一种语义感知的跨模态行人重识别方法
本技术涉及跨模态行人重识别,特别是涉及一种语义感知的跨模态行人重识别方法。
背景技术:
1、目前,现有方法试图解决跨模态行人重识别(vi-reid,visible-infrared personre-identification)任务中的难题;一种是生成额外的模态图像以弥合模态差距,这些方法采用额外的生成对抗网络或专门设计的卷积模块来生成更多的跨模态图像对,以促进网络缩小跨模态特征的差距,但这些方法主要侧重于图像级的生成,这不可避免地带来了额外的背景噪声;另一种方法是通过设计双流网络结构来提取模态不变特征,这些方法设计了几个独立的层来学习模态特定的特征,其余层被视为共享网络以提取模态共享特征,尽管这种方法可以提取某些与身份相关的特征,但它们仅学习全局特征或严格切片的部分特征,无法处理由类内变化(即姿态变化、视点变化、遮挡)引起的错位问题。
技术实现思路
1、基于此,有必要提供一种能够减小现有跨模态行人重识别任务中存在的模态差异和视角模态变化引起类内差异问题的挖掘跨模态图像间语义一致信息的跨模态行人重识别方法,具体为一种语义感知的跨模态行人重识别方法。
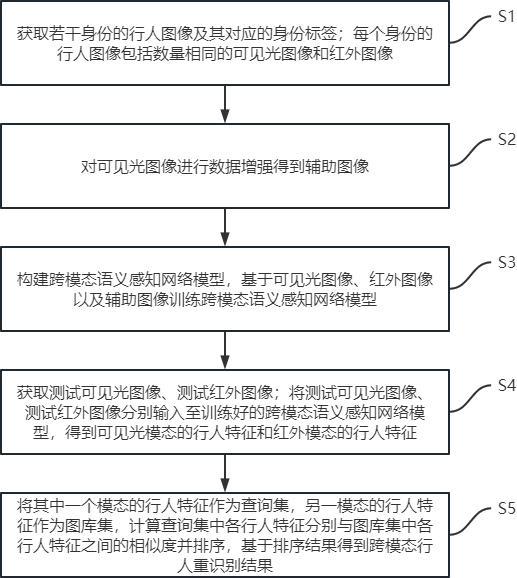
2、本发明提供了一种语义感知的跨模态行人重识别方法,该方法包括:
3、s1:获取若干身份的行人图像及其对应的身份标签;每个身份的行人图像包括数量相同的可见光图像和红外图像;
4、s2:对所述可见光图像进行数据增强得到辅助图像;
5、s3:构建跨模态语义感知网络模型,基于所述可见光图像、所述红外图像以及所述辅助图像训练所述跨模态语义感知网络模型;
6、s4:获取测试可见光图像、测试红外图像;将所述测试可见光图像、所述测试红外图像分别输入至训练好的所述跨模态语义感知网络模型,得到可见光模态的行人特征和红外模态的行人特征;
7、s5:将其中一个模态的行人特征作为查询集,另一模态的行人特征作为图库集,计算查询集中各行人特征分别与图库集中各行人特征之间的相似度并排序,基于排序结果得到跨模态行人重识别结果。
8、优选的,s1中,从跨模态行人重识别数据集sysu-mm01中获取若干身份的行人图像及其对应的身份标签。
9、优选的,s2中,所述对所述可见光图像进行数据增强得到辅助图像包括:随机选取所述可见光图像中的一种通道数据作为辅助图像。
10、优选的,s3中,所述跨模态语义感知网络模型包括人体语义特征提取模块、人体语义感知注意力模块;
11、采用resnet-50网络作为跨模态语义感知网络模型的骨干网络;
12、所述人体语义特征提取模型包括模态特定信息提取模块和模态共有信息提取模块;
13、resnet-50网络包括5个阶段,将第一阶段以及第二阶段的网络参数权重不共享作为所述模态特定信息提取模块;将第三阶段、第四阶段以及第五阶段作为权重共享部分提取作为所述模态共有信息提取模块;
14、在第三阶段与第四阶段之间嵌入有一所述人体语义感知注意力模块,在第四阶段与第五阶段之间嵌入有另一所述人体语义感知注意力模块。
15、优选的,s3中,在所述人体语义感知注意力模块中,对于输入的图像,给与一个第三阶段或第四阶段输出的行人图像特征;将行人图像特征送入全局平均池化层,并通过两个1×1的卷积层获得加权特征图,计算公式为:
16、;
17、其中,f g表示加权特征图, σ{}表示sigmoid激活函数, δ{}表示relu激活函数, g()表示全局平均池化层,f表示行人图像特征,w1为第一个卷积层的参数,w2为第二个卷积层的参数;
18、基于所述行人图像特征和所述加权特征图得到身份相关特征,计算公式为:
19、;
20、其中,fw表示身份相关特征;表示通道维度的乘法;
21、基于所述身份相关特征计算人体全局特征,计算公式为:
22、;
23、其中,fp表示人体全局特征;w3为第三个1×1卷积层的参数;fs表示人类语义增强特征图。
24、优选的,s3中,所述人体语义特征提取模块接收所述人体全局特征,并将其通过一个线性层,表达式为:
25、;
26、其中,表示预测语义解析置信图,,h为特征高度,w为特征宽度,k为部分类别数; w l表示线性层的参数;fp表示人体全局特征;
27、根据预测语义解析置信图,利用每个像素的语义类别标签生成语义对齐的特征图,得到人体语义特征;人体语义特征中第 i个语义局部特征图的计算公式为:
28、;
29、其中, p i表示人体语义特征中第 i个语义局部特征图; g’表示广义平均池化函数; σ表示sigmoid激活函数;表示第 i个语义局部特征图对应的预测语义解析置信图;表示哈达玛积;
30、将所述人体全局特征与所述人体语义特征进行通道级联,得到行人特征,计算公式为:
31、;
32、其中,fo表示行人特征;表示在通道维度连接两个特征。
33、优选的,所述预测语义解析置信图通过语义解析损失函数和分离损失函数进行约束,计算公式分别为:
34、;
35、;
36、其中,表示语义解析损失函数; n表示像素总和;k表示k个部分类别;j表示第j个部分类别;n表示每个语义局部特征图的像素总和;表示第 i个语义局部特征图对应的预测语义解析置信图;表示第 j个部分类别对应的预测语义解析置信图;表示第j部分类别的第t个像素的真实标签;表示第j部分类别的第t像素的语义解析预测分数;表示分离损失函数;表示余弦相似度。
37、优选的,s3中,以4张可见光图像、4张所述红外图像以及4张所述辅助图像作为一个训练批次;基于所述行人特征,并通过三模态身份损失训练所述跨模态语义感知网络模型;所述三模态身份损失表达式为:
38、;
39、其中,表示三模态身份损失,f表示一个批次内训练图像数量,b表示第b个训练图像,表示输入可见光图像被分为类的概率,表示输入红外图像被分为类的概率,表示输入辅助图像被分为类的概率。
40、优选的,s5中,所述相似度的计算公式为:
41、;
42、其中, d pq表示图像对(p,q)之间的相似度;表示查询集第p个行人图像的行人特征,表示图库集中第q个行人图像的行人特征;
43、根据图像对之间的相似度检索出前k个相似度最高的图库图像组成top-k跨模态行人重识别结果。
44、有益效果:本发明提供的这种方法能够挖掘跨模态图像间语义一致信息、跨不同模态的人类语义一致性特征,可以强调与身份相关的语义特征并增强模态不变的细粒度表示。人体语义感知注意力模块通过插入到不同的网络层来突出从浅到深的人体语义特征,消除干扰信息并增强跨不同模态的类内语义可辨性。人体语义特征提取模块通过人体语义分割先验信息的约束来生成人体语义特征,可以实现精确的跨模态特征对齐。
- 还没有人留言评论。精彩留言会获得点赞!