基于非完全子树核的命令聚类方法、装置、介质和设备与流程
本发明涉及计算机,尤其涉及基于非完全子树核的命令聚类方法、装置、介质和设备。
背景技术:
1、云计算场景下,云控制平台通常会将云主机运行的行为日志进行收集,这些日志大部分用来记录云主机所运行的命令,例如bash命令,以监控云主机的行为。云主机的所记录的bash命令数量通常十分庞大,这使得日志分析工作需要耗费巨大的人力成本和时间成本。对bash命令进行聚类可以对相似的云主机行为进行归类,使得实现云主机行为监控所需要处理的bash命令数量大幅降低。
2、传统的聚类方式将日志当成普通的文本,构建日志词表,使用向量空间模型对日志和命令进行数字化表示,然后应用机器学习或深度学习中的聚类模型对bash命令进行聚类。然而,bash命令是一种具有语法结构的数据,传统的方式不能考虑到bash命令的语法规则。
技术实现思路
1、有鉴于此,本发明实施例的目的在于提供一种基于非完全子树核的命令聚类方法、装置、介质和设备,以解决传统的聚类方式中不能考虑到命令的语法规则的技术问题。
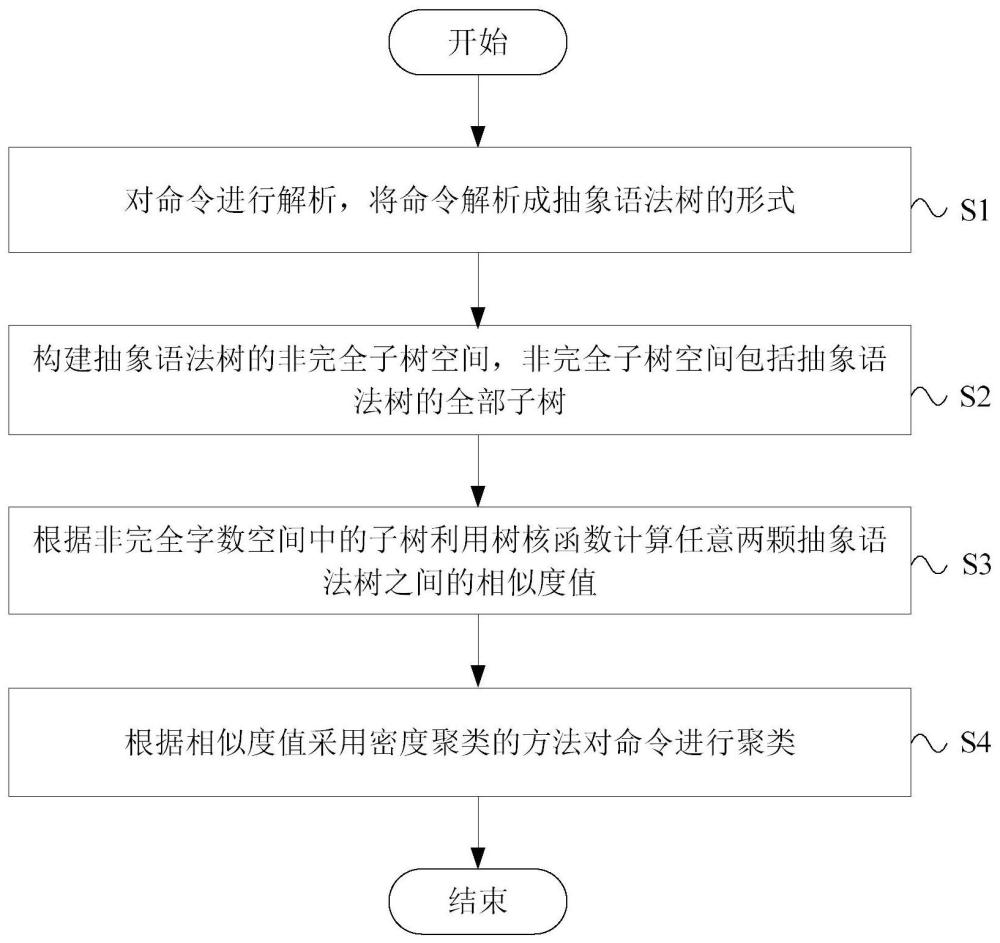
2、为了达到上述目的,第一方面,本发明实施例提供了一种基于非完全子树核的命令聚类方法,所述方法包括:
3、对命令进行解析,将所述命令解析成抽象语法树的形式;
4、构建所述抽象语法树的非完全子树空间,所述非完全子树空间包括所述抽象语法树的全部子树;
5、根据所述非完全子树空间中的子树利用树核函数计算任意两颗抽象语法树之间的相似度值;
6、根据所述相似度值采用密度聚类的方法对所述命令进行聚类。
7、在一些可能的实施方式中,根据所述非完全子树空间中的子树利用树核函数计算任意两颗抽象语法树之间的相似度值,具体包括:
8、通过如下公式计算任意两颗抽象语法树之间的相似度值:
9、
10、其中,t1是第一颗抽象语法树,t2是第二颗抽象语法树,subt1表示第一颗抽象语法树t1的非完全子树空间,subt2表示第二颗抽象语法树t2的非完全子树空间,n1是第一颗抽象语法树t1的非完全子树空间中的子树,n2是第二颗抽象语法树t2的非完全子树空间的子树,△函数是树核函数,tk是第一颗抽象语法树t1和第二颗抽象语法树t2之间的相似度值。
11、在一些可能的实施方式中,所述的根据所述相似度值采用密度聚类的方法对所述命令进行聚类,具体包括:
12、获取预设的第一阈值参数ε和第二阈值参数minpts,其中,所述第一阈值参数ε是一个半径参数,用于定义邻域的大小,所述第二阈值参数minpts是一个用于定义核心数据点的邻域内最小数据点数量的参数;
13、根据所述第一阈值参数ε和所述第二阈值参数minpts确定所述非完全子树空间的集合中的核心数据点;
14、根据所述相似度值确定每个所述核心数据点与所述核心数据点在ε邻域内密度可达的点,将所述核心数据点与所述核心数据点对应的密度可达的点合并到同一个簇中。
15、在一些可能的实施方式中,所述的根据第一阈值参数ε和所述第二阈值参数minpts确定所述非完全子树空间的集合中的核心数据点,具体包括:
16、当所述非完全子树空间的集合中的数据点在所述ε邻域包括至少minpts个数据点时,将所述数据点确定为核心数据点。
17、在一些可能的实施方式中,所述的根据所述相似度值确定每个所述核心数据点与所述核心数据点在ε邻域内密度可达的点,具体包括:
18、将所述相似度值与所述第一阈值参数ε进行比较,并将所述相似度值小于所述第一阈值参数ε的数据点确定为密度可达的点。
19、第二方面,本发明实施例提供了一种基于非完全子树核的命令聚类装置,所述装置包括:
20、抽象语命令解析模块,用于对命令进行解析,将所述命令解析成抽象语法树的形式;
21、构建模块,用于构建所述抽象语法树的非完全子树空间,所述非完全子树空间包括所述抽象语法树的全部子树;
22、计算模块,用于根据所述非完全子树空间中的子树利用树核函数计算任意两颗抽象语法树之间的相似度值;
23、聚类模块,用于根据所述相似度值采用密度聚类的方法对所述命令进行聚类。
24、在一些可能的实施方式中,所述计算模块具体用于:
25、通过如下公式计算任意两颗抽象语法树之间的相似度值:
26、
27、其中,t1是第一颗抽象语法树,t2是第二颗抽象语法树,subt1表示第一颗抽象语法树t1的非完全子树空间,subt2表示第二颗抽象语法树t2的非完全子树空间,n1是第一颗抽象语法树t1的非完全子树空间中的子树,n2是第二颗抽象语法树t2的非完全子树空间的子树,△函数是树核函数,tk是第一颗抽象语法树t1和第二颗抽象语法树t2之间的相似度值。
28、在一些可能的实施方式中,所述聚类模块包括:
29、获取子模块,用于获取预设的第一阈值参数ε和第二阈值参数minpts,其中,所述第一阈值参数ε是一个半径参数,用于定义邻域的大小,所述第二阈值参数minpts是一个用于定义核心数据点的邻域内最小数据点数量的参数;
30、确定子模块,用于根据所述第一阈值参数ε和所述第二阈值参数minpts确定所述非完全子树空间的集合中的核心数据点;
31、确定与合并子模块,用于根据所述相似度值确定每个所述核心数据点与所述核心数据点在ε邻域内密度可达的点,将所述核心点与所述核心点对应的密度可达的点合并到同一个簇中;其中,
32、所述确定子模块具体用于当所述非完全子树空间的集合中的数据点在所述ε邻域包括至少minpts个数据点时,将所述数据点确定为核心数据点;
33、所述确定与合并子模块具体用于将所述相似度值与所述第一阈值参数ε进行比较,将所述相似度值小于所述第一阈值参数ε的数据点确定为密度可达的点。
34、第三方面,本发明实施例提供了一种计算机可读存储介质,其上存储有计算机程序,该程序被处理器执行时实现所述的一种基于非完全子树核的命令聚类方法。
35、第四方面,本发明实施例提供了一种电子设备,其包括:
36、处理器;
37、用于存储所述处理器可执行指令的存储器;
38、其中,所述处理器被配置为执行所述指令,以实现所述的一种基于非完全子树核的命令聚类方法。
39、上述技术方案具有如下有益效果:
40、本发明提供了一种基于非完全子树核的命令聚类方法、装置、介质和设备,该方法包括:对命令进行解析,将所述命令解析成抽象语法树的形式;构建所述抽象语法树的非完全子树空间,所述非完全子树空间包括所有所述抽象语法树的子树;根据所述非完全子树空间中的子树利用树核函数计算任意两颗抽象语法树之间的相似度值;根据所述相似度值采用密度聚类的方法对所述命令进行聚类。本发明实施例提供的一种基于非完全子树核方法的命令聚类技术,将命令解析成抽象语法树,并使用非完全子树核方法对抽象语法树进行相似度计算,使命令蕴含的语法规则能够被聚类模型所考虑在内,从而显著提高命令的聚类效果。
- 还没有人留言评论。精彩留言会获得点赞!