一种基于多语言预训练大模型的伪语言族聚类方法及装置
本发明涉及机器翻译,特别是指一种基于多语言预训练大模型的伪语言族聚类方法及装置。
背景技术:
1、神经机器翻译(nmt)已成为学术研究和商业使用中主导的机器翻译(mt)范式。近年来研究发现nmt框架可以自然地整合多种语言。因此,涉及多种语言的mt系统的研究工作急剧增加。研究人员将处理多于一个语言对的翻译的nmt系统称为多语言nmt(mnmt)系统。mnmt研究的终极目标是通过有效利用可用的语言资源,开发一个用于尽可能多的语言之间翻译的单一模型。尽管mnmt在翻译质量方面带来了可喜的改进,但这些模型都依赖于大规模平行语料库。由于此类语料库仅存在于少数语言对上,因此在大多数低资源语言中,翻译性能远未达到预期效果。相关研究表明对于低资源语言翻译时,通过在微调阶段引入额外的辅助语言对,进行多语言协同训练,能够在某些情况下优于传统的微调方法。但是后续研究进一步指出,协同训练并不总是能够带来正面的效果,有时甚至可能导致翻译质量的下降,这取决于协同语言对的选择。
2、在近年来国内外的研究中表明,通过使用与目标语言相近的语言对对模型进行微调,可以在无需使用目标语言对的数据的情况下,提升目标语言对的翻译质量,进一步说明了语言对之间存在协同作用。但并非任意语言对的协同训练都能达到相同的效果,因此,协同语言对的筛选成为提升mnmt在低资源语言对翻译质量的关键步骤。语言族中的语言通常具有共同的地缘、语系背景,因此在字符或词语层面会有较多意义相近的地方,从语言学的角度而言,这些语言对之间会具有更多相同或者相近的字符、语法等语言学特征。目前该领域的学术研究主要分为两个方向:一方面,研究者通常会整合不同先验知识,包括语言相似性、资源可用性、语言类型和特定于任务的要求等;另一方面,研究者尝试应用语言嵌入,用嵌入向量表示每种语言,并将它们聚类在嵌入空间中,如在模型中增加语言嵌入(languageembedding)层,通过多语言训练后,为每个语言对构建嵌入向量,再通过层次聚类构建语言族,以提升语言对的翻译质量,或者在保持预训练模型参数不变的情况下,在模型的结构中嵌入适配器(adapter)结构,在下游任务中通过训练语言族adapter来提升翻译质量。
3、虽然这些方法能够提升语言对的翻译质量,但它们在实际应用中也面临着一定的困难。特别是训练新的模型或更改模型的结构,会使得这些方法变得复杂,并且在大语言模型原始结构和数据难以获取的情况下,这些方法也难以复现。
技术实现思路
1、为了解决现有技术存在的训练新的模型或更改模型的结构,会使得这些方法变得复杂,并且在大语言模型原始结构和数据难以获取的情况下,难以复现的技术问题,本发明实施例提供了一种基于多语言预训练大模型的伪语言族聚类方法及装置。所述技术方案如下:
2、一方面,提供了一种基于多语言预训练大模型的伪语言族聚类方法,该方法由基于多语言预训练大模型的伪语言族聚类设备实现,该方法包括:
3、s1、建立共享语言池;
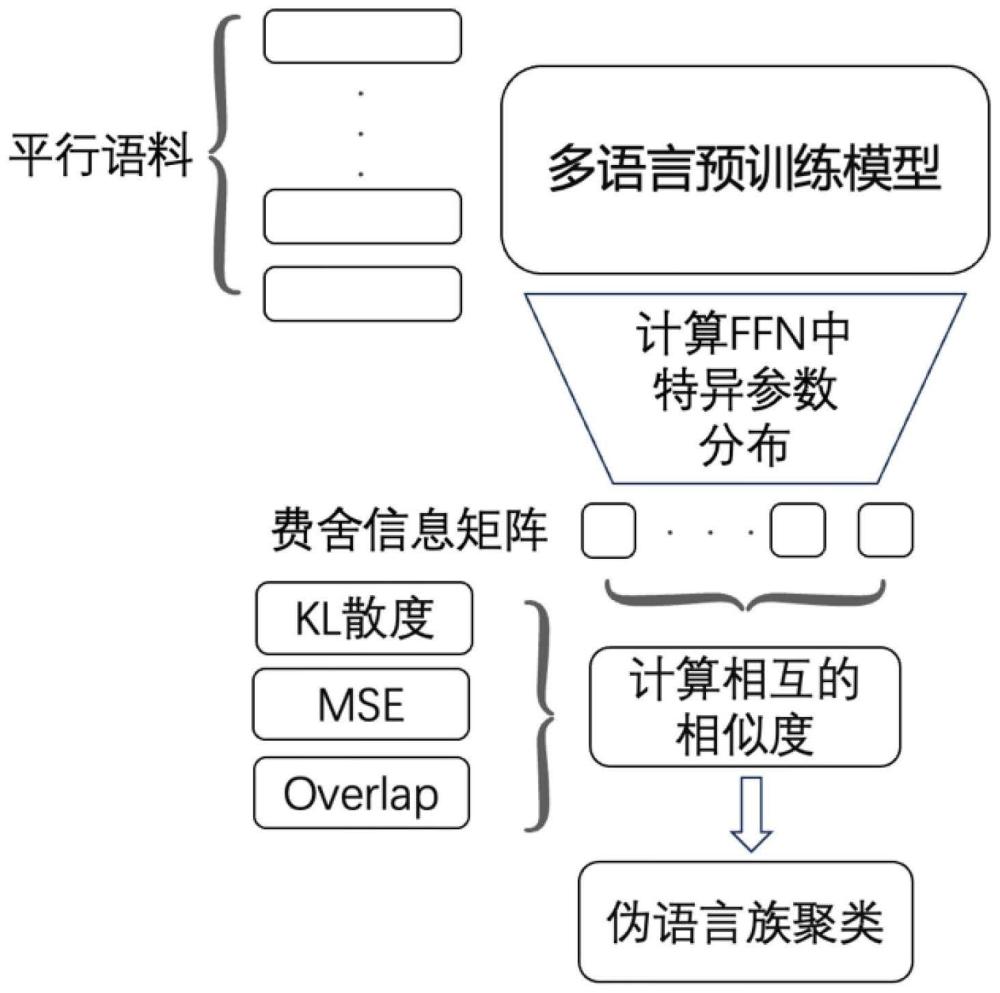
4、s2基于多语言预训练大模型,计算共享语言池中的语言对的费舍信息矩阵,获得共享语言池中的语言对的表征结果;
5、s3、根据表征结果对语言对之间的相似度进行计算,获得相似度值;
6、s4、根据相似度值,对语言对之间的相似性进行排序,根据预设边界值选择符合边界值的辅助语言对,完成基于多语言预训练大模型的伪语言族聚类。
7、可选地,步骤s1中,建立共享语言池,包括:
8、获取ted数据集;
9、提取ted数据集中的多种语言,将多种语言译成英语的语言对作为基础数据集,建立共享语言池。
10、可选地,步骤s2中,基于多语言预训练大模型,计算共享语言池中的语言对的费舍信息矩阵,获得共享语言池中的语言对的表征结果,包括:
11、获取与共享语言池中语言对对应的平行语料库,将平行语料库中的数据均等化分为j个小批量数据集;
12、将小批量数据集依次输入多语言预训练大模型,输出每个小批量数据集的费舍信息矩阵;
13、一个输入轮次后计算每个小批量数据集的平均费舍信息矩阵,将平均费舍信息矩阵作为估计值,获得每个小批量数据集的费舍信息权重;
14、根据费舍信息权重,对共享语言池中对应语言对的分布进行表征。
15、可选地,步骤s3中,根据表征结果对语言对之间的相似度进行计算,获得相似度值,包括:
16、获取表征结果;
17、采用均方误差法,计算目标语言对和辅助语言对之间的距离,距离与相近,相似度越高。
18、可选地,步骤s3中,根据表征结果对语言对之间的相似度进行计算,获得相似度值,包括:
19、使用费舍信息矩阵,计算辅助语言到目标语言的kl散度,获得目标语言对和辅助语言对之间的距离,距离与相近,相似度越高。
20、可选地,步骤s3中,根据表征结果对语言对之间的相似度进行计算,获得相似度值,包括:
21、选择前k的参数并为其分配值1,而其余参数分配值0来创建费舍信息掩码;
22、根据同时激活的参数数量和目标方向上激活的参数量,计算目标语言对和辅助语言对之间的距离,距离与相近,相似度越高。
23、可选地,步骤s4中,根据相似度值,对语言对之间的相似性进行排序,根据预设边界值选择符合边界值的辅助语言对,完成基于多语言预训练大模型的伪语言族聚类,包括:
24、遍历计算所有语言对之间的相似度;
25、根据语言对之间的相似度进行降序排列;
26、预设初始搜索半径,根据初始搜索半径划定边界范围;
27、将边界范围内,最接近的语言对整合到辅助语言名单中;
28、根据最新添加的语言对与目标语言对的相似性,更新搜索半径;
29、重复更新搜索半径,直至不再扩展新的语言对为止,获得聚类后的伪语言族,完成基于多语言预训练大模型的伪语言族聚类。
30、另一方面,提供了一种基于多语言预训练大模型的伪语言族聚类装置,该装置应用于基于多语言预训练大模型的伪语言族聚类方法,该装置包括:
31、语言池模块,用于建立共享语言池;
32、表征模块,用于基于多语言预训练大模型,计算共享语言池中的语言对的费舍信息矩阵,获得共享语言池中的语言对的表征结果;
33、相似度计算模块,用于根据表征结果对语言对之间的相似度进行计算,获得相似度值;
34、聚类模块,用于根据相似度值,对语言对之间的相似性进行排序,根据预设边界值选择符合边界值的辅助语言对,完成基于多语言预训练大模型的伪语言族聚类。
35、另一方面,提供一种基于多语言预训练大模型的伪语言族聚类设备,所述基于多语言预训练大模型的伪语言族聚类设备包括:处理器;存储器,所述存储器上存储有计算机可读指令,所述计算机可读指令被所述处理器执行时,实现如上述基于多语言预训练大模型的伪语言族聚类方法中的任一项方法。
36、另一方面,提供了一种计算机可读存储介质,所述存储介质中存储有至少一条指令,所述至少一条指令由处理器加载并执行以实现上述基于多语言预训练大模型的伪语言族聚类方法中的任一项方法。
37、本发明实施例提供的技术方案带来的有益效果至少包括:
38、本发明针对现有技术中存在的需要额外先验知识或者需要对模型架构进行修改的限制,本发明提供构建一种更有效的语言对聚类方法进行多语言协同训练的方法。核心目标是使用多语言预训练本身的能力对语言对进行表征,更有效地选择并聚类辅助语言并提高其在不同模型和数据集之间的泛化性,最终提高低资源语言对在多语言协同训练下的翻译质量。
- 还没有人留言评论。精彩留言会获得点赞!