一种基于大数据的多源数据风险管理系统及方法与流程
本发明涉及数据管理,具体为一种基于大数据的多源数据风险管理系统及方法。
背景技术:
1、在网络后端数据服务中经常会需要从第三方数据源中获取数据,能够帮助用户更便捷地获取到想要查询的数据,为查询到更加完整、精确的数据,往往需要接入多个第三方数据源,将多个第三方数据源接入后,将多个第三方数据源提供的数据格式进行统一转换,并对数据内容进行清洗,可以供用户调用;
2、然而,由于存在多个第三方数据源可以选择接入,从不同的第三方数据源处调用不同类型数据,发生调用数据延时、失败等异常情况的严重性有所不同,随机地选择并接入第三方数据源,容易因第三方数据源选择不当导致数据调用出现异常情况的风险加剧。
3、所以,人们需要一种基于大数据的多源数据风险管理系统及方法来解决上述问题。
技术实现思路
1、本发明的目的在于提供一种基于大数据的多源数据风险管理系统及方法,以解决上述背景技术中提出的问题。
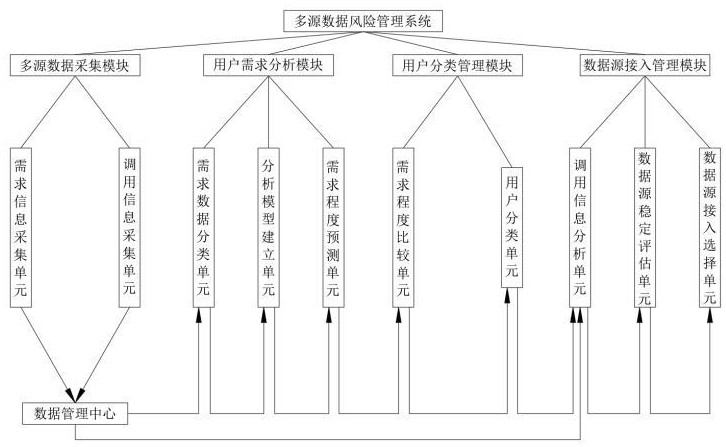
2、为了解决上述技术问题,本发明提供如下技术方案:一种基于大数据的多源数据风险管理系统,所述系统包括:多源数据采集模块、数据管理中心、用户需求分析模块、用户分类管理模块和数据源接入管理模块;
3、所述多源数据采集模块的输出端连接所述数据管理中心的输入端,所述数据管理中心的输出端连接所述用户需求分析模块的输入端,所述用户需求分析模块的输出端连接所述用户分类管理模块的输入端,所述用户分类管理模块和数据管理中心的输出端连接所述数据源接入管理模块的输入端;
4、通过所述多源数据采集模块采集用户调用不同第三方数据源中数据的历史信息以及从不同第三方数据源中查询数据的历史信息,将采集到的全部数据传输到所述数据管理中心;
5、通过所述数据管理中心存储并管理接收到的全部数据;
6、通过所述用户需求分析模块将调用的数据进行分类,分析不同用户对不同类型数据的需求程度;
7、通过所述用户分类管理模块依据分析结果将用户进行分类;
8、通过所述数据源接入管理模块为同一类用户选择数据源进行接入。
9、进一步的,所述多源数据采集模块包括需求信息采集单元和调用信息采集单元;
10、所述需求信息采集单元和调用信息采集单元的输出端连接所述数据管理中心的输入端;
11、所述需求信息采集单元用于采集不同用户以往在不同时间段内调用数据的次数信息;
12、所述调用信息采集单元用于采集从不同的第三方数据源中查询数据的历史信息,包括以往数据的查得次数以及以往每次查询得到数据花费的时长信息。
13、进一步的,所述用户需求分析模块包括需求数据分类单元、分析模型建立单元和需求程度预测单元;
14、所述需求数据分类单元的输入端连接所述数据管理中心的输出端,所述需求数据分类单元的输出端连接所述分析模型建立单元的输入端,所述分析模型建立单元的输出端连接所述需求程度预测单元的输入端;
15、所述需求数据分类单元用于将用户以往调用的数据按用户需求进行分类,确认不同用户以往在不同时间段内调用不同类型数据的次数信息;
16、所述分析模型建立单元用于调取随机一个用户以往在不同时间段内调用不同类型数据的次数信息并建立用户对不同类型数据的调用分析模型,有几类数据就建立几个调用分析模型;
17、所述需求程度预测单元用于依据调用分析模型分析用户对不同类型数据的需求程度。
18、进一步的,所述用户分类管理模块包括需求程度比较单元和用户分类单元;
19、所述需求程度比较单元的输入端连接所述需求程度预测单元的输出端,所述需求程度比较单元的输出端连接所述用户分类单元的输入端;
20、所述需求程度比较单元用于比较随机一个用户对不同类型数据的需求程度,预测对应用户在未来时间需求程度最高的数据类型;
21、所述用户分类单元用于将对相同类型数据需求程度最高的用户分为同一类。
22、进一步的,所述数据源接入管理模块包括调用信息分析单元、数据源稳定评估单元和数据源接入选择单元;
23、所述调用信息分析单元的输入端连接所述用户分类单元和数据管理中心的输出端,所述调用信息分析单元的输出端连接所述数据源稳定评估单元的输入端,所述数据源稳定评估单元的输出端连接所述数据源接入选择单元的输入端;
24、所述调用信息分析单元用于调取不同的第三方数据源以往对同一类用户最需要的数据的查得次数以及以往每次查询得到最需要数据花费的时长信息至所述数据源稳定评估单元;
25、所述数据源稳定评估单元用于评估不同第三方数据源查询对应类型数据的稳定程度;
26、所述数据源接入选择单元用于比较不同第三方数据源查询对应类型数据的稳定程度,依据比较结果将第三方数据源进行分组,为同一类用户选择并接入最合适的一组第三方数据源,在接入第三方数据源后,将多个第三方数据源提供的数据格式进行统一转换,并对数据内容进行清洗,供用户调用。
27、一种基于大数据的多源数据风险管理方法,包括以下步骤:
28、z1:采集用户调用不同第三方数据源中数据的历史信息以及从不同第三方数据源中查询数据的历史信息;
29、z2:将调用的数据进行分类,分析不同用户对不同类型数据的需求程度;
30、z3:依据分析结果将用户进行分类;
31、z4:调取从不同第三方数据源中查询数据的历史信息,分析第三方数据源的数据查询稳定程度;
32、z5:为同一类用户选择数据源进行接入。
33、进一步的,在步骤z1中:将t1到t2时间段平均分为n个时间段,其中,t2表示当前时间,采集到不同用户以往在n个时间段内调用数据的次数信息,采集从不同的第三方数据源中查询数据的历史信息,包括以往数据的查得次数以及以往每次查询数据花费的时长信息。
34、进一步的,在步骤z2中:将调用的数据按用户的数据服务需求进行分类;
35、例如:用户的数据服务需求为:需要查询某个企业的基本信息和需要查询客户池分布信息,则将这两个需求不同的信息分为不同类型的数据;
36、共得到k个类型数据,调取到随机一个用户以往在n个不同的时间段内调用随机一类数据的次数集合为s={s1,s2,…,sn},建立对应用户对随机一类数据的调用分析模型:
37、sn+1=τ*sn+(1-τ)*pn;
38、预测得到对应用户在第n+1个时间段内调用对应类型数据的次数为sn+1,其中,τ表示平滑系数,0<τ<1,pn表示第n个时间段内调用随机一类数据的次数指数平滑值,根据公式p1=τ*s1+(1-τ)*[(s1+s2+s3)/3]计算得到第1个时间段内调用随机一类数据的次数指数平滑值p1,根据公式p2=τ*s1+(1-τ)*p1计算得到第2个时间段内调用随机一类数据的次数指数平滑值p2,根据公式p3=τ*s2+(1-τ)*p2计算得到第3个时间段内调用随机一类数据的次数指数平滑值p3,依此类推得到pn,pn=τ*sn-1+(1-τ)*pn-1,通过相同方式建立对应用户对k类数据的调用分析模型,并预测得到对应用户在第n+1个时间段内调用k个类型数据的次数,比较预测得到的调用次数,预测调用次数最多的类型的数据为对应用户在第n+1个时间段内需求程度最高的数据类型;
39、由于不同时间段用户调用不同类型数据的次数呈现动态变化,通过大数据技术采集用户以往调用不同类型数据的次数信息,获取以往不同时间段内用户调用随机一类数据的次数信息,利用指数平滑法预测未来一段时间内用户会调用对应类型数据的次数,相对于其余预测算法而言,指数平滑法更加适用于短期内的数据预测,且选择预测时依据的历史数据为当前时间前一段时间的历史数据,而非距当前时间间隔较长的历史数据,预测到的次数更加能够体现用户对对应类型数据的需求性,提高了预测结果的准确性。
40、进一步的,在步骤z3中:得到不同用户在第n+1个时间段内需求程度最高的数据类型,将对相同类型数据需求程度最高的用户分为同一类;
41、调用次数越多,预判用户在未来一段时间内对对应类型数据的需求程度越高,比较不同用户对不同类型数据的需求程度,分析不同用户在未来一段时间内最需要的数据类型,将最需要数据类型相同的用户分为同一类,目的在于预先进行数据统筹,为同一类用户选择相同的第三方数据源进行接入,相对于逐个地为用户选择第三方数据源而言,减少了第三方数据源分析选择的工作量。
42、进一步的,在步骤z4中:调取到以往从不同的第三方数据源中查询随机一类用户需求程度最高的类型的数据的次数集合为n={n1,n2,…,nf},数据的查得次数集合为r={r1,r2,…,rf},从随机一个第三方数据源中每次查询得到数据花费的时长集合为t={t1,t2,…,tc},其中,f表示待接入的第三方数据源个数,c=ri,c表示从随机一个数据源中查得数据的次数,根据下列公式计算随机一个第三方数据源查询对应类型数据的稳定程度qi:
43、qi=(ri/ni)×[1/[(∑cj=1tj)/c]];
44、其中,ni表示以往从随机一个第三方数据源中查询随机一类用户需求程度最高的类型的数据的次数,tj表示从随机一个第三方数据源中第j次查询得到数据花费的时长,得到f个第三方数据源查询对应类型数据的稳定程度集合为q={q1,q2,…,qi,…,qf}。
45、进一步的,在步骤z5中:比较从f个第三方数据源中查询对应类型数据的稳定程度,将第三方数据源按稳定程度从大到小的顺序分为g组,其中,前一组中所有第三方数据源查询对应类型数据的稳定程度都大于后一组,获取到随机一个分组结果中,g组中每一组第三方数据源查询对应类型数据的稳定程度均值集合为l={l1,l2,…,lg},根据公式w=[(∑gv=1(lv-(∑gv=1lv)/g)2)/g]1/2计算随机一个分组结果中,g组参数的离散程度w,计算不同分组结果中g组参数的离散程度,获取离散程度最大的分组结果,从离散程度最大的分组结果中筛选出处于第一组的第三方数据源,为对对应类型数据需求程度最高的用户选择并接入筛选出的第三方数据源;
46、通过大数据技术采集不同第三方数据源以往的数据查询历史信息,分析不同第三方数据源查询数据的稳定程度,数据查得次数占比越高、查询花费时间越少,判断稳定程度越高,在分析得到不同第三方数据源查询数据的稳定程度后,将第三方数据源按稳定程度大小进行分组,并通过分析不同分组结果中参数,即稳定程度的离散程度来将稳定程度相近的第三方数据源分为一组,选择稳定程度最大的一组第三方数据源为同一类用户接入,降低了因第三方数据源选择不当导致数据调用出现异常情况风险加剧的概率,提高了数据调用的效率和成功率。
47、与现有技术相比,本发明所达到的有益效果是:
48、本发明通过通过大数据技术采集用户以往调用不同类型数据的次数信息,获取以往不同时间段内用户调用随机一类数据的次数信息,利用指数平滑法预测未来一段时间内用户会调用对应类型数据的次数,相对于其余预测算法而言,指数平滑法更加适用于短期内的数据预测,且选择预测时依据的历史数据为当前时间前一段时间的历史数据,而非距当前时间间隔较长的历史数据,预测到的次数更加能够体现用户对对应类型数据的需求性,提高了预测结果的准确性;
49、比较不同用户对不同类型数据的需求程度,分析不同用户在未来一段时间内最需要的数据类型,将最需要数据类型相同的用户分为同一类,预先进行数据统筹,为同一类用户选择相同的第三方数据源进行接入,相对于逐个地为用户选择第三方数据源而言,减少了第三方数据源分析选择的工作量;
50、通过大数据技术采集不同第三方数据源以往的数据查询历史信息,分析不同第三方数据源查询数据的稳定程度,在分析得到不同第三方数据源查询数据的稳定程度后,将第三方数据源按稳定程度大小进行分组,并通过分析不同分组结果中参数,即稳定程度的离散程度来将稳定程度相近的第三方数据源分为一组,选择稳定程度最大的一组第三方数据源为同一类用户接入,降低了因第三方数据源选择不当导致数据调用出现异常情况风险加剧的概率,提高了数据调用的效率和成功率。
- 还没有人留言评论。精彩留言会获得点赞!