一种基于强化学习的人力资源分配方法、系统及电子设备与流程
本申请涉及任务调度分配,尤其是涉及一种基于强化学习的人力资源分配方法、系统及电子设备。
背景技术:
1、人才是维持一个企业竞争力的关键,人力资源管理是指在具体的组织或企业中,为了提高工作效率、实现人力资源的最优化,并对组织或企业的人资资源进行科学、合理的管理。在项目中,控制人力成本是一个很重要的模块,而想要做好人力成本的控制,则需要做到人尽其才、才尽其用,人事相宜,最大限度的发挥人力资源的作用。现有的人力资源分配大多采用经验化分配方式,虽然不少企业也采用了人力考核评估方法,但是由于评估主体是人,受到的局限性也很强,且分配时难免受主观意愿的影响。基于经验化分配方式作出的人力成本评估方法也难以达到较优的效果,即通常基于经验和统计数据,但往往难以充分考虑项目中的各种变化和不确定性因素。
技术实现思路
1、为了提高项目分配的准确度和效率,本申请提供一种基于强化学习的人力资源分配方法、系统及电子设备。
2、第一方面,本申请提供一种基于强化学习的人力资源分配方法,采用如下的技术方案:
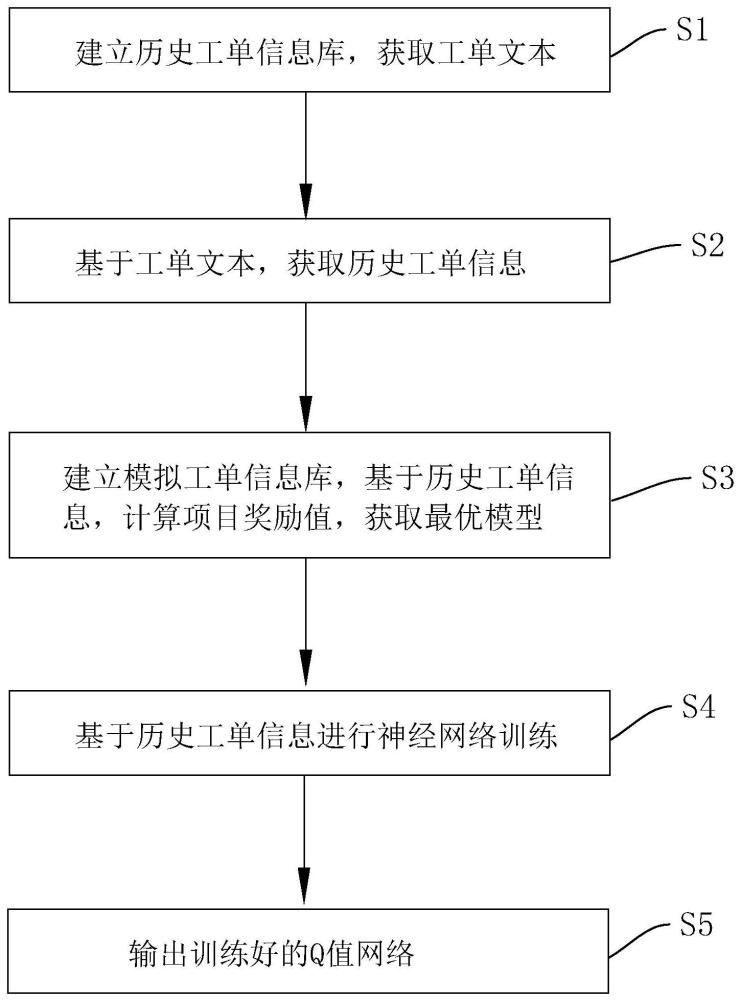
3、一种基于强化学习的人力资源分配方法,包括以下步骤:
4、s1、建立历史工单信息库,获取工单文本;
5、s2、基于工单文本,获取历史工单信息;所述历史工单信息包括项目数据和人员数据;
6、s3、建立模拟工单信息库,基于历史工单信息,计算项目奖励值,获取最优模型;具体地,
7、s301、基于人员数据,获取项目动作集合;
8、s302、基于模拟工单信息库,获取项目状态集合;
9、s303、获取历史工单信息,基于项目动作集合和项目状态集合,计算项目奖励值;
10、s304、基于项目奖励值,设置项目状态-动作函数,获取最优模型;
11、s4、基于历史工单信息进行神经网络训练;
12、s5、输出训练好的q值网络。
13、通过建立历史工单信息库,从历史工单信息库中获取历史工单样本,利用历史工单信息对神经网络模型进行训练,从而得到优化模型;同时为了防止任务分配的时候,部分人员被过多的分配任务量而部分人员未被分配任务或被分配的任务量很少的情况发生,通过获取项目动作集合和项目状态集合,通过项目动作集合和项目状态集合,从而计算项目奖励值,根据项目奖励值对模型进行优化,使得任务分配时的准确性更高,分配方式更加合理。
14、优选地,所述基于工单文本,获取历史工单信息,包括以下步骤:
15、根据脚本标签,获取作业数据和员工信息;
16、利用作业数据,生成项目数据;
17、利用员工信息,生成人员数据。
18、优选地,所述基于工单文本,获取历史工单信息,还包括以下步骤:
19、基于项目数据和人员数据,计算员工按时完成率;所述员工按时完成率通过公式p=fj/aj计算,其中,fj是被计算员工的按时完成的任务数量,aj是被计算员工的任务总数。
20、优选地,所述基于工单文本,获取历史工单信息,还包括以下步骤:
21、基于作业数据,计算员工与任务的匹配结果;所述匹配结果的判断条件包括员工条件判断和任务完成情况判断。
22、优选地,所述项目奖励值的计算公式为:r=w*(1/var);其中,w为未修正的项目奖励值;var为项目方差;
23、所述未修正的项目奖励值w的计算公式如下:w=jl*ni*jpi,其中,jl为任务难度值;ni为动作状态i情况下,员工i的按时完成率;jpi为任务与员工i匹配取1,不匹配取-1;动作状态i由贪婪算法随机生成;
24、所述项目方差的计算公式如下:var=1/k*sum(si-sb)^2;其中,sb为项目状态集的期望值,k为员工总数,si为员工i当前时间手上的任务数量。
25、优选地,所述项目状态-动作函数公式如下:其中,qπ(s,n)表征为在任务分配策略π下项目奖励函数的累计回报;所述最优模型表征为在项目分配策略π’下项目奖励函数的累计回报最大,π’=argmaxqπ(s,n)。
26、优选地,所述基于历史工单信息进行神经网络训练,包括以下步骤:
27、s401、初始化q值网络、策略网络、目标q值网络和经验回放池;
28、s402、对于后续的每次训练,均执行如下步骤:
29、s4021、获取当前状态,根据当前q值网络选择动作值,更新项目状态集;
30、s4022、将更新后的项目状态集存储到经验回放池;
31、s403、从经验回放池中随机抽取n个样本数据,对每个样本数据,计算目标q值函数;
32、s404、最小化目标损失函数,更新当前网络和目标网络。
33、优选地,所述目标q值函数采用如下公式:qi=ri+αmaxqv-(si+1,n);其中ri为i状态下,项目奖励值,qv-(si+1,n)为目标q值网络,α为折扣因子,取值范围为[0,1]。
34、第二方面,本申请提供一种应用上述人力资源匹配方法的系统,采用如下的技术方案:
35、一种人力资源分配系统,包括,
36、获取单元,用于建立历史工单信息库,获取工单文本;
37、提取单元,用于对工单文本进行解析,提取工单文本中所包含的历史工单信息;
38、计算优化单元,用于建立模型工单信息库,基于历史工单信息,计算项目奖励值,获取最优模型;
39、训练单元,用于利用历史工单信息进行神经网络训练;
40、输出单元,用于输出训练好的q值网络。
41、第三方面,本申请提供一种电子设备,包括处理器和存储器,所述存储器用于存储可执行指令,所述处理器用于通过调用所述可执行指令,执行上述人力资源分配方法。
技术特征:
1.一种基于强化学习的人力资源分配方法,其特征在于:包括以下步骤:
2.根据权利要求1所述的基于强化学习的人力资源分配方法,其特征在于:所述基于工单文本,获取历史工单信息,包括以下步骤:
3.根据权利要求2所述的基于强化学习的人力资源分配方法,其特征在于:所述基于工单文本,获取历史工单信息,还包括以下步骤:
4.根据权利要求2所述的基于强化学习的人力资源分配方法,其特征在于:所述基于工单文本,获取历史工单信息,还包括以下步骤:
5.根据权利要求4所述的基于强化学习的人力资源分配方法,其特征在于:所述项目奖励值的计算公式为:r=w*(1/var);其中,w为未修正的项目奖励值;var为项目方差;
6.根据权利要求5所述的基于强化学习的人力资源分配方法,其特征在于:所述项目状态-动作函数公式如下:其中,qπ(s,n)表征为在任务分配策略π下项目奖励函数的累计回报;所述最优模型表征为在项目分配策略π’下项目奖励函数的累计回报最大,π’=argmaxqπ(s,n)。
7.根据权利要求1所述的基于强化学习的人力资源分配方法,其特征在于:所述基于历史工单信息进行神经网络训练,包括以下步骤:
8.根据权利要求7所述的基于强化学习的人力资源分配方法,其特征在于:所述目标q值函数采用如下公式:qi=ri+αmaxqv-(si+1,n);其中ri为i状态下,项目奖励值,qv-(si+1,n)为目标q值网络,α为折扣因子,取值范围为[0,1]。
9.一种人力资源分配系统,其特征在于:包括,
10.一种电子设备,其特征在于:包括处理器(100)和存储器(200),所述存储器(200)用于存储可执行指令,所述处理器(100)用于通过调用所述可执行指令,执行权利要求1-8中任一项所述的人力资源分配方法。
技术总结
本申请涉及一种基于强化学习的人力资源分配方法、系统及电子设备,其方法包括以下步骤:S1、建立历史工单信息库,获取工单文本;S2、基于工单文本,获取历史工单信息;所述历史工单信息包括项目数据和人员数据;S3、建立模拟工单信息库,基于历史工单信息,计算项目奖励值,获取最优模型;S301、基于人员数据,获取项目动作集合;S302、基于模拟工单信息库,获取项目状态集合;S303、获取历史工单信息,基于项目动作集合和项目状态集合,计算项目奖励值;S304、基于项目奖励值,设置项目状态‑动作函数,获取最优模型;S4、基于历史工单信息进行神经网络训练;S5、输出训练好的Q值网络。本申请具有提高项目分配准确性和项目分配效率的效果。
技术研发人员:高冲,严赟,庄明伟
受保护的技术使用者:嘉兴海视嘉安智城科技有限公司
技术研发日:
技术公布日:2024/3/11
- 还没有人留言评论。精彩留言会获得点赞!