(·)表示二值交叉熵损失函数,oc是与形状相同的全零张量。
29、最后通过最小化训练数据的目标函数来学习参数,目标函数为得到微调后的预训练语言模型的参数
30、作为优选,所述s1-s4加密和解密的过程如下:
31、
32、ct=gptrn mod n2 (9)
33、
34、其中,pt表示明文,ct表示密文,g表示随机生成的公共参数,r为随机生成的数。n是随机选择的两个质数p和q的乘积,即n=p×q,用mod表示模量运算,l(·)表示函数,没有具体的含义,x表示函数的输入。
35、作为优选,所述s2中服务器基于相似度聚类对客户端近进行聚类的步骤如下:
36、利用轨迹语义向量之间的距离来衡量客户端之间的语义相似度:
37、
38、其中,表示客户端ci和客户端cj的轨迹语义向量和之间的相似度,sqrt(x)是求x的平方根操作,是计算和的乘积。
39、然后,服务器利用客户端之间的语义相似度,将客户端聚为k个簇:
40、
41、
42、其中,cluk表示第k个簇,表示cluk内的客户端语义向量的均值,即簇中心,nk表示cluk内的客户端个数,表示和之间的距离的平方。
43、作为优选,所述s3中对训练后的本地模型参数进行聚合的步骤包括:
44、
45、其中,表示边缘端ei聚合后的模型参数。
46、作为优选,所述s4中得到全局模型参数的步骤包括:
47、
48、其中,θg表示全局模型参数,ne表示边缘端的个数,表示边缘端ei训练后的模型参数。
49、相对于现有技术,本发明至少具有如下优点:
50、1.在sfl中,设计了一种基于语义的优化策略来提高推荐模型的性能。语义本身不包含用户的隐私信息,并且语义知识的学习过程是不可逆的,很好的满足了隐私保护的要求。为了减轻服务器的计算和通信压力,使用“客户端-边缘端-服务器”的三层架构。引入多个边缘设备来分担服务器的部分计算和通信任务,并为语义优化提供了可用的计算和通信资源。
51、2.在sfl中,设计了一种基于语义的优化策略。利用用户轨迹中丰富的语义知识指导服务器聚类客户端以挖掘客户端的共有特征,从而提升边缘模型的聚合效果,来训练一个高效的移动推荐模型。
52、3.实验结果表明,sfl的全局模型性能优于现有的几个强基线。还进一步分析了sfl在服务器性能提升速率、客户端性能以及计算和通信效率等方面的优势。
- 还没有人留言评论。精彩留言会获得点赞!