一种考虑认知-物理约束的分心驾驶行为模拟方法及装置
本发明涉及交通流微观仿真技术与智能汽车测试技术的交叉领域,尤其是涉及一种考虑认知-物理约束的分心驾驶行为模拟方法及装置。
背景技术:
1、分心驾驶行为是道路上普遍存在的现象,高达15%-20%的驾驶员在驾驶时会分心。分心会导致交通流滞后、振荡等不稳定行为,是交通事故的主要原因之一。在美国,分心驾驶行为占交通事故的68.3%和死亡事故的9.7%。鉴于分心驾驶行为的危害,分析分心驾驶行为的形成并进行仿真具有非常重要的意义。在安全相关的研究中,分心驾驶行为模型能够再现仿真环境中的不稳定行为,可以深入研究安全问题。特别是分心驾驶行为模型可以模拟关键的碰撞前场景,可用于测试自动驾驶系统。这些场景有助于发现并解决紧急情况下分心驾驶导致的自动驾驶系统缺陷,在汽车行业可以改进一些先进的驾驶辅助系统,例如,可以通过考虑分心驾驶时的估计反应时间来改善预警时间。此外,通过分心驾驶行为模型可以来评估智能车辆的人机交互(human-machine interaction,hmi)设计在引导驾驶员注意力和触发干预时的性能。现有的分心驾驶行为建模主要关注分心过程中的物理约束,将人为因素相关的参数添加到交通流模型中,以模拟观察到的分心状态下的车辆轨迹。然而,现有的模型无法完全解释复杂的分心行为。首先,关于分心的来源及其对分心驾驶行为的影响研究较少,这限制了不同分心模式的模型精度;其次,模型中的驾驶员能够对刺激做出反应,无论刺激有多小,这与生理证据不一致;最后,目前的模型很难估计反应时间,这可能会在模拟分心驾驶行为时导致偏差。因此分心驾驶行为的建模还有很大的改进空间。
2、为了准确地模拟分心驾驶行为,除了物理约束之外,考虑驾驶员的认知约束也至关重要。许多生理学研究表明,分心中存在一些重要的认知约束,它们包括刺激的累积激活效应、注意力分配、反应时间和分心来源等。刺激的累积激活效应是指当刺激累积并超过一定阈值时,驾驶员对刺激做出反应。在分心驾驶中,由于驾驶员的注意力经常偏离道路,刺激的累积激活效应会降低。注意力分配是模型的一个重要特征。根据多元资源理论,驾驶员的认知能力是有限的,在处理任务时会分配到不同的认知活动中,驾驶员必须决定如何分配注意力以满足任务要求并确保安全。反应时间代表驾驶员对紧急情况的反应能力,在分心状态下反应时间会增大,这表明驾驶员在执行双重任务(即分心任务和非分心任务)时会产生认知瓶颈。分心的基本来源包括视觉和听觉分心,这也会显著影响认知过程。因此,如何系统性地兼顾认知约束和物理约束,以便解释复杂的分心驾驶行为,成为本领域需要解决的问题。
技术实现思路
1、本发明的目的就是为了克服上述现有技术存在的难以兼顾认知约束和物理约束,无法真实可靠地解释分心驾驶行为的缺陷而提供一种考虑认知-物理约束的分心驾驶行为模拟方法及装置。
2、本发明的目的可以通过以下技术方案来实现:
3、根据本发明的第一方面,提供一种考虑认知-物理约束的分心驾驶行为模拟方法,包括以下步骤:
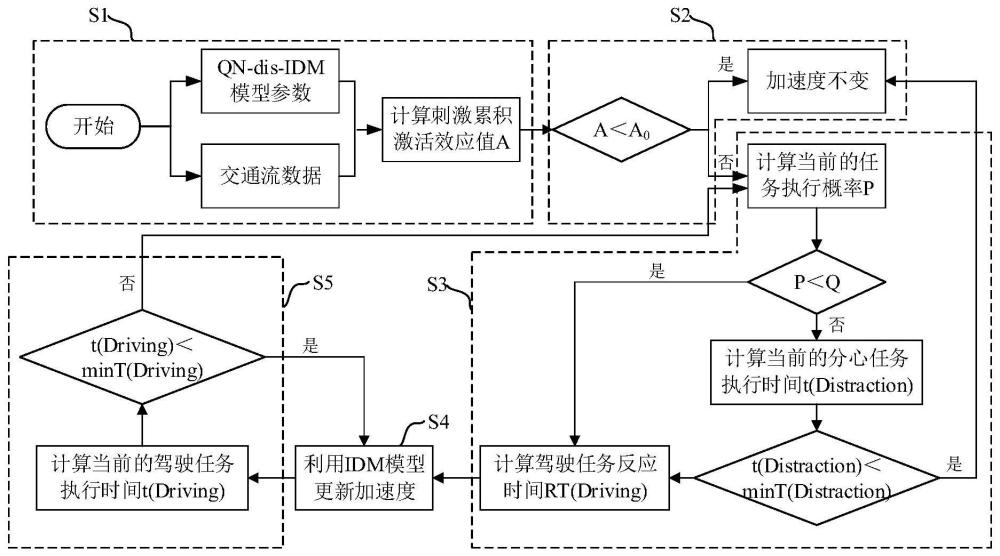
4、s1,获取初始加速度、驾驶任务信息和分心任务信息,并利用刺激累积激活模型计算刺激累积激活效应值,所述分心任务包括视觉分心任务和语音分心任务;
5、s2,当所述刺激累积激活效应值超出效应阈值时,传递所述驾驶任务信息和所述分心任务信息,否则保持当前的加速度不变,所述效应阈值是预先设置的;
6、s3,当不同类任务信息同时到达单任务服务器时,利用逻辑回归模型计算当前的任务执行概率,根据所述当前的任务执行概率确定先执行任务和后执行任务,并利用反应时间模型计算当前的驾驶任务反应时间;
7、s4,基于当前的驾驶任务反应时间,利用智能驾驶员模型更新加速度;
8、s5,利用反应时间模型计算驾驶任务执行时间,利用执行时间模型计算当前的驾驶任务最小执行时间,若当前的驾驶任务执行时间小于当前的驾驶任务最小执行时间,则返回s4,反之,则返回s3。
9、作为优选的技术方案,所述s3具体包括:
10、s31,判断当前的任务执行概率是否小于执行概率阈值,若为否,则分心任务为先执行任务,驾驶任务为后执行任务,并转s32,若为是,则驾驶任务为先执行任务,分心任务为后执行任务,并转s33,所述执行概率阈值是预先设置的;
11、s32,利用反应时间模型计算当前的分心任务执行时间,利用执行时间模型计算当前的分心任务最小执行时间,若当前的分心任务执行时间小于当前的分心任务最小执行时间,则保持加速度不变,反之,则转s33;
12、s33,利用反应时间模型计算当前的驾驶任务反应时间和驾驶任务执行时间。
13、作为优选的技术方案,不同类任务的信息流路径包括,所述驾驶任务信息和所述视觉分心任务信息均依次经过视觉感知子网络和认知子网络后,到达运动子网络,所述语音分心任务依次经过语音感知子网络和认知子网络后,到达运动子网络。
14、作为优选的技术方案,不同类任务的反应时间由各类任务的信息流路径决定。
15、作为优选的技术方案,所述后执行任务的反应时间为当前的后执行任务等待时间与当前的后执行任务信息进入单任务服务器后的处理时间之和,所述后执行任务的等待时间由当前的分心任务类型确定。
16、作为优选的技术方案,所述后执行任务的等待时间由当前的分心任务类型确定的过程包括:若所述当前的分心任务为语音分心任务,则当前的后执行任务等待时间为先执行任务信息在单任务服务器中处理结束时经过的总时间;若所述当前的分心任务为视觉分心任务,则当前的后执行任务等待时间为时间比较结果,所述时间比较结果为先执行任务信息在单任务服务器中处理结束时经过的总时间与后执行任务信息进入单任务服务器之前的总处理时间中的最大值。
17、作为优选的技术方案,所述刺激累积激活模型表达式为:
18、
19、式中,a(t)表示t时刻的刺激累积激活效应值,ε(t)表示拟合过程中感知噪声随时间的变化,τ-1表示视网膜成像角度变化率与成像尺寸之比,wl和m为预先设置的参数。
20、作为优选的技术方案,所述逻辑回归模型的表达式为:
21、
22、式中,p表示任务执行概率,y=1表示驾驶员选择分心任务,ttc表示碰撞时间,α、β为预先设置的参数。
23、作为优选的技术方案,所述智能驾驶员模型表达式为:
24、
25、
26、式中,an(t+rt)表示t+rt时刻目标车辆的加速度,rt表示驾驶任务反应时间,表示目标车辆的最大加速度,表示期望速度,vn表示实际速度,sn表示后车的前保险杠与前车的后保险杠之间的距离,为所需的距离,δvn表示速度差,表示舒适减速度,表示静止最小间距,期望车头时距,n表示车辆编号,γ为预先设置的参数。
27、根据本发明的第二方面,提供一种考虑认知-物理约束的分心驾驶行为模拟装置,包括存储器、处理器,以及存储于所述存储器中的程序,所述处理器执行所述程序时实现所述的方法。
28、与现有技术相比,本发明具有以下有益效果:
29、1、本发明基于qn-mhp网络框架,将刺激累积激活模型引入感知子网络,用于判断驾驶任务信息和分心任务信息是否向认知子网络传递,将反应时间模型、逻辑回归模型和执行时间模型引入认知子网络,用于建立双任务排队与切换机制,将智能驾驶员模型引入运动子网络,用于根据感知子网络和认知子网络的运行结果判断是否更新加速度,即通过感知子网络和认知子网络形成认知约束,通过运动子网络形成物理约束,得到考虑认知-物理约束的qn-dis-idm模型,利用该模型处理交通流数据,即能够实现对分心驾驶行为的精准模拟,该模拟方法能够克服传统建模中缺乏认知约束的缺点,利用神经生理学的证据支撑,显著提高交通仿真模拟分心驾驶的真实度和可靠度,同时提高分心驾驶行为解释的准确性;
30、2、本发明根据视觉分心任务和语音分心任务各自的信息流路径计算相应的反应时间,即区分不同类型任务信息的信息流路径,提供不同分心驾驶行为模式的适配算法,使得交通流仿真能够模拟绝大多数类型的驾驶人分心驾驶行为特征,便于qn-dis-idm仿真模型的使用、派生及迁移;
31、3、本发明利用多种模型构建考虑认知-物理约束的qn-dis-idm模型模拟分心驾驶行为,根据输入的初始加速度、驾驶任务信息和分心任务信息等交通流数据,经过各模型依次处理,能够实现车辆加速度的自动更新,满足了自动驾驶虚拟测试对于生成危险场景的交通流仿真模型的需求,对提高自动驾驶测试效率具有重要的推动作用和实际价值。
- 还没有人留言评论。精彩留言会获得点赞!