一种基于通用大语言模型的垂直领域应用的实现方法与流程
本发明涉及自然语言处理,具体为一种基于通用大语言模型的垂直领域应用的实现方法。
背景技术:
1、自然语言处理(natural language processing,nlp)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。
2、现有技术中,语言模型的概念:语言模型(language model)是自然语言处理的重要技术。自然语言处理中最常见的数据就是文本数据。简单来说,语言模型的概念为:语言模型计算一个句子是句子的概率的模型。通过语言模型,可以量化地评估一串文字存在的可能性。对于一段长度为n的文本,文本中的每个单词都有通过上文预测该单词的过程,所有单词的概率乘积便可以用来评估文本存在的可能性。基于语言模型,配合相应的深度学习算法,可以实现各种语言处理功能,如语义匹配,智能问答,文本分类等等;垂直领域,互联网行业术语,指的是为限定群体提供特定服务,宽泛定义指娱乐、医疗、环保、教育、体育等产业。具体就是指各行各业自身所处的业务细分领域。elasticsearch是一个分布式、高扩展、高实时的开源搜索与数据分析引擎。它能很方便的使大量数据具有搜索、分析和探索的能力。充分利用elasticsearch的水平伸缩性,能使数据在生产环境变得更有价值。
3、但是,目前通用大语言模型作为新兴技术,在垂直领域的企业应用方式并不是非常成熟,主流的落地方式一般以调用大模型服务商的云资源为主,这种方式需要企业向服务商提供自己的业务数据来进行模型训练,对于企业自身信息安全性有着很高的风险,对于通用大语言模型服务商而言,也存在模型被企业数据污染的可能性。另外也有通用大语言模型私有化部署的使用方式,但这种模式对物理硬件资源要求极高,中小型企业几乎没有实现的可能。最后,由于通用大语言模型的黑盒属性,导致其回答一定程度的不可控,对于企业内部业务,人们更希望计算机反馈的是精准正确的回答,而不是一个ai消耗大量算力生成的充满随机性的错误答案。
4、因此,提出一种企业信息保密程度高,企业落地成本低,企业业务问答精准可控的通用大语言模型的垂直领域应用方法变得尤为重要。
技术实现思路
1、本发明的目的在于提供一种基于通用大语言模型的垂直领域应用的实现方法,以解决上述背景技术中提出的问题。
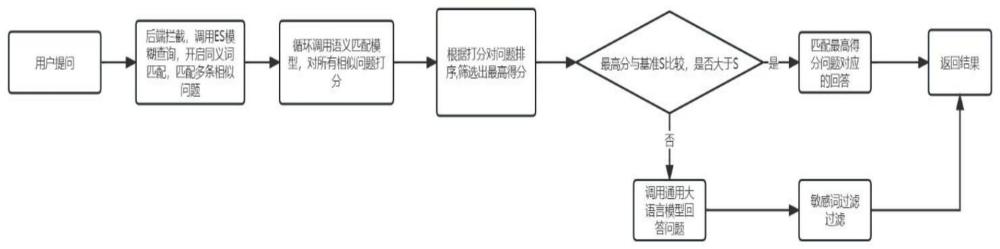
2、为实现上述目的,本发明提供如下技术方案:一种基于通用大语言模型的垂直领域应用的实现方法,所述方法包括以下步骤:
3、建立业务问题数据库与数据表;
4、在问答数据库中创建完成后,需要设置一个后端服务,通过暴露api给用户的方式,实现问题问答服务,问题拦截,数据同步服务的功能;
5、创建敏感词数据表,记录与企业内部业务强相关的敏感词;
6、调用通用大语言模型的云资源对用户提问进行处理,并将返回结果提交给后端服务;
7、后端使用es对结果进行分词,然后在es敏感词数据库中查询并使用replacement进行替换。
8、优选的,建立业务问题数据库与数据表的具体操作包括:
9、建立一个存储业务问题的问答数据库以及数据表,使用常见的关系型持久化数据库,数据表基础字段只要求具备问题与回答以及唯一主键。
10、优选的,建立数据表时建议遵循以下规则,以提高半智能问答回答的准确性:
11、(1)对于同一个业务问题,创建多条问答数据,question字段存储同一问题的不同问法;
12、(2)不同的业务问题,尽量避免问题提出的语句过于相似,如果两个问题具有很高相似性,将提问方式写的详细些,增加语句的长度,方便后续语言模型匹配识别;
13、(3)尽量避免同一个业务问题有不同的回答或者解释方式,增加回答的精确性。
14、优选的,后端服务的实现语言不限,使用常用的后端语言如java,go,c++均可,用户将后端暴露的问答api作为唯一接口,将通用大语言模型的云资源与用户分割开。
15、优选的,后端服务需要以下几个基础组成部分:
16、数据同步服务:需要提供一个数据同步服务,定时或者通过接口控制,将数据库中问答数据更新到elasticsearch上,后续调用问答api时将直接使用es进行模糊搜索,而不是直接查询数据库;
17、语义匹配服务:后端需要引入一个用于语义匹配的预训练模型,目前开源的能够支持语义匹配功能的自然语言处理模型很多,如ernie,gpt2;
18、es搜素:当用户提出问题时,需要以问题为关键字在es中进行模糊搜索,为了提高精确性,需要开启同义词匹配,语言分词的功能;
19、问答api:作为用户提问的唯一入口。
20、优选的,敏感词数据表必要字段至少包括以下字段:
21、敏感词:与业务强相关的内容,单词,可能涉及企业机密信息的单词;除此之外也加入一些违法违规的单词,带有辱骂性质的单词等,不过如果是与企业业务关系不密切的敏感词,通过后续调用第三方api的方式进行过滤,以减少私有化部署的负担;
22、敏感词的替换词:但检测到敏感词时,将使用replacement去代替敏感词,如果合适的replacement,可以用“*”去代替;
23、创建完成后将数据同步到es中敏感词数据库中,方便查询。
24、优选的,调用通用大语言模型之前,先在es中对问题进行分词,分词后在es敏感词数据库中查询并使用replacement进行替换。
25、优选的,使用第三方敏感词过滤api再次对结果进行清洗,防止结果出现违规的情况,最后将过滤后的结果返回给用户。
26、与现有技术相比,本发明的有益效果是:
27、本发明提出的基于通用大语言模型的垂直领域应用的实现方法,拦截企业业务数据进行私有化处理,将业务问题的回答存储在持久化数据库保证回答的精确性,只将业务弱相关的问题交给大模型服务商的api处理,在将最终结果返回给用户前进行企业信息以及敏感词过滤。使用这种方法来达到通用大语言模型在垂直领域落地时降低企业通用大语言模型应用的落地成本,预防企业数据泄露,提高业务问答的精确性与可控性的目的。
技术特征:
1.一种基于通用大语言模型的垂直领域应用的实现方法,其特征在于:所述方法包括以下步骤:
2.根据权利要求1所述的一种基于通用大语言模型的垂直领域应用的实现方法,其特征在于:建立业务问题数据库与数据表的具体操作包括:
3.根据权利要求1所述的一种基于通用大语言模型的垂直领域应用的实现方法,其特征在于:建立数据表时建议遵循以下规则,以提高半智能问答回答的准确性:
4.根据权利要求1所述的一种基于通用大语言模型的垂直领域应用的实现方法,其特征在于:后端服务的实现语言不限,使用常用的后端语言如java,go,c++均可,用户将后端暴露的问答api作为唯一接口,将通用大语言模型的云资源与用户分割开。
5.根据权利要求4所述的一种基于通用大语言模型的垂直领域应用的实现方法,其特征在于:后端服务需要以下几个基础组成部分:
6.根据权利要求1所述的一种基于通用大语言模型的垂直领域应用的实现方法,其特征在于:敏感词数据表必要字段至少包括以下字段:
7.根据权利要求1所述的一种基于通用大语言模型的垂直领域应用的实现方法,其特征在于:调用通用大语言模型之前,先在es中对问题进行分词,分词后在es敏感词数据库中查询并使用replacement进行替换。
8.根据权利要求1所述的一种基于通用大语言模型的垂直领域应用的实现方法,其特征在于:使用第三方敏感词过滤api再次对结果进行清洗,防止结果出现违规的情况,最后将过滤后的结果返回给用户。
技术总结
本发明涉及自然语言处理技术领域,具体为一种基于通用大语言模型的垂直领域应用的实现方法,包括以下步骤:建立业务问题数据库与数据表;在问答数据库中创建完成后,需要设置一个后端服务,通过暴露API给用户的方式,实现问题问答服务,问题拦截,数据同步服务的功能;创建敏感词数据表,记录与企业内部业务强相关的敏感词;调用通用大语言模型的云资源对用户提问进行处理;有益效果为:本发明提出的基于通用大语言模型的垂直领域应用的实现方法,拦截企业业务数据进行私有化处理,将业务问题的回答存储在持久化数据库保证回答的精确性,只将业务弱相关的问题交给大模型服务商的API处理,在将最终结果返回给用户前进行企业信息以及敏感词过滤。
技术研发人员:李志华,张积磊,范成城,李翔
受保护的技术使用者:浪潮云信息技术股份公司
技术研发日:
技术公布日:2024/3/4
- 还没有人留言评论。精彩留言会获得点赞!