用于数据挖掘的可配置算子处理方法及装置与流程
本发明涉及大数据与算子开发,尤指一种用于数据挖掘的可配置算子处理方法及装置。
背景技术:
1、本部分旨在为权利要求书中陈述的本发明实施例提供背景或上下文。此处的描述不因为包括在本部分中就承认是现有技术。
2、在大数据领域进行海量数据计算业界比较成熟的方案一般是选用spark作为底层计算引擎。在数据挖掘领域,业务人员经常需要对海量数据进行清洗、分析、加工。而这类业务人员一般是数据分析师岗,对企业的业务数据含义等很熟悉,但不具备专业的编程能力。所以很难要求他们能通过sparksql或spark rdd的api接口实现如上的数据清洗、加工需求。
3、目前常用的一种方式是将spark的基本能力封装成特定算子,通过参数化配置的方式来实现不同的加工操作。数据分析师基于多种算子就能快速地探索出一套数据加工的方案。当需要支持新的计算逻辑时,就会针对性的开发出一个独立的算子来支撑该逻辑,因此,更新算子是一个相对频繁的操作。
4、在算子开发场景中,当需要新增一种新算子时,当前普遍的做法是由产品经理或需求方梳理出该算子需要支持的配置化参数及算子的整体ui界面,再由前后端工程师协商确定接受算子参数的接口,然后前端工程师需要根据该参数及ui开发该算子特定的界面,后端需要对算子做参数解析及代码转换。这过程中,若由于需求有所变动导致参数增减或ui调整,前端工程师都需要重新做开发,并与后端工程师重新沟通接口协议。实践过程中,经常会出现开发一个算子比较耗时的情况。这主要是两个原因导致:一是对需求变更的响应需要前后端工程师都进行开发投入;二是调试过程中,经常由于参数变更导致前后端接口更新不及时,无法正确解析参数。
5、综上来看,亟需一种可以克服上述缺陷,能够对于算子的需求变更及调试改进处理效率,降低开发成本的技术方案。
技术实现思路
1、为解决现有技术存在的问题,本发明提出了一种用于数据挖掘的可配置算子处理方法及装置。本发明能够灵活设计算子配置模板,可以兼容各种常用的算子类型,且支持前端根据模板进行渲染及生产参数解析接口,本发明可以减轻增加算子的工作量,通过自动化生成前端代码与后端代码的方式,降低新增算子的改造成本,有效提高开发效率。
2、在本发明实施例的第一方面,提出了一种用于数据挖掘的可配置算子处理方法,该方法包括:
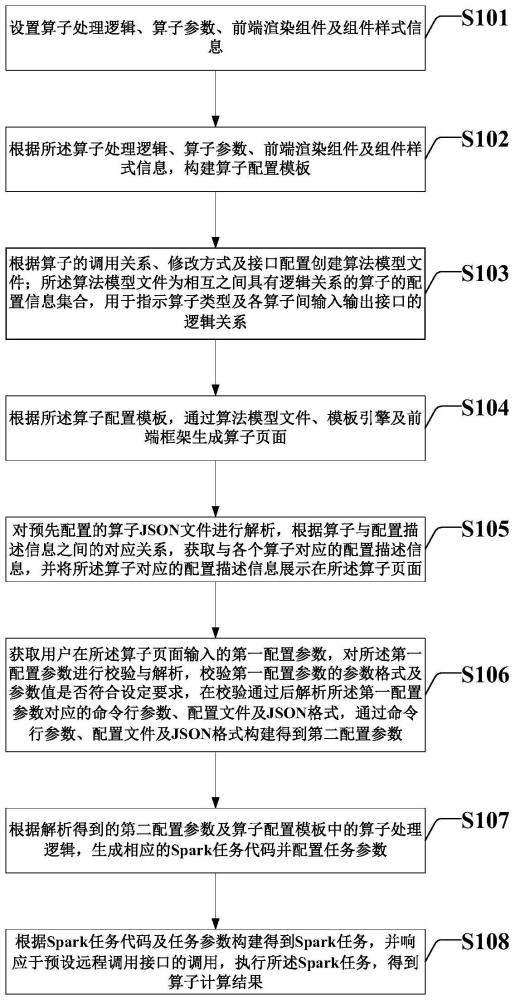
3、设置算子处理逻辑、算子参数、前端渲染组件及组件样式信息;
4、根据所述算子处理逻辑、算子参数、前端渲染组件及组件样式信息,构建算子配置模板;
5、根据算子的调用关系、修改方式及接口配置创建算法模型文件;所述算法模型文件为相互之间具有逻辑关系的算子的配置信息集合,用于指示算子类型及各算子间输入输出接口的逻辑关系;
6、根据所述算子配置模板,通过算法模型文件、模板引擎及前端框架生成算子页面;
7、对预先配置的算子json文件进行解析,根据算子与配置描述信息之间的对应关系,获取与各个算子对应的配置描述信息,并将所述算子对应的配置描述信息展示在所述算子页面;
8、获取用户在所述算子页面输入的第一配置参数,对所述第一配置参数进行校验与解析,校验第一配置参数的参数格式及参数值是否符合设定要求,在校验通过后解析所述第一配置参数对应的命令行参数、配置文件及json格式,通过命令行参数、配置文件及json格式构建得到第二配置参数;
9、根据解析得到的第二配置参数及算子配置模板中的算子处理逻辑,生成相应的spark任务代码并配置任务参数;
10、根据spark任务代码及任务参数构建得到spark任务,并响应于预设远程调用接口的调用,执行所述spark任务,得到算子计算结果。
11、在本发明实施例的第二方面,提出了一种用于数据挖掘的可配置算子处理装置,该装置包括:
12、设置模块,用于设置算子处理逻辑、算子参数、前端渲染组件及组件样式信息;
13、算子配置模板模块,用于根据所述算子处理逻辑、算子参数、前端渲染组件及组件样式信息,构建算子配置模板;
14、算法模型文件构建模块,用于根据算子的调用关系、修改方式及接口配置创建算法模型文件;所述算法模型文件为相互之间具有逻辑关系的算子的配置信息集合,用于指示算子类型及各算子间输入输出接口的逻辑关系;
15、前端算子页面生成模块,用于根据所述算子配置模板,通过算法模型文件、模板引擎及前端框架生成算子页面;
16、配置描述信息处理模块,用于对预先配置的算子json文件进行解析,根据算子与配置描述信息之间的对应关系,获取与各个算子对应的配置描述信息,并将所述算子对应的配置描述信息展示在所述算子页面;
17、前端参数校验及解析模块,用于获取用户在所述算子页面输入的第一配置参数,对所述第一配置参数进行校验与解析,校验第一配置参数的参数格式及参数值是否符合设定要求,在校验通过后解析所述第一配置参数对应的命令行参数、配置文件及json格式,通过命令行参数、配置文件及json格式构建得到第二配置参数;
18、后端参数解析及代码生成模块,用于根据解析得到的第二配置参数及算子配置模板中的算子处理逻辑,生成相应的spark任务代码并配置任务参数;
19、任务构建及执行模块,用于根据spark任务代码及任务参数构建得到spark任务,并响应于预设远程调用接口的调用,执行所述spark任务,得到算子计算结果。
20、在本发明实施例的第三方面,提出了一种计算机设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述计算机程序时实现用于数据挖掘的可配置算子处理方法。
21、在本发明实施例的第四方面,提出了一种计算机可读存储介质,所述计算机可读存储介质存储有计算机程序,所述计算机程序被处理器执行时实现用于数据挖掘的可配置算子处理方法。
22、在本发明实施例的第五方面,提出了一种计算机程序产品,所述计算机程序产品包括计算机程序,所述计算机程序被处理器执行时实现用于数据挖掘的可配置算子处理方法。
23、相较于现有技术,本发明提出的用于数据挖掘的可配置算子处理方法及装置至少存在以下优点:
24、降低数据挖掘人员处理数据的门槛:通过配置化的算子管理方法,数据挖掘人员无需编写复杂数字代码,仅需在配置文件中添加新的配置节点,即可快开发出基于spark的可视化算子。这使得非专业的开发人员也能轻松上手,降低了处理数据的门槛。
25、提高开发效率:因为算子配置模板已经包含了算子的处理逻辑、参数、前端渲染的组件、组件样式等,前端和后端可以根据模板自动生成相应的页面、参数校验及解析方法、接收算子参数的解析方法、生成算子代码的模板等,节省了开发人员的时间和精力,提高了开发效率。
26、提高系统的灵活性和可扩展性:本发明采用配置化的算子管理方法,当需要增加新的算子时,只需在算子配置文件上增加新的配置节点,无需修改原有的代码,这大大提高了系统的灵活性和可扩展性。
27、优化用户体验:对于数据挖掘人员而言,根据算子模板自动生成的算子界面及参数校验和解析方法,使得他们可以专注于数据处理的业务逻辑而无需关心底层技术实现。这有助于提高工作效率,优化用户体验。
28、便于系统维护和更新:由于本发明采用了配置化的算子管理方法,当需要修改或更新算子时,只需修改相应的配置文件而无需改动底层。这样不仅降低了维护成本,还有利于系统的稳定性和可维护性。
- 还没有人留言评论。精彩留言会获得点赞!