基于全局特征向量场投票网络的非合作目标位姿估计方法与流程
本发明属于图像处理,涉及基于全局特征向量场投票网络的非合作目标位姿估计方法。
背景技术:
1、近年来,随着计算机视觉领域的不断发展,在机器人领域应用较为广泛。仿人机器人整体采用仿人型设计,包括头部,躯干和仿人形双臂。其中机器人在头部布置视觉相机,在单臂腕部布置局部测量相机,在输入仅有rgb图像的情况下,对操作目标进行位姿估计,辅助机械臂对目标完成精细化操作。
2、在传统的物体识别与位姿估计方式中,没有3d数据输入的情况下,基于模板匹配的位姿估计算法被率先提出,在实验中表现出良好的鲁棒性。然而,尽管进行充分的采样,提取足够鲁棒的模板,但在物体被遮挡情况下其算法效果依然很差。
3、传统的基于关键点的2d-3d算法对局部关键点的检测鲁棒性很好,即使在杂乱的场景和严重的遮挡下,也能有效、准确地估计出目标的姿态,然而传统的方法很难处理低纹理的目标和低分辨率的图像。
4、基于回归的算法,如posecnn,将2d图像中的像素直接回归到6d位姿。但是由于缺乏深度信息,只能在二维图像中对物体进行定位并预测深度获得三维位置,然而由于旋转空间的非线性,直接估计三维旋转也是困难的,为此,将旋转空间离散化、将三维旋转转化为分类任务,这样的离散方法只能产生一个粗糙的结果。在网络完成预测后,会调用点云信息进行精匹配。然而获得高精度的三维信息需要消耗的时间较长,不能进行实时预测。
技术实现思路
1、本发明的技术解决问题是:克服现有技术的不足,提供基于全局特征向量场投票网络的非合作目标位姿估计方法,解决目前基于rgb的非合作目标位姿估计的鲁棒性和精确预测问题。
2、本发明的技术解决方案是:
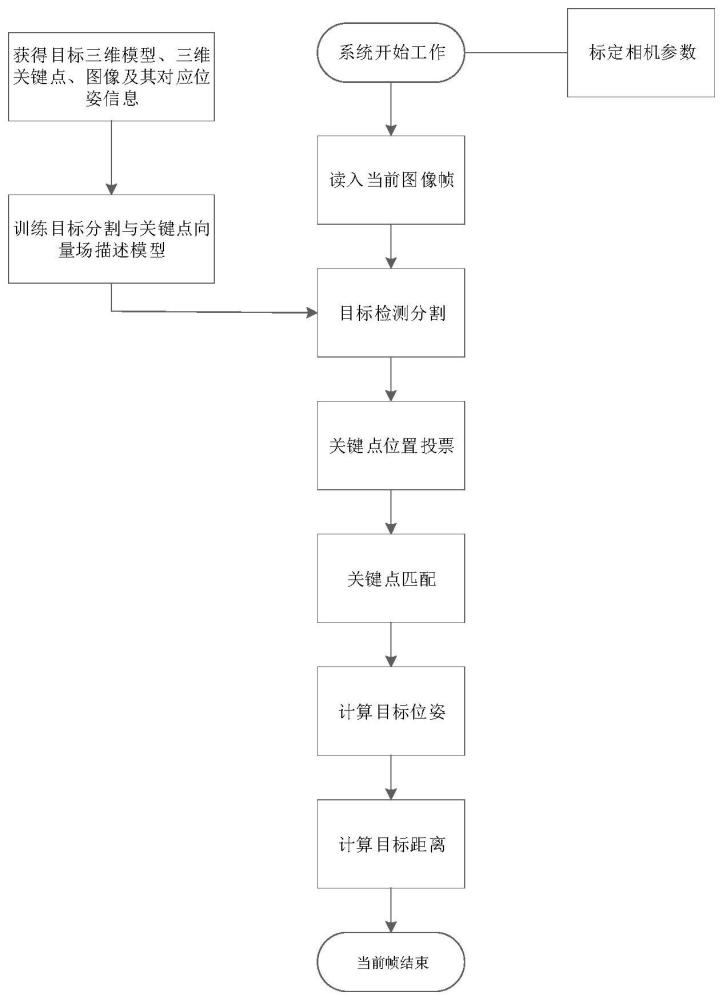
3、本发明公开了基于全局特征向量场投票网络的非合作目标位姿估计方法,包括:
4、进行相机参数标定,得到相机参数值;
5、构建目标的三维模型;
6、对所述目标的三维模型进行扩展,得到扩充后的数据集;
7、根据所述目标的三维模型,选取模型关键点,得到向量场真值与分割掩码图像;
8、根据所述模型关键点,计算关键点权重;
9、构建位姿估计网络;
10、利用所述向量场真值与分割掩码图像,对位姿估计网络进行训练,得到训练好的位姿估计网络;
11、将测试图像作为所述训练好的位姿估计网络的输入,得到分割掩码和指向物体关键点的向量场;
12、根据所述分割掩码和指向物体关键点的向量场,结合所述模型关键点和相机参数值,得到估计位姿。
13、进一步地,在上述位姿估计方法中,对所述目标的三维模型进行扩展,得到扩充后的数据集,具体方法为:
14、利用rgb相机的纹理对目标的三维模型进行补充;
15、采取双线性插值优化,补充目标的三维模型的细节,实现未知目标进行高精度的三维重建,得到重建模型;
16、通过高精度配准方法,结合所述重建模型,获取场景中物体的六自由度位置和姿态;
17、对所述重建模型中的目标物体区域,进行平移、旋转、遮挡和裁剪处理,将目标物体与不同背景结合,形成多个场景下的目标数据;
18、对所述多个场景下的目标数据进行不同场景、不同灯光、不同角度、不同距离下的渲染,得到扩充后的数据集。
19、进一步地,在上述位姿估计方法中,根据所述模型关键点,计算关键点权重,具体为:
20、通过对重建模型进行降采样操作,获得点云数量为x的模型;其中,1000≤x≤5000;
21、采用iss算法,得到满足协方差阈值的y个特征点;其中,50≤y≤150;
22、根据特征点,采用最远点采样法,获取关键点;
23、计算每个关键点的谐波中心度;
24、将所有关键点的谐波中心度进行归一化,得到归一化后的谐波中心度;
25、根据所述归一化后的谐波中心度,得到每个关键点的权重。
26、进一步地,在上述位姿估计方法中,所述计算每个关键点的谐波中心度,具体为:
27、
28、其中,c(v)为关键点v的谐波中心度,d(u,v)为关键点u到v的最短路径长度,表示对节点v到除了自身节点v外的所有其他节点进行求和。
29、进一步地,在上述位姿估计方法中,所述构建位姿估计网络,具体为:
30、位姿估计网络,包括resnet网络、分割掩码分支和关键点向量分支;
31、resnet网络,提取输入图像的特征向量,将所述特征向量分别输出给分割掩码分支和关键点向量分支;
32、分割掩码分支,包括串联的5个卷积层和4个上采样层,将所述特征向量进行处理后,输出每个像素点是否属于物体的分割掩码;
33、关键点向量分支,包括串联的5个卷积层和2个池化层,根据所述特征向量,输出每个像素点分别指向各物体关键点的向量场。
34、进一步地,在上述位姿估计方法中,利用所述向量场真值与分割掩码图像,对位姿估计网络进行训练,得到训练好的位姿估计网络,具体方法为:
35、s51、利用位姿估计网络输出的分割掩码与所述分割掩码图像,计算交叉熵损失函数;
36、s52、利用位姿估计网络输出的关键点向量场与所述向量场真值,在预测的目标物体掩码区域内计算l1损失函数;
37、s53、将所述交叉熵损失函数和l1损失函数求和,得到总损失函数;
38、s54、重复步骤s51~s53,直到总损失函数收敛或达到训练次数,得到训练好的位姿估计网络。
39、进一步地,在上述位姿估计方法中,所述根据所述分割掩码和指向物体关键点的向量场,结合所述模型关键点和相机参数值,得到估计位姿,具体为:
40、对所述预测的分割掩码和关键点向量场,随机取2个分割掩码内像素的向量场的交点作为假设关键点;重复至少2次,生成多个可能关键点位置;
41、计算分割掩码内的所有像素p相对所述可能关键点位置的投票分数;
42、选取所述投票分数中最高分数对应的像素点为预测关键点;
43、根据相机参数值、预测关键点与对应的模型关键点,解算得到关键点相对于相机的位置和姿态。
44、进一步地,在上述位姿估计方法中,所述计算分割掩码内的所有像素p相对所述可能关键点位置的投票分数,具体为:
45、
46、其中,wk,i为第k个关键点的第i个可能的位置的投票得分,表示指标函数,θ为阈值,fp为第p个像素点在图像上的位置,vk,p为网络预测得到的第p个像素点指向第k个关键点的向量方向;hk,i为第k个关键点的第i个可能的位置;ck为第k个关键点权重。
47、本发明与现有技术相比的优点在于:
48、(1)本发明定义了一组语义关键点,并通过图的中心性度量计算其训练权重,使用resnet作为特征提取骨干,构建了分割掩码分支和关键点向量场分支,利用分割确定目标在图像的区域,通过对该区域的像素级向量场预测关键点,并进行投票,得到关键点的定位;
49、(2)本发明是端到端的位姿估计网络,仅需要rgb作为输入,能达到实时预测目标位姿的效果;基于向量场的设定使得它对遮挡物体具有良好的鲁棒性。
50、(3)本发明提出一种基于向量场投票的位姿估计方法,设计了一种基于向量场投票的神经网络结构,输出目标图像关键点并利用pnp算法估计位姿,算法输入为rgb图像,输出为目标位姿,通过构建位姿数据集的方式对神经网络参数进行训练,丰富的数据制作手段使得数据驱动网络学习得更好,能够适应更多的场合;
51、(4)本发明利用图像全局性特征构建关键点的全局向量场,通过向量场对目标关键点网络进行监督训练,引导神经网络对场景中的目标进行关键点的位置精确稳定预测,获得关键点的对应关系,在物体部分遮挡下,仍然能准确预测出所有关键点的位置。
52、(5)本发明提出了使用图中心性度量来为目标姿势的不同部分分配训练权重。提出的度量量化了关键点与其邻域的紧密连接程度,提高了模型的准确性。
- 还没有人留言评论。精彩留言会获得点赞!