数据血缘管理系统以及数据血缘管理方法与流程
本发明涉及一种数据库分析方法,尤其是一种数据血缘管理系统以及数据血缘管理方法。
背景技术:
1、一般而言,数据血缘(data lineage)可应用在元数据(metadata)的管理。数据血缘用以描述数据在撷取(extract)、转换(transform)以及加载(load)等处理过程中的关系。
2、然而,在多个关联的数据库的应用中,当最终的数据库出现数据异常时,目前的管理系统需要从源头的数据库至终点的数据库依序检查所有的脚本,以确定多个字段之间的数据血源。此外,由于此些数据库的处理涉及复杂的语法,因此目前的管理系统尚需仰赖人工分析。在前述的情况下,目前的管理系统无法有效率地且准确地确定数据血源,甚至无法基于线下或在线的版本来进行分析,进而导致分析数据血源的作业效率以及准确性下降。
技术实现思路
1、本发明是针对一种数据血缘管理系统,能够自动地确定数据血源,据以提高分析数据血源的作业效率以及准确性。
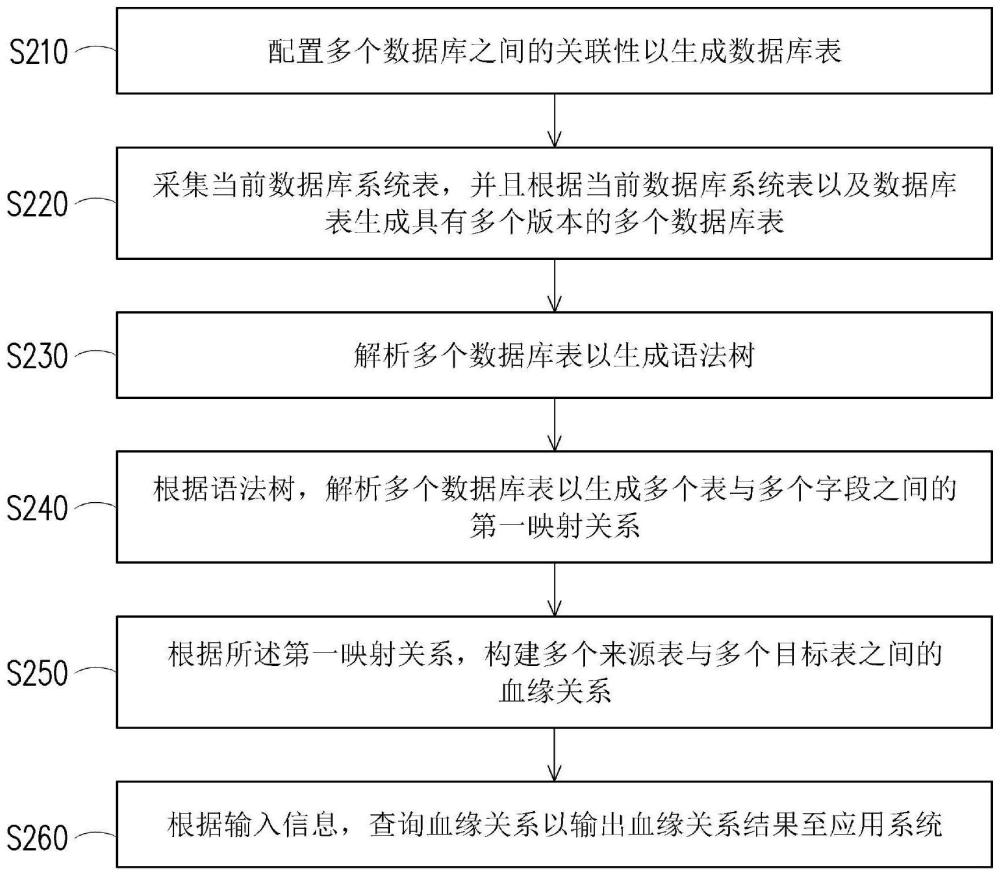
2、根据本发明的实施例,本发明的数据血缘管理系统包括记忆体以及处理器。记忆体存储多个模块。处理器耦接记忆体、以及应用系统。处理器执行多个模块。多个模块包括元数据采集模块、语法解析模块、以及血缘关系解析模块。元数据采集模块配置多个数据库之间的关联性以生成数据库表,采集多个数据库中的当前数据库系统表,并且根据当前数据库系统表以及数据库表生成具有多个版本的多个数据库表。语法解析模块解析多个数据库表以生成用以处理多个数据库的语法树,并且根据语法树,解析多个数据库表以生成多个数据库表中的多个表与多个表中的多个字段之间的第一映射关系。血缘关系解析模块根据第一映射关系,构建多个表中的多个来源表与多个目标表之间的血缘关系,并且根据来自应用系统的输入信息,查询血缘关系以输出关联于输入信息的血缘关系结果至应用系统。
3、根据本发明的实施例,本发明的数据血缘管理方法包括以下的步骤。通过处理器配置多个数据库之间的关联性以生成数据库表。通过处理器采集多个数据库中的当前数据库系统表,并且根据当前数据库系统表以及数据库表生成具有多个版本的多个数据库表。通过处理器解析多个数据库表以生成用以处理多个数据库的语法树。通过处理器根据语法树,解析多个数据库表以生成多个数据库表中的多个表与多个表中的多个字段之间的第一映射关系。通过处理器根据第一映射关系,构建多个表中的多个来源表与多个目标表之间的血缘关系。通过处理器根据来自应用系统的输入信息,查询血缘关系以输出关联于输入信息的血缘关系结果至应用系统。
4、基于上述,本发明的数据血缘管理系统以及数据血缘管理方法通过配置并且采集多个数据库,能够管理不同版本的多个数据库表。此外,通过解析此些数据库表以构建多个来源表与多个目标表之间的血缘关系,数据血缘管理系统能够自动地分析多个表的数据血源,据以提高分析数据血源的作业效率以及准确性。
5、为让本发明的上述特征和优点能更明显易懂,下文特举实施例,并配合附图作详细说明如下。
技术特征:
1.一种数据血缘管理系统,其特征在于,包括:
2.根据权利要求1所述的数据血缘管理系统,其特征在于,所述元数据采集模块包括数据库管理器以及字段采集器,
3.根据权利要求1所述的数据血缘管理系统,其特征在于,所述语法解析模块包括配置解析器、语法解析器、以及字段解析器,
4.根据权利要求1所述的数据血缘管理系统,其特征在于,所述血缘关系解析模块包括血缘关系解析器,
5.根据权利要求1所述的数据血缘管理系统,其特征在于,所述多个模块还包括数据查询模块,
6.一种数据血缘管理方法,其特征在于,包括:
7.根据权利要求6所述的数据血缘管理方法,其特征在于,采集所述多个数据库中的所述当前数据库系统表,并且根据所述当前数据库系统表以及所述数据库表生成具有所述多个版本的所述多个数据库表的步骤包括:
8.根据权利要求6所述的数据血缘管理方法,其特征在于,解析所述多个数据库表以生成用以处理多个数据库的所述语法树的步骤包括:
9.根据权利要求6所述的数据血缘管理方法,其特征在于,根据所述第一映射关系,构建所述多个表中的所述多个来源表与所述多个目标表之间的所述血缘关系的步骤包括:
10.根据权利要求6述的数据血缘管理方法,其特征在于,还包括:
技术总结
本发明提供一种数据血缘管理系统以及数据血缘管理方法。数据血缘管理系统包括记忆体以及处理器。处理器执行记忆体中的多个模块。元数据采集模块配置多个数据库之间的关联性以生成数据库表,采集当前数据库系统表,并且根据当前数据库系统表以及数据库表生成具有多个版本的多个数据库表。语法解析模块解析多个数据库表以生成多个表与多个字段之间的映射关系。血缘关系解析模块根据映射关系,构建多个来源表与多个目标表之间的血缘关系,并且根据输入信息,查询血缘关系以输出血缘关系结果,据以自动地确定数据血源。
技术研发人员:李兵,潘军,夏锐
受保护的技术使用者:鼎捷软件股份有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!