一种视觉叙事文本生成方法及设备
本发明涉及视觉叙事的,特别是涉及一种视觉叙事文本生成方法及设备。
背景技术:
1、视觉叙事是生成对应于给定图像序列的一个描述故事。给定图像序列是一个事件的一组照片且具有时间顺序。模型识别图像序列的内容进行分析和综合并生成一个描述图像序列内容的故事文本。一般每一个图像对应故事中的一个句子。
2、基于循环神经网络(rnn,recurrent neural networks)的方法广泛应用于该任务。一些方法首先利用卷积神经网络(cnn,convolutional neural network)提取图像的特征,并利用一个rnn建模各个图像之间的关系并得到考虑到各个图像关系的特征。最后,利用rnn根据所得特征进行解码生成描述文本。
3、现有的技术方案如下:
4、1.reco-rl(一种强化学习的框架)[1]利用cnn提取图像特征,并将图像序列表示的平均值作为图像序列整体信息的表示向量。利用一个长短期记忆网络(lstm,long shortterm memory)充当管理器,建模图像序列的关系,并得到一个表示向量用于指导生成。最后利用工作器lstm生成文本。该工作器以图像特征和管理器的输出特征作为输入。整个模型通过强化学习方法进行训练。该方法的问题是没有考虑到工作器lstm对其中不同信息的关注问题。
5、2.在rnn中采用注意力机制对图像和语言信息分配合理的注意力权重的方法[2]。该方法仅仅考虑了视觉和语言信息的注意力差异,难以区分状态信息的重要性。
6、3.在训练过程中随机将参考句子中的某些词替换为模型的预测词的方法(scheduled sampling)[3]。但替换不同的词对模型性能的影响不同,该方法没有包含一个选择更加合适的被替换的词的策略。
7、综上所述,现有的视觉叙事文本生成方法中视觉叙事词语的预测效果较差。
8、参考文献:
9、[1]hu j,cheng y,gan z,et al.what makes a good story?designingcomposite rewards for visual storytelling[c]//proceedings of the aaaiconference on artificial intelligence.2020,34(05):7969-7976.
10、[2]lu j,xiong c,parikh d,et al.knowing when to look:adaptiveattention via a visual sentinel for image captioning[c]//proceedings of theieee conference on computer vision and pattern recognition.2017:375-383.
11、[3]bengio s,vinyals o,jaitly n,et al.scheduled sampling for sequenceprediction with recurrent neural networks[j].advances in neural informationprocessing systems,2015,28.
12、[4]papineni k,roukos s,ward t,et al.bleu:a method for automaticevaluation of machine translation[c]//proceedings of the 40th annual meetingof the association for computational linguistics.2002:311-318.
13、[5]lin c y,och f j.automatic evaluation of machine translationquality using longest common subsequence and skip-bigram statistics[c]//proceedings of the 42nd annual meeting of the association for computationallinguistics(acl-04).2004:605-612.
14、[6]denkowski m,lavie a.meteor universal:language specific translationevaluation for any targe tlanguage[c]//proceedings of the ninth workshop onstatistical machine translation.2014:376-380.
15、[7]vedantam r,lawrence zitnick c,parikh d.cider:consensus-based imagedescription evaluation[c]//proceedings of the ieee conference on computervision and pattern recognition.2015:4566-4575.
16、[8]wang x,chen w,wang y f,et al.no metrics are perfect:adversarialreward learning for visual storytelling[j].arxiv preprint arxiv:1804.09160,2018.
17、[9]huang q,gan z,celikyilmaz a,et al.hierarchically structuredreinforcement learning for topically coherent visual story generation[c]//proceedings of the aaai conference on artificial intelligence.2019,33(01):8465-8472.
18、[10]jung y,kim d,woo s,et al.hide-and-tell:learning to bridge photostreams for visual storytelling[c]//proceedings of the aaai conference onartificial intelligence.2020,34(07):11213-11220.
19、[11]wang r,wei z,li p,et al.storytelling from an image stream usingscene graphs[c]//proceedings of the aaai conference on artificialintelligence.2020,34(05):9185-9192.
20、[12]xu c,yang m,li c,et al.imagine,reason and write:visualstorytelling with graph knowledge and relational reasoning[c]//proceedings ofthe aaai conference on artificial intelligence.2021,35(4):3022-3029.
21、[13]hsu c y,chu y w,huang t h k,et al.plot and rework:modelingstorylines for visual storytelling[j].arxiv preprintarxiv:2105.06950,2021.
技术实现思路
1、本发明的目的在于解决现有的视觉叙事文本生成方法中视觉叙事词语的预测效果较差的技术问题,提供一种视觉叙事文本生成方法及设备。
2、为实现上述目的,本发明采用以下技术方案:
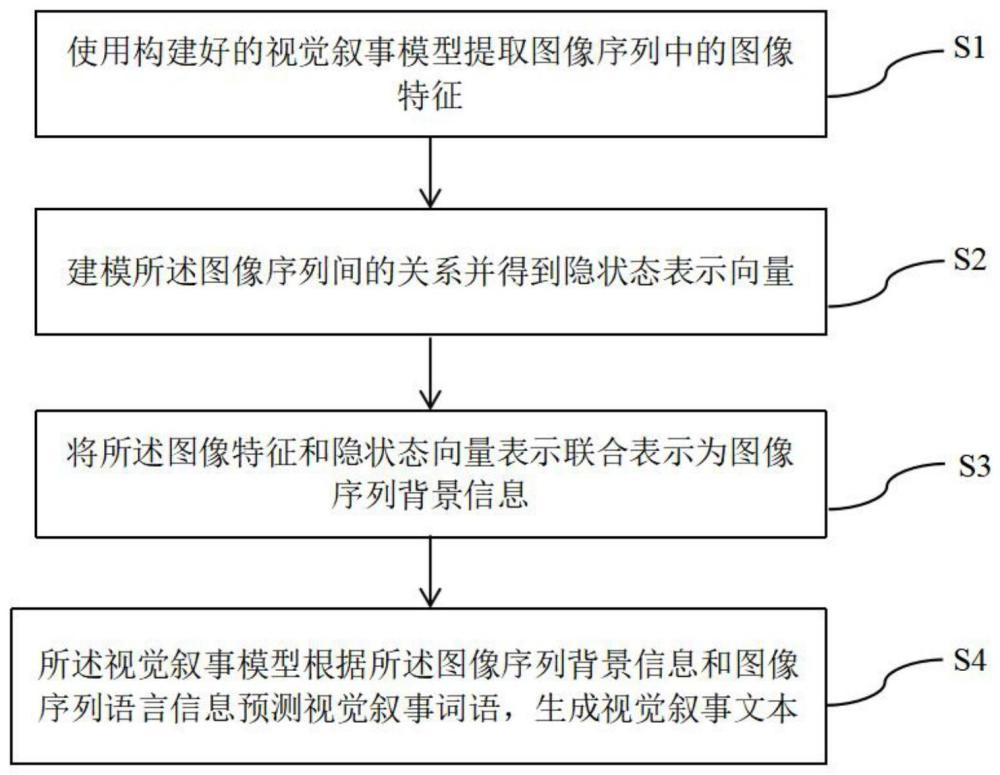
3、一种视觉叙事文本生成方法,包括以下步骤:s1:使用构建好的视觉叙事模型提取图像序列中的图像特征;s2:建模所述图像序列间的关系并得到隐状态表示向量;s3:将所述图像特征和管理器隐状态联合表示为图像序列背景信息;s4:所述视觉叙事模型根据所述图像序列背景信息和图像序列语言信息预测视觉叙事词语,生成视觉叙事文本。
4、在本发明的一些实施例中,在步骤s4中,所述图像序列语言信息包括隐状态信息、记忆单元信息和词向量;在预测视觉叙事词语时,对所述图像序列背景信息和所述其他不同信息分配不同的注意力权重,所述注意力权重表达式如下:
5、w=softmax(g([en,t-1,hw,n,t-1,cn,t-1]))
6、其中,en,t-1表示上一步预测的视觉叙事词语的词向量,hw,n,t-1表示上一步预测的隐状态,cn,t-1表示上一步的记忆单元,g表示不带偏置的线性层。
7、在本发明的一些实施例中,所述视觉叙事模型包括自适应输出门lstm,所述自适应输出门lstm的输入为上一步预测的隐状态表示向量、上一步的记忆单元、上一步预测的视觉叙事词语的词向量以及上一步的图像序列背景信息;所述自适应输出门lstm的输出为输出门向量,所述输出门向量的表达式如下:
8、o=σ(w|l1(hw,n,t-1);l2(cn,t-1);l3(an);l4(en,t-1)])
9、其中,σ表示sigmoid函数,l1,l2,l3,l4表示自适应输出门lstm中的线性层,an表示所述图像序列背景信息。
10、在本发明的一些实施例中,还包括使用主动替换采样方法训练所述视觉叙事模型,在所述训练过程中,使用选择网络和选择策略主动选择合适的预测词语作为所述预测视觉叙事词语,以替换参考句中的参考词语,所述选择网络用于估计替换每一个词对损失的影响程度。
11、在本发明的一些实施例中,所述主动替换采样方法包括以下步骤:
12、a1:通过教师强化方法对所述视觉叙事模型第一阶段训练,使所述视觉叙事模型的预测视觉叙事词语接近参考句中的参考词语,验证第一阶段训练的损失至少连续两次大于历史最低损失时执行步骤a2;
13、a2:使用可微分方法近似替换过程对所述选择网络进行第二阶段训练,验证第二阶段训练的损失至少连续两次大于历史最低损失时执行步骤a3;a3:使用训练好的所述选择网络的参数结合所述选择策略选择所述预测视觉叙事词语以替换参考句中的参考词语,对所述视觉叙事模型进行第三阶段训练,所述选择策略为选择对所述视觉叙事模型损失提升最大的预测视觉叙事词语进行替换参考句中的参考词语。
14、在本发明的一些实施例中,在步骤a1中,所述第一阶段训练的损失函数表达式如下:
15、
16、其中,n表示图像序列中的图像个数,t表示相应句子的词数,θ表示所述lstm模型参数,表示所述参考词语,zn表示除第n个参考句外的其他信息。
17、在本发明的一些实施例中,在步骤a2中,所述第二阶段训练的损失函数表达式如下:
18、
19、其中,t表示相应句子的词数,γ表示所述选择网络的参数,表示估计的替换结果。
20、在本发明的一些实施例中,在步骤a3中,第三阶段训练的损失函数表达式如下:
21、
22、其中,表示输入到所述视觉叙事模型中的单词,表示第n张图片所对应的时刻1到时刻t-1共t-1个单词来预测第t个单词。
23、本发明还提出一种视觉叙事文本生成设备,包括处理器、存储器以及存储在所述存储器中且被配置为由所述处理器执行的计算机程序,所述处理器执行所述计算机程序时实现如上任意一项所述的视觉叙事文本生成方法。
24、本发明还提出一种存储介质,所述存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述存储介质所在设备执行如上任意一项所述的视觉叙事文本生成方法。
25、本发明具有如下有益效果:
26、本发明提出的视觉叙事文本生成方法,通过构建视觉叙事模型提取图像序列中的图像特征和隐状态表示向量,联合表示为图像序列背景信息,再通过结合图像序列语言信息预测视觉叙事词语后,生成视觉叙事文本,除了关注图像序列背景信息外还结合了图像序列语言信息,能够提高视觉叙事词语的预测效果,从而使文本的句子之间具有较好的衔接性,能够构成一个流畅的故事,语言上期望生成的句子有更丰富的用词和更好的可读性。
27、此外,在一些实施例中,还具有如下有益效果:
28、通过自适应输出门lstm模型以加权和的形式对不同信息分配不同的注意力权重,能够选择更有助于预测的信息;通过主动替换采样训练方法,使用选择网络和选择策略进行主动选择,能够选择出更加合适的词进行替换,从而提升了lstm模型的性能,生成的叙述文本与参考故事文本之间的相似度更高。
29、本发明实施例中的其他有益效果将在下文中进一步述及。
- 还没有人留言评论。精彩留言会获得点赞!