一种基于遗忘学习的行人重识别数据隐私保护方法和系统与流程
本发明涉及信息安全领域,尤其涉及一种基于遗忘学习的行人重识别数据隐私保护方法和系统。
背景技术:
1、机器学习是一种人工智能领域的技术,通过让计算机从大量数据中学习模式和规律,以实现特定任务。它基于统计学和数据分析方法,通过训练模型来预测、分类、识别和决策。行人重识别旨在通过分析摄像头捕捉到的行人图像或视频,识别出不同场景下的相同行人,以实现行人在不同时间和地点的跟踪和监测。
2、随着机器学习和计算机视觉技术的发展,基于机器学习技术的行人重识别技术已逐步成为现代监控系统、智能交通、及安全管理领域的核心应用。然而,机器学习本身存在各种安全问题,在使用过程中存在巨大的安全风险。
3、行人重识别所使用的图像和视频数据往往包含大量的个人隐私信息,例如行人的外貌特征和身份信息。最近的研究表明,行人重识别模型在应对多样的安全与隐私攻击时表现得尤为脆弱,由于深度学习模型在训练的过程中,会将学到的特征信息以权重的形式保存下来,仅利用模型参数或者梯度信息,攻击者仍可以窃取用户数据信息。因此,如何保护行人重识别系统中训练数据包含的数据隐私信息是机器学习安全领域必须解决的科学问题。
4、为了保护深度学习模型中的数据隐私,目前已经研究了一些数据遗忘算法,但是,这些遗忘算法在很大程度上是特定于遗忘数据的样本数量充足的情况,而行人重识别数据集中不同行人身份包含的数据样本数量并不均衡,存在样本数量不足的情况。例如,将遗忘数据的标签全部更改为其他标签并对深度学习模型进行微调,这种遗忘方法在遗忘数据较少的情况下不适用。迄今为止,针对遗忘数据样本数量不足的遗忘算法很少,没有能够有效地保护大多数行人重识别数据隐私信息的方法。
技术实现思路
1、本发明针对现有技术中存在的技术问题,提供一种基于遗忘学习的行人重识别数据隐私保护方法和系统,解决现有数据隐私保护方法中只针对遗忘数据样本数量充足的限制问题。
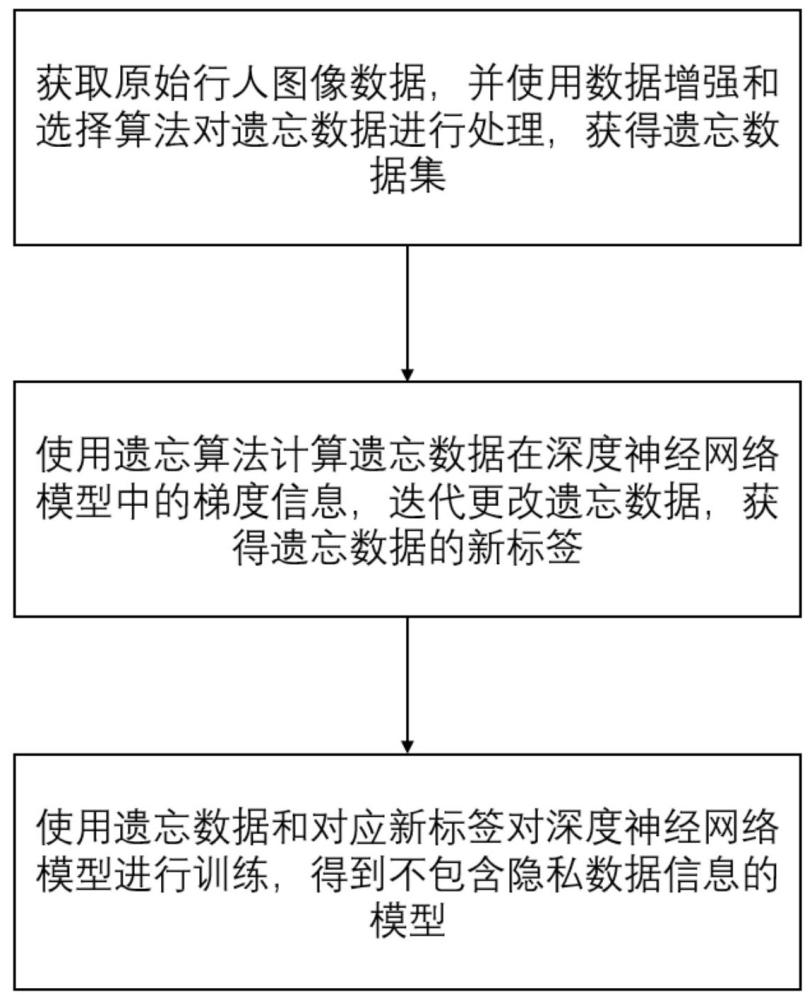
2、根据本发明的第一方面,提供了一种基于遗忘学习的行人重识别数据隐私保护方法,包括:
3、获取原始行人图像数据,对所述行人图像数据中的隐私数据进行数据增强和选取后得到遗忘数据,构建遗忘数据集;
4、步骤2,使用遗忘算法计算所述遗忘数据在用于行人重识别的深度网络模型中的梯度信息,使用所述梯度信息对所述遗忘数据进行扰动后再次输入所述深度网络模型,重复扰动迭代过程,获得所述遗忘数据的新标签;
5、步骤3,使用所述遗忘数据和对应的所述新标签对所述深度网络模型进行训练,得到遗忘隐私数据模型。
6、在上述技术方案的基础上,本发明还可以作出如下改进。
7、可选的,所述步骤1中对所述隐私数据进行数据增强的过程包括:
8、随机选择数据增强方法中的一个或多个对所述隐私数据进行数据增强,获得更多数量的遗忘数据样本;
9、其中,所述数据增强方法包括:图片水平镜像、图片颜色增强、图片亮度增强、图片锐化以及像素均衡。
10、可选的,所述步骤1中对数据增强后的所述隐私数据进行选择的过程包括:
11、将数据增强后的所述隐私数据输入所述深度神经网络模型,得到遗忘特征数据,将所述遗忘特征数据与特征中心进行相似性度量,选择相似度最高的设定数量的所述遗忘数据生成所述遗忘数据集;
12、其中,所述特征中心为将原始遗忘数据输入所述深度神经网络模型得到的所有特征数据的平均值;所述相似性度量方法使用欧氏距离或余弦距离进行计算。
13、可选的,所述步骤2包括:
14、步骤201,将m个遗忘数据的像素信息与对应的标签信息y作为所述深度网络模型m 的初始输入,得到模型的输出概率;
15、步骤202,根据所述输出概率与所述标签信息y通过损失函数计算损失,获得所述像素信息的梯度信息;
16、步骤203,根据所述梯度信息对像素信息进行设定定步长s的扰动,得到新的像素信息;
17、步骤204,将新的像素信息输入所述深度网络模型m,重复扰动迭代过程直至满足设定的迭代条件,获得遗忘数据的新标签。
18、可选的,所述迭代条件为:迭代达到指定次数k或者所述深度网络模型m的输出概率最大值与遗忘数据对应的标签信息不同;其中,表示模型对第i个遗忘数据的输出概率,表示第i个遗忘数据的真实标签。
19、可选的,所述步骤3包括:
20、步骤301,将所述遗忘数据输出概率与所述新标签信息输入损失函数进行计算,得到损失值;
21、步骤302,通过反向传播计算所述损失值相对于模型参数的梯度,用随机梯度下降法来更新所述模型参数,基于更新后的所述模型参数得到所述遗忘隐私数据模型。
22、可选的,所述方法还包括:
23、步骤4,基于精确率和累计匹配特性cmc值是否小于预定阈值,来判定所述遗忘隐私数据模型对遗忘数据的预测能力。
24、根据本发明的第二方面,提供一种基于遗忘学习的行人重识别数据隐私保护系统,包括:遗忘数据集构建模块、新标签生成模块和遗忘隐私数据模型生成模块;
25、所述遗忘数据集构建模块,用于获取原始行人图像数据,对所述行人图像数据中的隐私数据进行数据增强和选取后得到遗忘数据,构建遗忘数据集;
26、所述新标签生成模块,用于使用遗忘算法计算所述遗忘数据在用于行人重识别的深度网络模型中的梯度信息,使用所述梯度信息对所述遗忘数据进行扰动后再次输入所述深度网络模型,重复扰动迭代过程,获得所述遗忘数据的新标签;
27、所述遗忘隐私数据模型生成模块,用于使用所述遗忘数据和对应的所述新标签对所述深度网络模型进行训练,得到遗忘隐私数据模型。
28、根据本发明的第三方面,提供了一种电子设备,包括存储器、处理器,所述处理器用于执行存储器中存储的计算机管理类程序时实现基于遗忘学习的行人重识别数据隐私保护方法的步骤。
29、根据本发明的第四方面,提供了一种计算机可读存储介质,其上存储有计算机管理类程序,所述计算机管理类程序被处理器执行时实现基于遗忘学习的行人重识别数据隐私保护方法的步骤。
30、本发明提供的一种基于遗忘学习的行人重识别数据隐私保护方法、系统、电子设备及存储介质,在遗忘算法中添加相应的数据增强方法和遗忘数据选择机制,并在遗忘算法完成后添加判定方法。将原始遗忘数据通过数据增强方法得到样本数量扩充后的遗忘数据,扩充样本数量使遗忘算法更加精确,在额外的遗忘数据补充下,使遗忘算法关注更多数据样本的信息。遗忘数据选择机制根据扩充后的遗忘数据与原始数据的相似度度量结果选择遗忘算法使用的遗忘数据,可以根据不同类型的遗忘数据选择相应的相似度度量方法,更加有效地选择遗忘数据,使遗忘算法更有针对性的遗忘隐私信息,提高了隐私保护效率。
31、使用遗忘算法对遗忘数据进行扰动得到新的数据标签,迭代过程多次对遗忘数据进行扰动,有效防止了单次扰动过大破坏原始遗忘数据,提高了遗忘算法的有效性。另外,在每次数据扰动迭代过程中不断更新遗忘数据的扰动方向,有效提高了遗忘数据的标签修改效率。
32、将遗忘数据和对应的新数据标签输入深度神经网络模型进行训练,得到遗忘学习后的模型,从而有效地实现对行人重识别数据隐私保护。
33、通过所述深度神经网络模型对遗忘数据的预测标签与其真实标签计算精确率与cmc,比较精确率和cmc与阈值,检测模型对遗忘数据的预测能力,从而有效达到行人重识别数据隐私保护的目的。
34、相比于现有的保护方法,基于数据增强方法的遗忘算法可以应用于不同数量的遗忘数据样本,即针对任意数量的遗忘数据都能够有效保护隐私信息,以此解决现有数据隐私保护方法只针对特定样本数量的局限性问题。
- 还没有人留言评论。精彩留言会获得点赞!