基于上下文语义的跨平台二进制函数命名预测方法
本发明涉及二进制函数命名预测,更具体地说是涉及一种基于上下文语义的跨平台二进制函数命名预测方法。
背景技术:
1、在计算机安全领域中,二进制函数命名是提高代码可读性、帮助逆向工程师理解代码结构和语义、以及进行恶意代码检测和分析的重要任务。然而,由于调试信息被移除或剥离,二进制文件通常没有函数名和变量名等标识信息。目前存在自动分析工具,但由于代码混淆、变更和缺少调试符号等原因,二进制函数命名仍然具有挑战性。因此,针对给定的二进制函数生成准确和相关的函数名是一项关键任务。
2、其面临的任务是将二进制代码转化为自然语言,可以被视为翻译任务。尽管这个任务与之前的代码语义分析任务在宏观上相似,例如alon u等人提出的code2vec模型、rohan bavishi等人提出的context2name模型和miltiadis allamanis等人提出的neuralcontext model ofcode模型,这些工作都是基于源代码的函数名预测。但由于二进制文件的特殊性质,这个任务面临的挑战也是不同的,具体为:
3、挑战1:语义信息不足。为了更加明确代码的语义,方便程序分析、优化和翻译,并避免硬件平台的限制,通常将二进制代码提升至中间语言进行分析,部分汇编代码序列如图1(a)所示。这些汇编指令用助记符表示,比如cpy、subs、bne等等,后面跟着寄存器名或数字常量。然而,这些指令缺乏开发人员在源代码中定义的变量类型或名称的相关信息,例如r1和r8等寄存器的含义是不清楚的。同时,数字常量0x4和0x0等也可能代表不同的含义。因此,从低级别的、缺乏语义信息的汇编指令序列学习如何为函数命名是一个挑战性的任务。
4、挑战2:函数名称标签缺失。通常可以通过多个标签来描述函数的不同方面,如输入输出、算法、数据结构等。通过使用多个标签,可以更全面地描述函数的语义,从而提高代码的易维护性。然而,在实际的软件开发和工程实践中,例如linux内核的编码规范kernelcoding style中命名规范部分建议函数名通常不超过30个字符,因此函数名通常采用简写或缩写的形式,保证能够准确描述函数的功能。但是,缺失标签可能会导致函数的重要特点未被正确描述,从而导致该函数语义不完整或不准确。例如:某个函数实现了一个数据排序的算法,并且使用了快速排序和归并排序两种不同的排序方法,该函数可以被标记为{sort,quicksort,mergesort,list}来描述其功能和算法特点。然而,由于命名规范的限制,可能只能使用一个较为简短的函数名,如sort_data。但是缺失的标签{quicksort,mergesort}导致该函数语义不完整,从而影响代码的可读性和可维护性。因此,如何平衡函数标签化和命名规范非常关键,以确保代码的语义准确、全面,同时不牺牲代码可读性和可维护性。
5、现存方法:2020年,david y提出nero,利用llvm ir作为中间表示语言进行分析,由于汇编代码没有明确的类型信息,参数通常以寄存器或栈的形式传递,缺乏类型信息导致无法确定寄存器或栈中存储的数据类型,从而无法准确地确定函数参数的数量,因此可能会导致函数参数个数的解析错误。如图1(b)中,retdec工具反汇编生成部分llvm ir,在解析库函数strlen(const char*str)时,对于参数个数解析出现错误,从而导致函数功能描述不准确。2021年,patrick-evans j提出xfl,xfl将函数名拆分为标记,利用极端多标签学习(extreme multi-label learning,简称xml)选择相关的函数标签,由于缺乏对变量类型和含义的考虑,可能导致代码的语义不完整。
6、因此,如何解决现有技术中由于二进制函数缺乏高级语义信息描述,使得逆向工程师难以准确理解函数的功能以及现有的二进制函数命名方案中,一个函数命名标签仅对应一个样本,导致一些不常见的函数命名标签存在长尾效应,影响基于机器学习的预测模型的性能的问题是本领域技术人员亟需解决的问题。
技术实现思路
1、有鉴于此,本发明提供了一种基于上下文语义的跨平台二进制函数命名预测方法,解决了上述问题。
2、一种基于上下文语义的跨平台二进制函数命名预测方法,具体步骤为:
3、获取任一二进制文件,利用反汇编工具抽取任一二进制文件中的二进制函数;
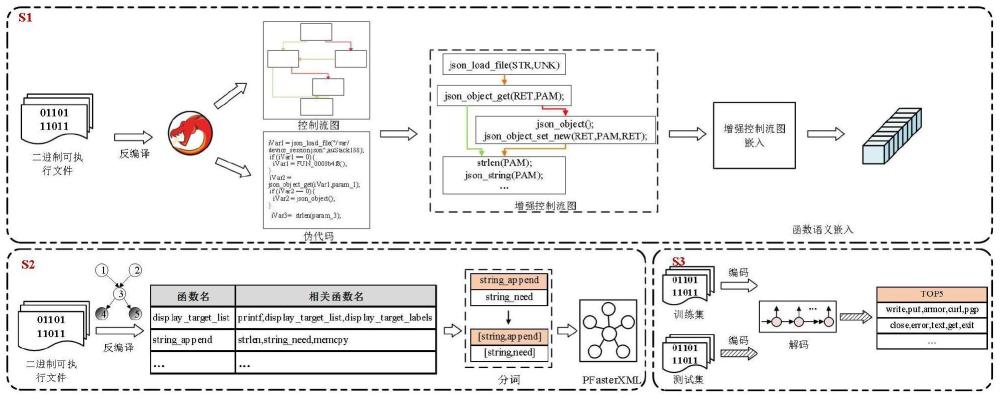
4、基于二进制函数利用反汇编法和反编译法进行分析,构建api控制流关联图;
5、对api调用函数的参数进行追踪,以完善参数信息并生成增强api调用语句;
6、遍历api控制流关联图的节点,删除不包含增强api调用语句的节点,生成增强控制流图;
7、提取二进制函数上下文信息;
8、基于二进制函数上下文信息,生成二进制函数名相关标签;
9、将二进制函数名相关标签与增强控制流图建立对应关系;
10、获取待预测二进制函数的增强控制流图,并利用图卷积神经网络模型预测二进制函数的相关名称。
11、可选的,生成api控制流关联图的具体步骤为:
12、步骤21、利用反汇编法分析任一二进制函数形成cfg,并记录每个基本块的开始地址和结束地址;
13、步骤22、利用反编译法分析该任一二进制函数,形成伪代码序列,并记录api调用语句的调用地址;
14、步骤23、根据api调用语句的调用地址,对比基本块的开始地址和结束地址,建立对应关系,生成api控制流关联图。
15、可选的,生成增强api调用语句的具体步骤为:
16、步骤31、遍历api调用语句的参数,将参数定义为p;判断参数p的值是否为具体值或全局变量,若否,则对参数p进行追踪,跳转到步骤32;
17、步骤32、获取api调用语句之前所有引用参数p的伪代码语句序列,并标记为stat;
18、步骤33、对序列集stat中包含的语句stati逐句进行分析,若stati不包含赋值操作,则判定stati是关于参数p的引用操作,执行stati+1;若包含赋值操作,将赋值语句左边的变量定义为t,右边定义为s,跳转到步骤34;
19、步骤34、根据预先设立的定义规则,对参数p进行变量类别定义;
20、步骤35、判断api调用语句的参数是否遍历完毕,若是,将api名、参数值、参数变量类别拼接生成增强api调用语句;若否,则跳转到步骤31。
21、可选的,增强控制流图ecfg的生成的具体步骤为:
22、步骤41、将api控制流关联图的节点进行广度优先遍历,判断节点n是否包含包增强api调用语句,若否,则跳转到步骤42;若是,则跳转到步骤41;
23、步骤42、将节点n的前驱节点定义为np,后继节点定义为nc;当存在节点nc时,将节点nc作为节点np的直接后继,并删除节点n;当不存在节点nc,直接删除节点n;
24、步骤43、判断api控制流关联图是否遍历完毕,若是,则停止,生成增强控制流图ecfg;若否,则跳转到步骤41。
25、可选的,提取二进制函数上下文信息的具体步骤为:
26、将需要提取上下文的二进制函数定义为f,并将二进制函数上下文信息定义为c,其中,c+为二进制函数f的调用者的集合,包含了调用函数f的函数;c-为二进制函数f所调用的函数的集合,包含了函数f调用的函数。
27、可选的,基于二进制函数上下文信息,生成二进制函数名相关标签的具体步骤为:
28、步骤61、遍历二进制函数上下文信息的函数名称,根据函数名称的特征选择策略进行切分,获得标记集合;
29、步骤62、基于标记集合训练pfastrexml模型;
30、步骤63、将函数名称作为pfastrexm模型的输入,利用pfastrexml模型生成函数名的相关标签rl。
31、可选的,将二进制函数名相关标签与增强控制流图建立对应关系的具体步骤为:
32、步骤71、获取二进制函数f的增强控制流图ecfg和二进制函数f的函数名相关标签rl;
33、步骤72、将函数名相关标签rl与增强控制流图ecfg组合,形成rl|ecfg,建立对应关系。
34、可选的,根据函数名的特征选择策略进行切分,策略包括:剥离编译器增加的特殊修饰符、函数名统一大小写、分离常见函数命名规则、对较长字符序列进行分割、纠错修订、数字剥离。
35、可选的,pfastrexml模型中使用倾向性得分表征标签的稀缺性,倾向性计算公式为:
36、
37、式中,a、b、c均为常数,nl是标签l在观测数据集中出现的次,n是观察数据集的大小;倾向性得分pl是作为分母存在,pl越大,表明标签l的重要性越低,标签越不容易被遗漏。通过这种方式,提升了不常见的尾部边缘标签的重要性。
38、经由上述的技术方案可知,与现有技术相比,本发明公开了一种基于上下文语义的跨平台二进制函数命名预测方法,基于伪代码作为中间语言进行分析,使用增强控制流图代表函数的语义对函数名预测了改善模型的性能;并且基于函数名上下文信息,使用多标签学习的思想丰富函数的语义信息,更加全面的描述函数的功能,从而提高代码的易维护性。
- 还没有人留言评论。精彩留言会获得点赞!