数据分类方法、数据资产管理平台、装置、设备及介质与流程
本技术涉及数据识别,具体涉及数据分类方法、数据资产管理平台、装置、设备及介质。
背景技术:
1、数据资产管理指规划、控制和提供数据及信息资产的一组业务职能,包括开发,执行和监督有关数据的计划,政策,方案,项目,流程,方法和程序,从而控制、保护、交付和提高数据资产的价值以给组织以及企业带来经济利益。那么,在进行数据资产管理时对不同类型数据库中不同数据结构的数据进行识别以及分类就显得尤为重要。
2、传统的数据分类方法在面对半结构化数据以及非结构化数据,也即较为复杂的数据时,往往存在识别率低以及准确性差,甚至有无法识别数据以对数据进行分类的情况。
3、因此,如何实现对不同数据结构的数据进行准确的分类已成为亟需解决的问题。
技术实现思路
1、有鉴于此,本技术提供了一种数据分类方法、数据资产管理平台、装置、设备及介质,以解决如何实现对不同数据结构的数据进行准确的分类的问题。
2、第一方面,本技术提供了一种数据分类方法,应用于数据资产管理平台,方法包括:
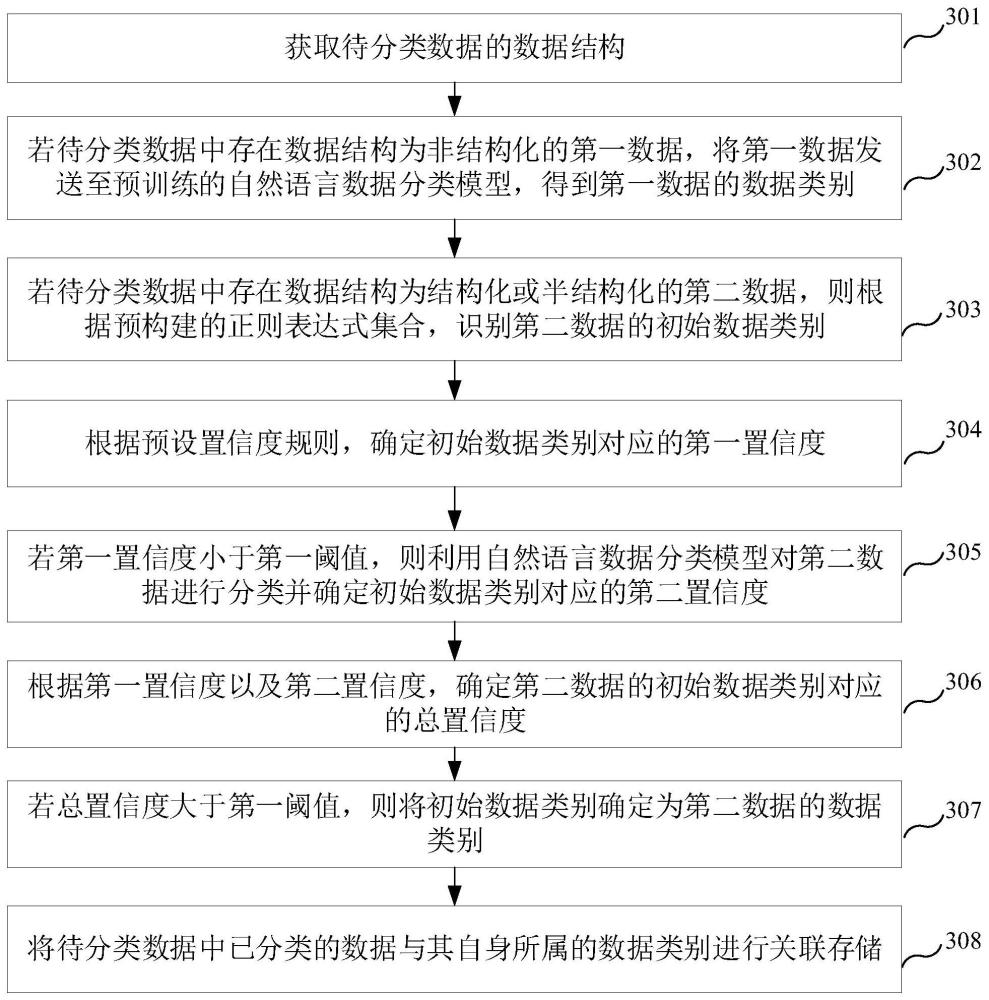
3、获取待分类数据的数据结构;
4、若待分类数据中存在数据结构为非结构化的第一数据,将第一数据发送至预训练的自然语言数据分类模型,得到第一数据的数据类别;
5、若待分类数据中存在数据结构为结构化或半结构化的第二数据,则根据预构建的正则表达式集合,识别第二数据的初始数据类别;
6、根据预设置信度规则,确定初始数据类别对应的第一置信度;
7、若第一置信度小于第一阈值,则利用自然语言数据分类模型对第二数据分类并确定初始数据类别对应的第二置信度;
8、根据第一置信度以及第二置信度,确定第二数据的初始数据类别对应的总置信度;
9、若总置信度大于第一阈值,则将初始数据类别确定为第二数据的数据类别;
10、将待分类数据中已分类的数据与其自身所属的数据类别进行关联存储。
11、上述技术方案中,利用具有复杂数据处理能力且准确性较高的自然语言数据分类模型对复杂的非结构化的数据进行分类,提高了对复杂的非结构化数据分类的准确性。此外,在利用正则表达式集合分类半结构化或结构化数据时,引入数据类别对应的置信度的计算,通过置信度来确定数据类别的分类是否可靠,提高了对半结构化或结构化数据分类的准确性。而且,结合使用分类效率更高的正则表示集合对数据进行分类,只有在第二数据识别的数据类别置信度不高时,也即,初始数据类别的第一置信度小于第一阈值时,才利用自然语言数据分类模型识别第二数据避免使用自然语言数据分类模型对所有数据结构的数据进行分类,加快了数据分类的效率,整体实现了对数据结构的数据进行高效且准确的分类的目的。
12、在一些可选的实施例中,获取待分类数据的数据结构,包括:
13、根据预设时间周期以及目标数据库的数据库类型,选择与目标数据库对应的数据查询策略;
14、根据数据查询策略,提取目标数据库的元数据信息、数据集合以及数据结构标识信息;
15、根据元数据信息,从数据集合中提取原始待分类数据;
16、根据与数据结构标识信息对应的预处理操作,处理原始待分类数据;
17、将处理后的原始待分类数据的数据格式转换为目标数据格式,得到待分类数据;
18、根据数据结构标识信息,确定待分类数据的数据结构。
19、具体的,周期性的利用与目标数据库对应的数据查询策略,提取目标数据库的元数据信息、数据集合以及数据结构标识信息,以获得原始待分类数据,并对原始待分类数据进行预处理得到待分类数据,确保数据库元数据信息的及时更新,实现待分类数据与数据库中实际数据保持一致,保证数据分类时的待分类数据是正确有效的数据,可以提高数据分类的准确性。将获取的数据存储至元数据存储数据库可以为数据资产管理和数据审核提供数据支撑。
20、在一些可选的实施例中,根据预设置信度规则,确定初始数据类别对应的第一置信度,包括:
21、分别获取第二数据所属数据表的总数据量、数据表中取样数据的第一数据量、去除空值后的数据表的第二数据量以及去除空值后的数据表中被正则表达式集合中正则表达式匹配的数据的第三数据量;
22、根据第三数据量与第二数据量之间的第一比值、第一数据量与总数据量之间的第二比值以及第二数据量与第一数据量之间的第三比值,确定初始数据类别对应的第一置信度。
23、具体的,第一比值可以衡量第二数据所属数据表中真实被分类的数据在该表中有效取样数据中的占比,第二比值可以衡量第二数据所属数据表中数据取样是否足够代表全表的数据分布,第三比值可以衡量第二数据所属数据表中数据取样是否有效,将三者结合确定出的置信度可以准确地反映出第二数据在数据表中的真实情况,提高置信度的可靠性,进而提高数据分类的准确性。
24、在一些可选的实施例中,数据分类方法还包括:
25、响应于用户查询目标元数据的请求,从元数据存储数据库中查询目标元数据,元数据存储数据库用于存储从已连接数据库中获取的数据以及元数据信息;
26、若元数据存储数据库存在目标元数据,且目标元数据在元数据存储数据库中的存储时间小于或等于第二阈值,则返回目标元数据;
27、若存储时间大于第二阈值,或者元数据存储数据库中不存在目标元数据,则获取目标元数据所属数据库的当前元数据信息;
28、根据当前元数据信息,更新元数据存储数据库,以在更新后的元数据存储数据库中查找并返回目标元数据。
29、具体的,在用户查询元数据信息时,会将存储时间下或等于第二阈值内的元数据信息返回给用户,否则就重新获取元数据信息,保证元数据信息的时效性与可靠性。
30、在一些可选的实施例中,根据预构建的正则表达式集合,识别第二数据的初始数据类别,包括:
31、根据正则表达式集合中的每一个条正则表达式对第二数据进行匹配;
32、若第一正则表达式与第二数据匹配成功,则将第一正则表达式对应的标签确定为第二数据的标签,得到第二数据的初始数据类别,标签用于指示数据所属数据类别,第一正则表达式为正则表达式集合中的任一个正则表达式。
33、具体的,通过正则表达式与数据进行匹配的方式,可以快速地确定第二数据的初始数据类别,从而提高数据分类的效率。
34、在一些可选的实施例中,在将第一正则表达式对应的标签确定为第二数据的标签,得到第二数据的初始数据类别之后,方法还包括:
35、若第二数据的标签指示的数据类别为预设数据类别,则根据预设数据类别对应的校验算法,校验第二数据;
36、若第二数据校验未通过,则返回利用正则表达式集合中的每一个条正则表达式对第二数据进行匹配的步骤,重新确定第二数据的标签。
37、具体的,若第二数据校验通过,则将第一正则表达式对应的标签确定为第二数据的标签,得到第二数据的初始数据类别。对于数据类别为预设数据类别的数据进行二次校验,在校验结果未通过时,则重新利用正则表达式进行数据分类,可以很大程度校正分类错误的数据,从而提高数据分类的准确性。
38、在一些可选的实施例中,将第一数据发送至预训练的自然语言数据分类模型,得到第一数据的数据类别,包括:
39、利用自然语言数据分类模型根据预设停用词库以及预设命名实体识别分词列表,对第一数据进行特征提取操作,得到特征数据;
40、利用自然语言数据分类模型根据预构建的数据类别列表,识别特征数据所属的数据类别,得到第一数据的标签,标签用于指示数据所属数据类别。
41、具体的,利用自然语言数据分类模型根据预设停用词库以及预设命名实体识别分词列表对复杂的非结构化的数据进行特征提取以识别数据的数据类别,实现对复杂的非结构化数据的准确分类。
42、在一些可选的实施例中,在将待分类数据中已分类的数据与其自身所属的数据类别进行关联存储之前,方法还包括:
43、根据第一数据的数据类别以及第一数据的元数据信息,从预构建的标签库中确定第一数据的子标签,子标签用于指示数据在其所属数据类别下的子数据类别;
44、根据第二数据的数据类别以及第二数据的元数据信息,从标签库中确定第二数据的子标签。
45、具体的,在数据分类后还依据数据的数据类别以及元数据信息从标签库中确定数据的子数据类别,向数据的数据类别与子数据类别一同存储,便于后续从子数据类别的维度对数据进行检索方便用户管理数据资产。
46、第二方面,本技术提供了一种数据资产管理平台,应用于如第一方面任一实施例的数据分类方法,平台包括数据库元数据信息获取模块、数据分发模块、第一数据分类引擎、第二数据分类引擎、数据分类结果验证模块以及数据分类结果存储模块;
47、数据库元数据信息获取模块用于获取待分类数据的数据结构;
48、数据分发模块用于将待分类数据中数据结构为非结构化的第一数据发送至第一数据分类引擎;将待分类数据中数据结构为结构化或半结构化的第二数据发送至第二数据分类引擎;
49、第一数据分类引擎用于将第一数据发送至预训练的自然语言数据分类模型,得到第一数据的数据类别;以及,接收数据分发模块发送的第二数据,利用自然语言数据分类模型根据预设置信度规则,确定第二数据的初始数据类别对应的第二置信度;将第二置信度发送至数据分类结果验证模块;
50、第二数据分类引擎用于根据预构建的正则表达式集合识别第二数据的初始数据类别;以及,根据预设置信度规则,确定初始数据类别对应的第一置信度;将第一置信度发送至数据分类结果验证模块;
51、数据分类结果验证模块用于接收第一数据分类引擎以及第二数据分类引擎分别发送的第一置信度以及第二置信度,确定第二数据的初始数据类别对应的总置信度;若总置信度大于第一阈值,则将初始数据类别确定为第二数据的数据类别;以及,若第一置信度小于第一阈值,则通过数据分发模块将第二数据发送至第一数据分类引擎;
52、数据分类结果存储模块用于将待分类数据中已分类的数据与其自身所属的数据类别进行关联存储。
53、在一些可选的实施例中,该平台还包括数据预处理模块;
54、数据库元数据获取模块具体用于根据预设时间周期以及目标数据库的数据库类型,选择与目标数据库对应的数据查询策略;根据数据查询策略,提取目标数据库的原始元数据信息以及数据结构标识信息;从原始元数据信息中提取原始待分类数据;将原始待分类数据以及数据结构标识信息发送至数据预处理模块;
55、数据预处理模块用于根据与数据结构标识信息对应的预处理操作,处理原始待分类数据;将处理后的原始待分类数据的数据格式转换为目标数据格式,得到待分类数据;将待分类数据以及数据结构标识信息发送至数据分发模块;
56、数据分发模块,用于根据数据结构标识信息,确定待分类数据的数据结构。
57、在一些可选的实施例中,该平台还包括标签库模块;
58、第一数据分类引擎还用于根据第一数据的数据类别以及第一数据的元数据信息,从标签库模块中预构建的标签库中确定第一数据的子标签,子标签用于指示数据在其所属数据类别下的子数据类别;
59、第二数据分类引擎还用于根据第二数据的数据类别以及第二数据的元数据信息,从标签库模块中预构建的标签库中确定第二数据的子标签。
60、第三方面,本技术提供了一种数据分类装置,应用于数据资产管理平台,装置包括:
61、获取模块,用于获取待分类数据的数据结构;
62、发送模块,用于若待分类数据中存在数据结构为非结构化的第一数据,将第一数据发送至预训练的自然语言数据分类模型,得到第一数据的数据类别;
63、识别模块,用于若待分类数据中存在数据结构为结构化或半结构化的第二数据,则根据预构建的正则表达式集合,识别第二数据的初始数据类别;
64、第一确定模块,用于根据预设置信度规则,确定初始数据类别对应的第一置信度;
65、第二确定模块,用于若第一置信度小于第一阈值,则利用自然语言数据分类模型对第二数据分类并确定初始数据类别对应的第二置信度;
66、第三确定模块,用于根据第一置信度以及第二置信度,确定第二数据的初始数据类别对应的总置信度;
67、第四确定模块,用于若总置信度大于第一阈值,则将初始数据类别确定为第二数据的数据类别;
68、存储模块,用于将待分类数据中已分类的数据与其自身所属的数据类别进行关联存储。
69、第四方面,本技术提供了一种计算机设备,包括:存储器和处理器,存储器和处理器之间互相通信连接,存储器中存储有计算机指令,处理器通过执行计算机指令,从而执行上述第一方面任一实施例的数据分类方法。
70、第五方面,本技术提供了一种计算机可读存储介质,该计算机可读存储介质上存储有计算机指令,计算机指令用于使计算机执行上述第一方面任一实施例的数据分类方法。
- 还没有人留言评论。精彩留言会获得点赞!