一种基于多通道模型的口语理解联合方法及口语理解系统
本发明属于智能口语理解和对话系统领域,特别是涉及一种基于多通道模型的口语理解方法及口语理解系统。
背景技术:
1、对话系统是自然语言处理领域中重要的研究方向之一,它为生活带来便利,同时也节约了人力物力成本。口语理解模块作为对话系统的关键上游任务,它有着影响对话系统整体性能好坏的作用。口语理解中的两项关键任务是意图识别和槽位填充,为了让机器能更好理解用户的语言,向用户反馈正确的信息,意图识别和槽位填充两个子任务是人机对话系统构成的重点。
2、在早期,意图识别与槽位填充这两项任务分别进行独立建模训练。意图识别的目的是通过用户的输入语句来了解用户当前的需求,它是一种文本分类任务,旨在从用户的话语中提取出其所表达的意图和行为。意图识别任务通常使用以下几种方法:基于规则模板的方法、基于统计特征的机器学习方法以及基于深度学习的方法。槽位填充被定义为序列标注任务进行处理,从用户输入的语句里找到每个字或者词对应的语义槽位相关标签。槽位填充任务的解决方法可以分为四种:基于字典的方法、基于规则的方法、基于统计的方法和基于深度学习的方法。
3、但在口语理解任务中常常存在用户输入对话句子较简短、句子语义表达不明确或者有歧义等问题,使得独立建模训练的两项任务效果并不理想。随着深度学习的深入发展,这两项任务渐渐被用来进行联合建模训练,从而相互促进提高这两项任务的性能。研究者们认为将两个模型进行联合训练时,两个模型的结果是正向且相互促进,利用两个任务之间的相关性来提高总体训练的准确率,相比起两项任务的单独建模方法来说,联合训练方法取得的实验效果更好。
技术实现思路
1、本发明的目的是提供一种基于多通道模型的口语理解联合方法及口语理解系统,以解决上述现有技术存在的问题。
2、为实现上述目的,本发明提供了一种基于多通道模型的口语理解联合方法,包括:
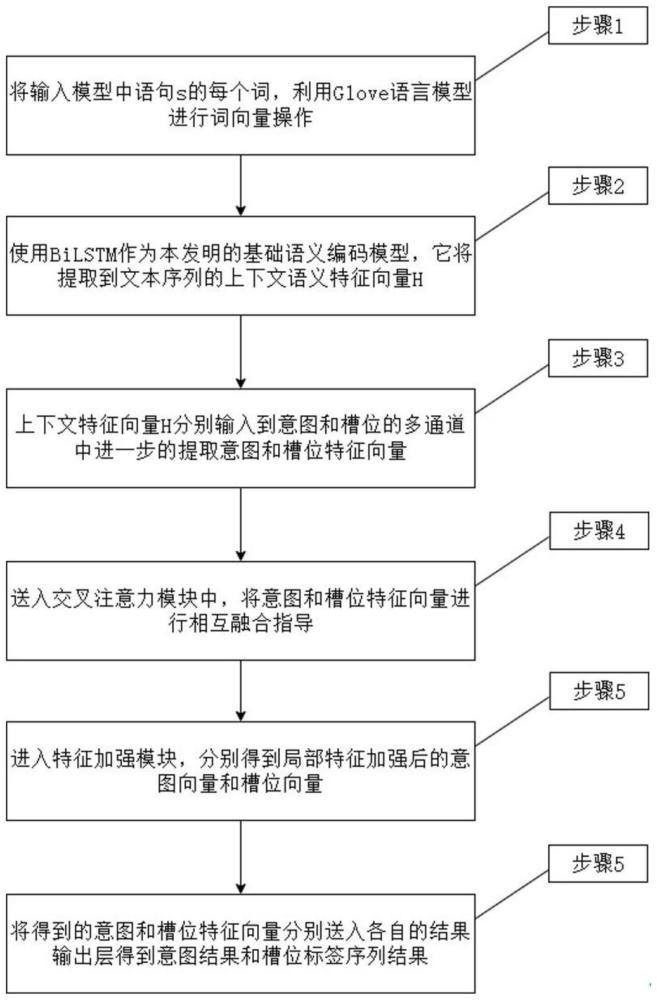
3、获取用户输入语句,通过对所述用户输入语句进行词向量操作,获得词向量矩阵;
4、构建基础语义编码模型,将所述词向量矩阵输入至所述基础语义编码模型,获得上下文语义特征向量;
5、将所述上下文语义特征向量分别通过意图多通道和槽位多通道进行进一步特征提取,按照预设规则将特征提取结果进行融合,获得融合意向向量和融合槽位向量;
6、基于交叉注意力机制将所述融合意向向量和融合槽位向量融合,将融合后的向量处理后进行局部特征加强操作,获得局部加强意图向量和局部加强槽位向量;
7、基于局部加强意图向量获得意图识别结果,基于局部加强槽位向量获得槽位序列标签结果,完成口语理解联合训练。
8、可选的,所述基础语义编码模型选取bilstm,包括两个lstm层,通过两个lstm层将输入的词向量矩阵进行前向编码和后向编码,获得所述上下文语义特征向量。
9、可选的,所述意图多通道与槽位多通道包括多尺度卷积网络通道、注意力机制通道;其中,所述多尺度卷积网络通道包括多尺度卷积核、relu激活函数及最大池化层。
10、可选的,所述预设规则包括采用求和平均的融合方法,将意图多通道和槽位多通道的特征提取结果分别进行融合,获得融合意向向量和融合槽位向量。
11、可选的,特征提取的过程包括:将所述上下文语义特征向量输入至所述多尺度卷积网络通道,获得意向局部特征向量和槽位局部特征向量;将所述上下文语义特征向量输入至所述注意力机制通道,获得意图注意力向量和槽位注意力向量。
12、可选的,基于交叉注意力机制将所述融合意向向量和融合槽位向量融合的过程包括:基于交叉注意力机制将融合槽位向量的槽位信息与所述融合意向向量融合后与融合意向向量进行残差连接,送入正则化层,获得交叉意向向量;将所述融合意向向量的意图信息与所述融合槽位向量融合后与融合槽位向量进行残差连接,送入正则化层,获得交叉槽位向量。
13、可选的,获得局部加强意图向量和局部加强槽位向量的过程包括:将所述交叉意向向量与所述交叉槽位向量进行拼接后,通过激活函数、全连接层与正则化层获得意图特征向量与槽位特征向量,将意图特征向量与槽位特征向量通过局部特征加强获得局部加强意图向量和局部加强槽位向量。
14、可选的,将所述局部加强意图向量与上下文语义特征向量做残差连接再输入最大池化层、全连接层和softmax函数,得到意图识别结果;将所述局部加强槽位向量与上下文语义特征向量做残差连接再经过全连接层、序列标注得出槽位序列标签结果。
15、本发明还提供一种基于多通道模型的口语理解系统,包括:
16、模型调用模块、口语理解模块、结果输出模块;
17、所述模型调用模块调用用户选择的模型进行口语理解任务;
18、所述口语理解模块用于对用户输入语句进行分析,通过所述结果输出模块返回用户输入语句的意图识别结果和槽位序列标签结果并予以显示。
19、可选的,所述口语理解模块包括语句获取模块、预处理模块、语义特征提取模块、融合模块、交叉注意力模块、特征加强模块、识别模块;
20、所述语句获取模块用于获取用户输入语句;
21、所述预处理模块用于获得所述用户输入语句对应的词向量矩阵;
22、所述语义特征提取模块用于根据所述词向量矩阵获得上下文语义特征向量;
23、所述融合模块用于对所述上下文语义特征向量进行进一步特征提取,获得融合意向向量和融合槽位向量;
24、所述交叉注意力模块用于将融合意向向量和融合槽位向量进行相互融合,获得交叉意向向量和交叉槽位向量;
25、所述特征加强模块用于根据交叉意向向量和交叉槽位向量获得局部加强意图向量和局部加强槽位向量;
26、所述识别模块将局部加强意图向量和局部加强槽位向量分别送入各自的结果输出层得到意图结果和槽位标签序列结果。
27、本发明的技术效果为:
28、本发明利用多尺度卷积网络和注意力机制组成多通道对句子进行深度提取,为后面的意图槽位特征交互层和特征加强层提供表征能力更强的意图特征向量和槽位特征向量,使用交叉注意力机制融合意图信息和槽位信息,并将融合后的向量做局部特征加强操作,能有效地提升意图识别和槽位填充这两项任务的结果。本发明建立意图识别和槽位填充的显示训练连接,使得两个任务能相互正向指导对方,使得槽位信息能指导意图识别任务,意图信息能指导槽位填充任务,从而提高这两项任务联合训练的总体性能,进一步提高了口语理解联合模型的性能。
技术特征:
1.一种基于多通道模型的口语理解联合方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于多通道模型的口语理解联合方法,其特征在于,
3.根据权利要求1所述的基于多通道模型的口语理解联合方法,其特征在于,
4.根据权利要求3所述的基于多通道模型的口语理解联合方法,其特征在于,
5.根据权利要求3所述的基于多通道模型的口语理解联合方法,其特征在于,
6.根据权利要求1所述的基于多通道模型的口语理解联合方法,其特征在于,
7.根据权利要求6所述的基于多通道模型的口语理解联合方法,其特征在于,
8.根据权利要求1所述的基于多通道模型的口语理解联合方法,其特征在于,
9.一种基于权利要求1-8任一项所述的基于多通道模型的口语理解联合方法的口语理解系统,其特征在于,
10.根据权利要求9所述的口语理解系统,其特征在于,
技术总结
本发明公开了一种基于多通道模型的口语理解联合方法及口语理解系统,包括:获取用户输入语句并进行词向量操作,获得词向量矩阵;将词向量矩阵输入至基础语义编码模型,获得上下文语义特征向量,并通过意图多通道和槽位多通道分别进行进一步特征提取,基于预设规则获得融合意向向量和融合槽位向量;基于交叉注意力机制将融合意向向量和融合槽位向量融合并进行处理后,进行局部特征加强操作,获得局部加强意图向量和局部加强槽位向量;基于局部加强意图向量与局部加强槽位向量获得结果,完成口语理解。本发明中意图和槽位任务之间建立显式连接的方法更利于联合模型的训练,进一步提高了口语理解联合模型的性能。
技术研发人员:杨力,白思畅,李国树,宋欣渝
受保护的技术使用者:西南石油大学
技术研发日:
技术公布日:2024/2/21
- 还没有人留言评论。精彩留言会获得点赞!