一种基于大模型的商标生成方法及系统与流程
本发明涉及自然语言处理,具体涉及一种基于大模型的生成商标的方法及系统。
背景技术:
1、我国的商标申请量逐年提升,单2022年,我国的商标申请量就已经达到了751.6万件,从如此大量的商标申请量也验证了人们对商标名称的需求也逐步的提升,而一个能符合用户心意的商标名称往往是用户所期待的。商标起名需求强烈,同时商标起名也是比较困难的,同时满足用户的各种限制条件以及让用户满意的商标名称往往需要起名人绞尽脑汁才想的出来,但又不能保证起出来的商标名称另用户足够满意,因此一个商标自动起名的系统可以极大的缓解起名人针对于各种限制条件的难度。
2、目前商标起名的模式大多都是人工起名,可能是用户自己根据自己的想法起名,也可能是用户将自己的需求提给代理机构,由代理机构进行起名,有时候用户的限制比较多,可能最后绞尽脑汁也没办法符合全部条件想出一个比较满意的名字。而商标又可分成45个类别,每种类别的商标又有着独属于本类别的商标风格,这又增加了商标起名的难度。此外,在商标起名的过程中,对应的名称最好还包含一个解释说明,来解释所起的名字有哪些好的含义,从而更加方便用户挑选。
技术实现思路
1、为此,本发明提出了一种基于大模型的商标生成方法,目的是尽可能多的结合用户的意图,起出让用户满意且符合用户意图的商标名字。此外还可以通过系统生成的商标再次采用大模型生成出与该商标名有关的解释说明。
2、为了实现上述目的,本发明提供如下技术方案:
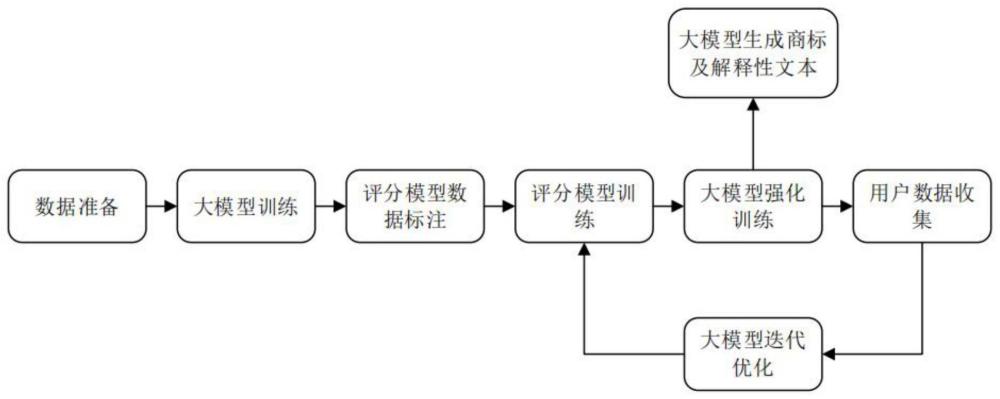
3、本发明第一方面提供了一种基于大模型的商标生成方法,包括训练数据构建、大模型的训练、评分模型的训练、大模型强化训练和大模型生成商标的步骤,其中,
4、步骤一、所述训练数据构建为收集商标生成任务的训练数据集,所述训练数据集包括:第一训练数据为商标要求,第一训练数据的标签为符合该要求的商标名称;第二训练数据为商标名称,第二训练数据的标签为该商标名称的解释性文本内容;所述任务包括第一个任务是通过商标的要求文本内容生成符合要求的商标和第二个任务是给定一个商标名称生成当前商标的解释性文本;
5、步骤二、所述大模型的训练为将所获取到的训练数据融合在一起,按照预定比例的数据比例占比,将所述第一训练数据与所述第二训练数据结合在一起,送至大模型进行训练;
6、步骤三、评分模型的训练为基于训练后的大模型,依据所述两个任务分别在同样的指令下生成若干条数据,对所述若干条数据进行标注、排名;通过标注的排序数据,进行训练,从而得到给定的一个输入,如果该输入更加偏向于人的偏好,则给出更高的分数;
7、步骤四、大模型强化训练为配合训练好的所述评分模型,再次使用第一次大模型训练时的数据,使大模型通过对应的指令生成对应的商标名称,所述评分模型对所述商标名称进行评分,使大模型生成出的结果在评分模型部分获得更高的分数;
8、步骤五、商标名及文本生成:在商标名及文本生成阶段,将用户的需求进行整理以及处理,形成与训练阶段训练数据输入格式一致的指令,将该指令送至大模型当中,从而生成对应的商标名称;将所生成的商标名称再次以训练阶段相同的数据输入指令送入至大模型,使得大模型生成该商标名称的解释性文本内容;
9、步骤六、用户数据再收集、模型再训练:模型上线后,收集用户挑选的数据,当用户挑选的数据进一步积累到预定程度,将该部分数据融合至最开始的训练语料当中,再次进行评分模型训练,进行大模型的二次训练,以更新大模型。
10、更适宜地,该商标生成方法,还包括:
11、在所述大模型真实部署服务,收集更多的用户数据,所述用户数据包括用户的真实需求文本,用户最终选取的商标名称,与用户选取商标名称时同一批大模型生成出的其他次选商标名。
12、更适宜地,该商标生成方法,还包括所述大模型优化迭代的步骤:
13、待用户真实数据收集达到预定的量,使用所述数据集重新进行评分模型训练、大模型重新训练。
14、优选地,该商标生成方法中,还包括:
15、将训练好的所述评分模型作为控制信号,作为大模型损失函数的一部分,使得大模型生成的结果更加偏向于评分模型给出高分;
16、在评分模型作为控制条件的前提下,加入一个再训练的大模型和初始训练的大模型的距离,该距离用kl散度来计算,将评分模型得到的结果与kl散度结合在一起成为步骤五大模型强化训练的新的损失函数。
17、
18、其中r(x,y)是评分模型根据当前指令x,与当前大模型生成的结果y所评估的分数,β为调整系数,pθ-new(y∣x)为步骤五中新的大模型给定指令x,生成对应y的概率,而θ-new为此阶段模型需要更新的参数,pθ-raw(y∣x)为步骤二中大模型根据指定x生成对应y的概率,θ-raw为所述步骤三中大模型的原始权重参数,其中为kl散度;为的期望值,且为此部分的训练目标。
19、优选地,在所述步骤一中,采取以下策略构建训练数据集:
20、步骤(1):先统计用户可能会提出的商标名称需求点,获取到用户真实情况下的需求点;
21、商标名称长度;商标包含某个字;所申请商标属于某个商标类;商标附有的含义;
22、每个需求点可与其他需求点随机组合;
23、步骤(2):基于每个需求点出现的可能性,基于人为先验知识对所述可能性人设定一个概率值,在进行生成训练数据时,根据每个需求点可能出现的概率值,随机生成对应的需求。
24、优选地,在所述步骤二的训练过程中,通过任务的难度对数据集的比例进行调整,从而使模型在所述两个任务上效果均衡;
25、所用大模型为chatglm或baichuan;和/或
26、采用lora的方式所述对所述大模型进行微调。
27、优选地,在所述步骤三中,所述通过标注的排序数据,进行训练,从而得到给定的一个输入,如果该输入更加偏向于人的偏好,则给出更高的分数,具体为:
28、以一个指令x生成了三个指令y1,y2,y3,并且生成的结果经过人工排序后由好到坏的排序为y1>y2>y3,指定该评分模型依据于给定指令x,和输出y的分值为r(x,y),则该评分模型的训练目标为经过模型训练后使模型对排序靠前的分值与排序靠后的分值的差值grade大于预定值,
29、grade=r(x,y1)-r(x,y2)+r(x,y1)-r(x,y3)+r(x,y2)-r(x,y3);
30、以深度学习模型损失函数loss的形式来表示:
31、
32、其中yw,和yl代表的是排序靠前的商标yw和排序靠后的商标yl,σ为sigmoid函数,是将一个指令x对应不同的生成情况均做分值差以及分差加和的运算。
33、本发明另一方面还提供了一种基于大模型的商标生成系统,包括:训练数据构建模块、大模型训练模块和商标生成模块,其中,
34、所述训练数据构建模块,用于收集商标生成任务的训练数据集,所述训练数据集包括:第一训练数据为商标要求,第一训练数据的标签为符合该要求的商标名称;第二训练数据为商标名称,第二训练数据的标签为该商标名称的解释性文本内容;所述任务包括第一个任务是通过商标的要求文本内容生成符合要求的商标和第二个任务是给定一个商标名称生成当前商标的解释性文本;
35、所述大模型训练模块,用于将所获取到的训练数据融合在一起,按照预定比例的数据比例占比,将所述第一训练数据与所述第二训练数据结合在一起,送至大模型进行训练;用于基于训练后的大模型,依据所述两个任务分别在同样的指令下生成若干条数据,对所述若干条数据进行标注、排名;通过标注的排序数据,进行训练,从而得到给定的一个输入,如果该输入更加偏向于人的偏好,则给出更高的分数;
36、所述大模型训练模块还用于配合训练好的所述评分模型,再次使用第一次大模型训练时的数据,使大模型通过对应的指令生成对应的商标名称,所述评分模型对所述商标名称进行评分,使大模型生成出的结果在评分模型部分获得更高的分数;
37、所述商标生成模块,用于在商标名及文本生成阶段,将用户的需求进行整理以及处理,形成与训练阶段训练数据输入格式一致的指令,将该指令送至大模型当中,从而生成对应的商标名称;将所生成的商标名称再次以训练阶段相同的数据输入指令送入至大模型,使得大模型生成该商标名称的解释性文本内容;
38、模型上线后,收集用户挑选的数据,当用户挑选的数据进一步积累到预定程度,将该部分数据融合至最开始的训练语料当中,所述大模型训练模块再次进行评分模型训练,进行大模型的二次训练,以更新大模型。
39、本发明具有如下有益效果:
40、本发明提供的一种基于大模型的商标生成方法及系统,可以真实的模拟用户的需求,在训练数据构建阶段尽可能多的生成各种情况的需求指令,此外模型还可以生成出用户满意的商标名称以及对应的商标解释性文本,让用户更加清楚该商标的优秀之处。此外该系统结合了用户的偏好数据,训练了基于用户偏好的评分模型控制大模型生成出用户更加喜欢的商标名称。同时还会不断的收集用户选取商标的数据,不断的对大模型进行迭代优化,逐步提升大模型的效果,用户对模型生成出来的名称更加满意。解决了用户在进行商标起名时,起名困难,绞尽脑汁无法取到一个较为满意商标名的问题。
- 还没有人留言评论。精彩留言会获得点赞!