基于遗传算法的个性化联邦学习神经网络层次划分方法
本发明涉及联邦学习,具体涉及一种基于遗传算法的个性化联邦学习神经网络层次划分方法。
背景技术:
1、在大数据时代,爆炸性增长的数据和不断进步的机器学习技术推动着各行各业的发展。为了优化模型和提高经济效益,广泛收集用户的私人数据已成为趋势。这些数据来自社交媒体、移动设备、可穿戴设备等,包含有关个人行为、偏好和健康状况等敏感内容。然而集中收集和存储这些数据可能引发隐私和安全问题,因为它们容易遭受网络攻击和未经授权的访问。
2、联邦学习(federated learning)是一种新兴的机器学习方法,旨在解决集中式学习可能引发的隐私和安全问题。传统机器学习方法通常需要将所有数据集中在一个中央服务器上进行训练。相比之下,联邦学习将模型训练任务分发到多个客户端,每个客户端仅处理其本地数据,并确保训练数据保持在客户端本地,以维护数据隐私。然而,联邦学习中存在客户端异构性的问题,包括数据分布不均、计算能力差异和通信带宽限制,这些因素可能对模型的性能和泛化能力构成挑战。
3、个性化联邦学习(personalized federated learning,pfl)方法的提出,有效地缓解了客户端异构性的问题。pfl的核心思想是在保护数据隐私的基础上,允许每个参与方在本地微调模型来适应其数据,以提升模型的个性化性能;同时,通过信息聚合学习通用知识,以提升模型泛化能力。其中一种pfl方法是将神经网络模型进行分层,即分为全局共享层和个性化层。客户端在本地更新后,将全局层模型参数上传服务器加权聚合,获取共享的通用特征信息;与此同时,个性化层模型参数保留在客户端本地,使模型能够学习并适应每个客户端独特的数据分布和特点。这种方法旨在通过融合共享和个性化信息,提高整个个性化联邦学习模型在不同应用场景中的性能和效果。
4、在pfl中,全局层和个性化层的划分方式将对模型性能产生重要影响。paul puliang等人提出的lg-fedavg方法将接近输入的神经网络层作为个性化层,这适用于处理图像数据差异较大的情况;相反,manoj ghuhan等人提出的fedper方法将个性化层置于接近输出的神经网络层,这适用于数据标签分布不均匀的情况。而在实际pfl应用中,全局层和个性化层的可能有各种不同的划分方式。因此,本发明提出的方法引入了遗传算法以自适应地搜索出最佳的神经网络划分方法,以适用于不同的应用和数据分布情况。
5、有鉴于此,有必要提出一种基于遗传算法的个性化联邦学习神经网络层次划分方法,以解决上述问题。
技术实现思路
1、本发明的目的在于提供一种基于遗传算法的个性化联邦学习神经网络层次划分方法。
2、为实现上述目的,本发明采用以下技术方案,包括:
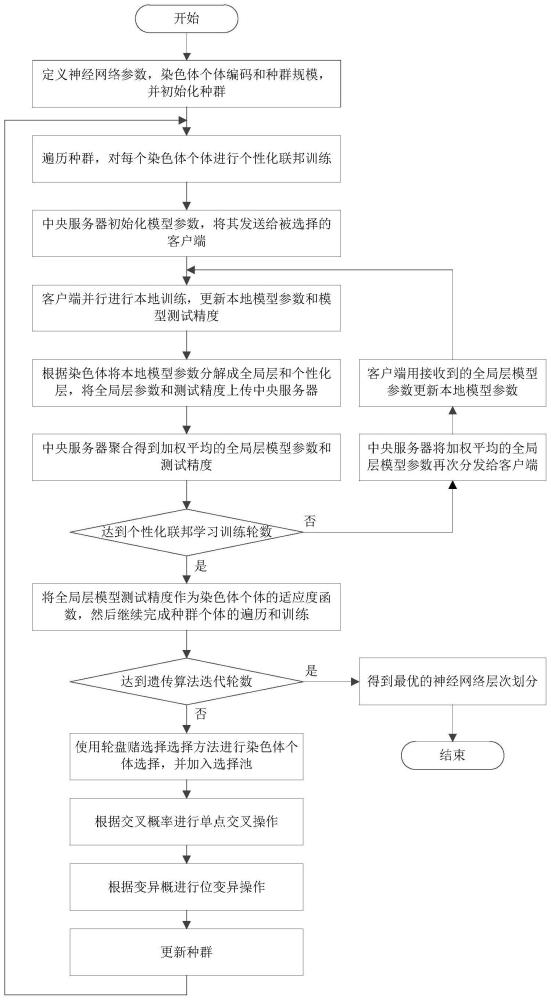
3、步骤1、建立个性化联邦学习神经网络,划分神经网络模型中的全局层和个性化层,并初始化种群;
4、步骤2、遍历所述种群,对于所述种群中的任一个体,进行个性化联邦学习训练并得到每个所述个体的适应度函数值;
5、步骤3、使用轮盘赌选择方法选择所述个体,对所述个体进行点交叉操作和位变异操作,形成新一代种群;
6、步骤4、重复所述步骤1、所述步骤2和所述步骤3,直到达到预定的迭代轮数,得到最优的所述全局层和所述个性化层的划分方法。
7、作为本发明的进一步改进,所述步骤1中,所述个性化联邦学习神经网络包括一个中央服务器和m个客户端,所述个性化联邦学习神经网络的总层数为l,所述个性化联邦学习神经网络的参数为w=(v1,v2,...vj...,vl),其中,vj表示第j层的参数。
8、作为本发明的进一步改进,所述步骤1中划分所述全局层和所述个性化层的方法为:定义迭代轮数为t,定义种群规模为s,随机生成s个互不相同的染色体个体并初始化种群p=(c1,c2,...,ci,...,cs),其中,个体ci=(ci1,ci2,...,cij,...,cil),cij∈{0,1},j∈{1,2,...,l},所述个体为长度为l的0-1整数序列,所述整数序列分别对应所述神经网络模型的每一层,cij=0表示个体ci对应的第j层神经网络模型为个性化层,cij=1表示个体i对应的第j层神经网络模型为全局层,ci表示所述神经网络模型中全局层和个性化层的一种划分。
9、作为本发明的进一步改进,所述步骤2包括:
10、步骤21、中央服务器随机初始化模型参数w,然后随机选择个客户端,γ∈(0,1)为客户端选择率,接着将模型参数w发送给所述客户端来初始化所述客户端的本地模型参数;
11、步骤22、所述客户端采用随机梯度下降法,利用各自本地数据集对本地模型进行e轮本地训练,得到更新后的本地模型参数w′m和模型测试精度a′m,
12、步骤23、所述客户端均根据染色体ci将所述本地模型参数w′m分解成全局层模型参数和个性化层模型参数其中,v′mj为第m个被选择的所述客户端更新后的所述本地模型的第j层参数,
13、步骤24、所述客户端将所述全局层模型参数和测试精度a′m上传所述中央服务器,
14、步骤25、所述中央服务器对所述客户端上传的信息进行聚合,得到加权平均的全局层模型参数和模型测试精度公式为:
15、
16、
17、其中,dm为所述客户端的数据量,为所述客户端的总数据量;
18、步骤26、若个性化联邦学习训练轮数达到r轮,则终止训练,将得到的所述模型测试精度作为个体ci的适应度函数然后继续遍历所述种群对其它所述个体进行个性化联邦学习训练。
19、作为本发明的进一步改进,所述步骤26中,若迭代轮数达到t轮,则中止迭代,得到最优的神经网络层次划分个体否则,所述中央服务器将加权平均的所述全局层模型参数再发送给所有所述客户端,而所述客户端收到所述后,更新各自本地模型参数然后继续下一轮个性化联邦学习训练。
20、作为本发明的进一步改进,所述步骤3中所述的轮盘赌选择方法进行s次选择,将每次选择的所述个体加入到选择池u中,其中,任一个体ci被选中的概率p(ci)与其适应度值f(ci)成正比,即
21、作为本发明的进一步改进,所述点交叉操作的方法是:以交叉概率p1从所述选择池u中选择任意两个父代个体ci和cj,随机产生交叉位k,k∈[1,l],将所述ci的前k个基因和所述cj的后l-k个基因交叉组合生成子代将所述cj的前k个基因和所述ci的后l-k个基因交叉组合生成子代
22、作为本发明的进一步改进,所述位变异操作的方法是:以变异概率p2从所述选择池u中选择任一个体ci,随机产生变异位为n,n∈[1,l],对第n个基因位进行0-1位翻转操作,得到变异后的新个体
23、有益效果:
24、本发明使用遗传算法对神经网络层次进行基因编码和进化迭代,可以在不同的划分方案中搜索并选择出最佳的神经网络层次划分方法,以优化个性化联邦学习中模型训练的性能。本发明提供的方法可以灵活地适应不同的神经网络架构和任务的需求,实现对神经网络层次的任意划分,具有广泛的通用性和适用性。
- 还没有人留言评论。精彩留言会获得点赞!