一种基于K近邻算法提高否定选择算法检测率的方法
本发明涉及网络异常检测,具体为一种基于k近邻算法提高否定选择算法检测率的方法。
背景技术:
1、否定选择算法分为训练和检测两个阶段,如图1所示。在训练阶段,随机生成的候选检测器与训练集中自体进行耐受,删除那些识别自体的候选检测器,以避免成熟检测器识别自体。只有那些不识别任意自体的候选检测器才能最终成为成熟检测器,被加入成熟检测器集中,用于检测阶段对待测样本进行检测。在检测阶段,待测试样本与成熟检测器集中的检测器进行耐受测试。若待测试样本被任意检测器覆盖,则被标记为非自体。若待测样本未被任意检测器覆盖,则被标记为自体。
2、孔洞是成熟检测器集合未能覆盖的特征空间区域,是导致算法性能下降的根本原因。为缓解孔洞问题,现有技术主要通过优化检测器分布、改变检测器生成规则、检测器和自体半径可变、改变检测器形状等方式。这些方法的主要目标是使得检测器集对特征空间的覆盖最大化、孔洞覆盖最小化,从而减轻孔洞带来的影响。
3、孔洞中包括自体样本和非自体样本,而根据否定选择算法分类规则:被检测器覆盖的为非自体,未被检测器覆盖的为自体。由于孔洞未被检测器覆盖,孔洞中所有样本都将被分类为自体,导致孔洞中非自体样本被错误分类为自体,从而带来漏报问题,使得算法检测率下降。因此,孔洞中非自体被错分为自体才是孔洞问题导致性能下降的根本原因。
技术实现思路
1、本发明的目的在于提供一种基于k近邻算法提高否定选择算法检测率的方法,以缓解否定选择算法孔洞问题,减轻孔洞对算法带来的影响,从而降低漏报率,提升检测率。
2、为实现上述目的,本发明提供如下技术方案:
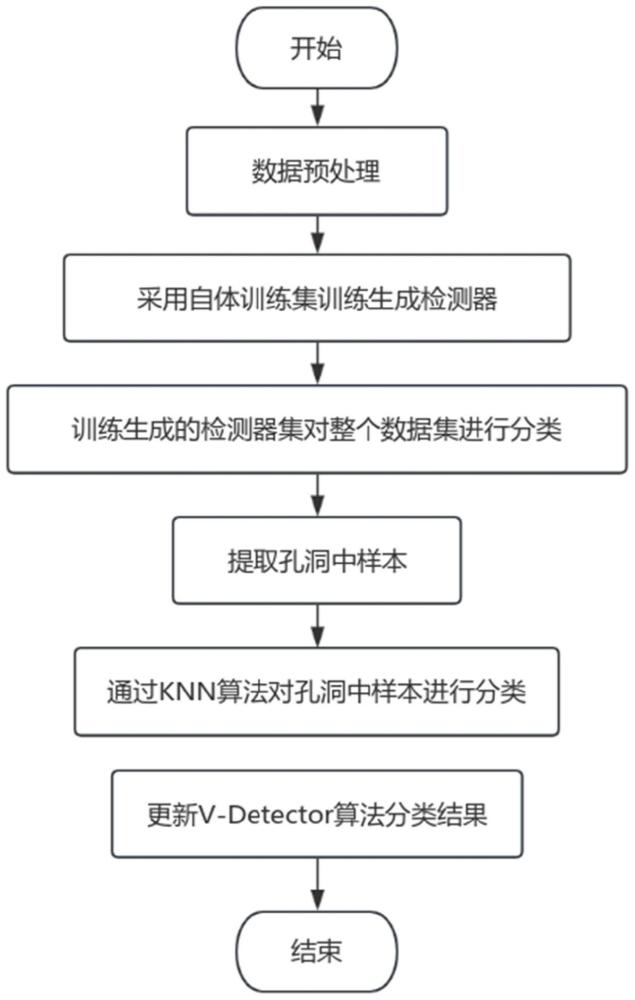
3、一种基于k近邻算法提高否定选择算法检测率的方法,包括以下步骤:
4、s1.数据预处理:导入n维数据集d,该维度不包括数据集的类别标签属性,所述数据集d包括数字和符号特征,因此需要先对符号特征进行数字化处理,然后再对所有特征归一化处理;采用交叉验证法k-fold将数据集d划分为训练集和测试集;
5、s2.v-detector算法检测:使用v-detector算法训练生成检测器,训练时淘汰覆盖任意自体的候选检测器,并将生成的检测器集合用于对整个数据集d进行分类,将其分为自体集和非自体集;
6、s3.提取孔洞中样本数据:理论上,孔洞中数据为数据集d中的真实非自体集nonself与被v-detector算法标记为非自体的样本集label_noself的差集,由于孔洞中非自体被错分为自体,因此使用被v-detector算法标记为自体的样本集label_self与训练自体集self_train的差集代替;
7、s4.通过knn算法对孔洞中被v-detector算法标记为自体的样本集label_self和训练自体集self_train的差集进行分类,并对v-detector算法分类结果进行更新;
8、s5.统计性能指标,包括误报率和漏报率等。
9、优选的,s1中,所述归一化处理的计算表达式为:
10、
11、式中,x为归一化前的数值,x′为归一化后的数值,max(x)和min(x)分别为所在属性的最大值和最小值;
12、所述交叉验证法k-fold将数据集d划分为k-1份训练集和1份测试集。
13、优选的,s2包括以下步骤:
14、s21.参数设置,包括自体半径r,期望覆盖率pexp,最大自体覆盖率msc,检测器最大数量max;
15、s22.在n维特征空间随机生成候选检测器,遍历成熟检测器集,计算候选检测器与成熟检测器的欧几里得距离;
16、s23.第一次耐受过程:候选检测器与现有成熟检测器耐受,若检测器集中已有成熟检测器,则候选检测器必须先与成熟检测器进行耐受,删除被现有成熟检测器覆盖的候选检测器;若候选检测器不被任意成熟检测器覆盖,则成功通过第一次耐受过程;
17、s24.第二次耐受过程:候选检测器与自体进行耐受,成功经历第一次耐受过程的候选检测器与自体进行耐受,删除覆盖自体的候选检测器,以避免检测器识别自体。
18、s25.采用检测器集合对数据集d进行分类,将数据集d分类为自体集label_self和非自体集label_nonself两部分。
19、优选的,所述第一次耐受过程的计算方法为:
20、计算候选检测器中心与成熟检测器中心的欧几里得距离,若该距离小于成熟检测器的半径,表明候选检测器已被成熟检测器覆盖,增加覆盖计数(随机采样次数)t,并将候选检测器标记为不可用。
21、优选的,所述第二次耐受过程的计算方法为:
22、计算候选检测器中心与训练集中自体中心的欧几里得距离,并将候选检测器到最近邻自体的欧几里得距离记作min;若min>r,则将最小距离与自体半径r的差值min-r作为半径来生成成熟检测器;若min≤r,则表明该候选检测器中心被自体覆盖,删除该候选检测器。
23、优选的,n维特征空间下的点x=(x1,x2,…xn)和y=(y1,y2,…yn)之间的欧几里得距离的计算表达式为:
24、
25、优选的,v-detector算法的终止条件包括:
26、①生成的检测器数量达到预设值max;
27、②检测器集合对非自体空间的覆盖已达到期望覆盖率pexp:
28、t≥1/(1-pexp) (3);
29、式中,t为随机采样次数;
30、③已达到对自体的最大覆盖率msc。
31、优选的,理论上,s3中孔洞中样本数据的提取包括以下两种方法:
32、1)孔洞中的非自体是真实自体集nonself中的元素集合,但不是v-detector算法标记为非自体集label_noself中的元素,计算真实非自体集和标记的非自体集的差集,即,nonself\label_noself;
33、2)计算v-detector标记的自体集label_self与真实自体集self的差集,即,label_self\self;
34、nonself\label_noself和label_self\self是相等的,即,
35、nonself\label_nonself=label_self\self (4)。
36、与现有技术相比,本发明的有益效果是:
37、1.否定选择算法中,孔洞容易在自体和非自体之间的边界区域形成,其原因是自体边界不规则,而检测器需要在不覆盖自体的前提下尽量覆盖更大的非自体空间。相比其它算法,本发明更适合对类域边界的实例进行分类。
38、2.本发明基于knn算法来对孔洞中样本进行分类,孔洞中样本使用v-detector算法标记为自体的样本集label_self与训练自体集self_train的差集,以降低漏报率,提高检测率。
- 还没有人留言评论。精彩留言会获得点赞!