一种语音识别和数字人共语手势生成方法与流程
本发明涉及人工智能,特别涉及一种语音识别和数字人共语手势生成方法。
背景技术:
1、在现实的人类沟通中,手势和说话人语音往往是强相关的,手势信号是人类正常沟通的一部分,这在演讲中表现最为明显,随着现代生成式对抗网络的数字人的发展,数字人在进行讲话时会伴随着手势动作。
2、而现有的数字人在讲话时的手势动作,大多是由动作捕捉真人动作来驱动,也可以预定义动作动画,通过动作指令来驱动,通过动作捕捉驱动数字人动作需要耗费人力,无法大规模推广,且通过动作指令驱动数字人动作的问题是动作之间的过渡不自然,每个动作都需要经历初始状态、动作准备、比划、姿势保持、动作收回等一些列程式化的过程,显得比较机械,近年来也有研究通过ai模型来驱动数字人的动作,例如在《learningindividualstyles of conversational gesture》中的方法,该研究通过人类说话的视频数据建立语音与手势的关系,然后直接通过语音生成手势,但语音生成数字人手势关键点的正确率仍存在不足,本申请提出一种语音识别和数字人共语手势生成方法。
技术实现思路
1、本发明的目的在于提供一种语音识别和数字人共语手势生成方法,以解决上述背景技术中提出的问题。
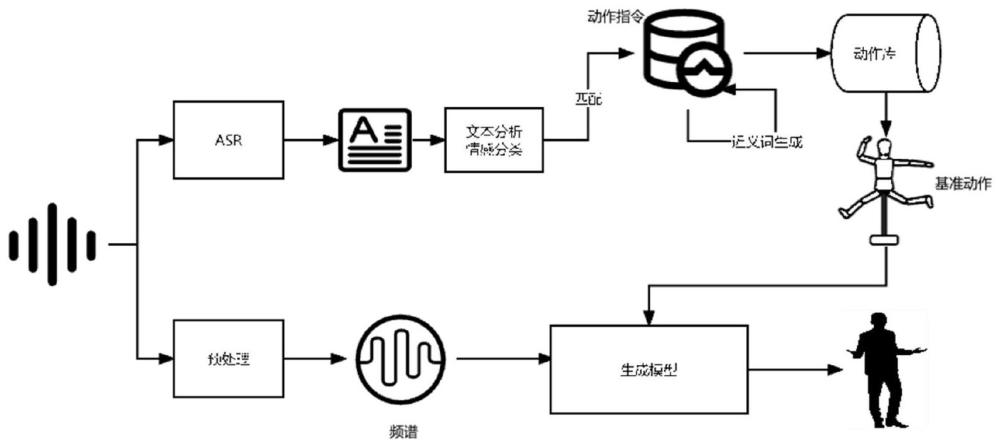
2、为实现上述目的,本发明提供如下技术方案:一种语音识别和数字人共语手势生成方法,该方法包括:
3、步骤一:语音识别将语音转换为文本;
4、步骤二:文本分析获取基准动作;
5、步骤三:语音到手势动作生成。
6、优选的,所述步骤一中,所述语音识别采用自动语音识别技术进行语音识别,将人类语音转换为文本。
7、优选的,所述步骤二中,所述文本分析基于自然语言处理技术对文本进行分析,其用于匹配预置的数字人动作库中的基准动作。
8、优选的,所述步骤二中,所述文本分析获取基准动作包括:
9、文本匹配动作:通过常用共语手势文本匹配,获取共语手势指令;
10、近义词匹配动作:对动作指令数据库中的关键词,进行近义词生成扩展待匹配的动作指令,在步骤一转换的文本中扫描到关键词的近义词时,也匹配相应的动作指令;
11、情感分析:对带有情感色彩的主观性文本进行推理和分析,自动进行文本情感倾向性判断,输出文本的情感分类,匹配到不同的预置表情和肢体动作。
12、优选的,所述近义词的生成采用synonyms工具,对带有情感色彩的主观性文本进行推理和分析采用fasttext或bilstm+attention算法。
13、优选的,所述步骤三中,语音到手势动作生成使用的模型采用生成式对抗网络的结构,并增加了一个l1回归损失实现生产动作的连续性。
14、优选的,所述将步骤二中以文本分析匹配的动作姿势作为初始姿态,结合语音频谱信号,输入到生成式对抗网络结构的模型中,生成数字人的共语手势关键点序列。
15、优选的,所述生成式对抗网络结构的模型包括unet架构的模型,所述unet模型的翻译结构通过l1回归损失学习将一维信号映射到姿势序列向量上。
16、优选的,所述l1回归损失的计算方式是将预测值和真实值之间的差值取绝对值,然后求和并除以样本数量:
17、具体公式为:l1回归损失=1/n*∑|y_i-f(x_i)|
18、所述y_i为第i个样本的真实值,并且,f(x_i)为第i个样本的预测值,n为样本数量。
19、优选的,所述unet架构由两个主要部分组成:收缩路径和扩展路径,收缩路径是由几个卷积层和池化层组成,这些层逐渐降低输入图像的空间分辨率,同时增加特征通道的数量;扩展路径是由几个反卷积层组成,这些层将特征映射上采样为输入图像的原始大小,unet架构的核心在于扩展路径,与收缩路径类似,它也包含几个扩展块。
20、本发明的技术效果和优点:
21、(1)本发明分析经过语音识别后的文本,匹配动作库中的动作作为基准动作,结合语音和初始动作,基于生成式对抗网络,生成手势动作的骨骼关键点,进而在数字人说话时驱动数字人的手势,基于语音生成的共语手势的pck准确率更高,生成的数字人手势更有效的模拟了现实中人类演讲中的手势动作,耗费的人力低,且提高数字人动作的流畅性;
22、(2)本发明结合了语音自动识别技术和自然语言处理技术,根据语义和情感分析结果匹配初始动作姿势,结合语音到手势生成模型和动作库中的基准动作更准确的生成共语手势动画,采用ai技术驱动数字人肢体动作,可以大大降低目前通过真人的动作捕捉驱动数字人的人力成本和设备成本,降低数字人落地的门槛,有助于数字人大规模落地应用。
技术特征:
1.一种语音识别和数字人共语手势生成方法,其特征在于,该方法包括:
2.根据权利要求1所述的一种语音识别和数字人共语手势生成方法,其特征在于,所述步骤一中,所述语音识别采用自动语音识别技术进行语音识别,将人类语音转换为文本。
3.根据权利要求2所述的一种语音识别和数字人共语手势生成方法,其特征在于,所述步骤二中,所述文本分析基于自然语言处理技术对文本进行分析,其用于匹配预置的数字人动作库中的基准动作。
4.根据权利要求3所述的一种语音识别和数字人共语手势生成方法,其特征在于,所述步骤二中,所述文本分析获取基准动作包括:
5.根据权利要求4所述的一种语音识别和数字人共语手势生成方法,其特征在于,所述近义词的生成采用synonyms工具,对带有情感色彩的主观性文本进行推理和分析采用fasttext或bilstm+attention算法。
6.根据权利要求2所述的一种语音识别和数字人共语手势生成方法,其特征在于,所述步骤三中,语音到手势动作生成使用的模型采用生成式对抗网络的结构,并增加了一个l1回归损失实现生产动作的连续性。
7.根据权利要求6所述的一种语音识别和数字人共语手势生成方法,其特征在于,所述将步骤二中以文本分析匹配的动作姿势作为初始姿态,结合语音频谱信号,输入到生成式对抗网络结构的模型中,生成数字人的共语手势关键点序列。
8.根据权利要求7所述的一种语音识别和数字人共语手势生成方法,其特征在于,所述生成式对抗网络结构的模型包括unet架构的模型,所述unet模型的翻译结构通过l1回归损失学习将一维信号映射到姿势序列向量上。
9.根据权利要求8所述的一种语音识别和数字人共语手势生成方法,其特征在于,所述l1回归损失的计算方式是将预测值和真实值之间的差值取绝对值,然后求和并除以样本数量:
10.根据权利要求8所述的一种语音识别和数字人共语手势生成方法,其特征在于,所述unet架构由两个主要部分组成:收缩路径和扩展路径,收缩路径是由几个卷积层和池化层组成,这些层逐渐降低输入图像的空间分辨率,同时增加特征通道的数量;扩展路径是由几个反卷积层组成,这些层将特征映射上采样为输入图像的原始大小,unet架构的核心在于扩展路径,与收缩路径类似,它也包含几个扩展块。
技术总结
本发明公开了一种语音识别和数字人共语手势生成方法,该方法包括:步骤一:语音识别将语音转换为文本;步骤二:文本分析获取基准动作;步骤三:语音到手势动作生成。步骤一中,所述语音识别采用自动语音识别技术进行语音识别,将人类语音转换为文本。发明分析经过语音识别后的文本,匹配动作库中的动作作为基准动作,结合语音和初始动作,基于生成式对抗网络,生成手势动作的骨骼关键点,进而在数字人说话时驱动数字人的手势,基于语音生成的共语手势的PCK准确率更高,生成的数字人手势更有效的模拟了现实中人类演讲中的手势动作,耗费的人力低,且提高数字人动作的流畅性。
技术研发人员:陈金,满昊扬,陈硕,李响,范顺国,张渊佳,侯圣文
受保护的技术使用者:天翼云科技有限公司
技术研发日:
技术公布日:2024/4/17
- 还没有人留言评论。精彩留言会获得点赞!