一种分布式原生图数据库唯一索引的存储方法和装置与流程
本发明涉及分布式图数据库,特别是涉及一种分布式原生图数据库唯一索引的存储方法和装置。
背景技术:
1、图数据库是非关系型数据库的一种类型,主要应用图形理论来存储实体之间的关系信息,适用于分析多层次的复杂关系,更能适应当今海量的数据处理形势。图数据库是一种专门用于存储和查询图数据的数据库系统,其设计目标是用于处理大规模的图结构数据,即,以节点(vertices)和边(edges)的组成的数据,提供高效的图遍历和复杂的图查询功能。与传统的关系型数据库不同,图数据库能够有效地存储和处理知识图谱数据,更适用于处理复杂的关系和连接性。它们具有高度灵活的数据模型,可以轻松地表示和处理多对多的关系,以及复杂的图结构。
2、原生图数据库是专门设计和优化用于存储和查询图形数据的数据库系统,提供了专门的查询语言和算法,用于高效地存储和处理图数据,以支持对图数据的灵活查询和分析。与传统的关系型数据库或键值存储等通用存储系统不同,原生图存储系统针对图结构的特点进行了优化,以提供更高的性能和可扩展性。原生图数据库将图模型作为数据存储和查询的核心,通过专门的图查询语言和算法来处理和分析图形数据的数据库系统。非原生图数据库是指那些在设计之初并非专门为图形数据而构建的数据库系统,但后来通过扩展或添加图数据存储和查询功能来支持图数据的存储和分析。非原生图数据库在处理图形数据方面可能不如原生图数据库高效和灵活。原生图数据库通常在内部采用了专门的数据结构和算法来优化图形数据的存储和查询。因此,在处理大规模和复杂的图形数据时,原生图数据库往往更具优势。
3、分布式图数据库将数据分布在多个节点或计算机上,以实现数据的并行处理和高可扩展性。在分布式图数据库中,图数据被分割成多个子图,并分布在不同的节点上。每个节点负责管理和处理一部分图形数据,节点之间通过网络进行通信和协作,使得图数据库能够处理大规模的图形数据集,并通过并行计算来提高查询和分析的性能。
4、现有技术中,分布式原生图数据库的主表数据按照分区键的值被分在了多个分布式数据节点上,每个数据节点上的数据都是独立的数据结构,数据节点之间的数据没有交集。在向某个主表中插入数据时,需要向所有该主表涉及分区上的数据节点发送插入请求,通过对所有该主表涉及分区上的数据节点都进行唯一性约束判断,避免操作数据泄露;在查询数据时,同样地也需要向所有该主表涉及分区上的数据节点发送查询请求;这样会极大地降低对数据库进行增删改查操作的效率,造成中央处理器(central processingunit,简写为cpu)和i/o资源(输入输出资源)的浪费,使得数据库系统的整体性能较低。且现有技术中,对于向数据库中追加写入的增量数据无法直接建立唯一索引,无法通过唯一索引提高增删改查效率,进一步降低了数据库系统的整体性能。
5、鉴于此,克服该现有技术所存在的缺陷是本技术领域亟待解决的问题。
技术实现思路
1、本发明要解决的技术问题是提供一种分布式原生图数据库唯一索引的存储方法和装置,其目的在于,实现通过唯一索引提高增删改查操作的效率,以提高数据库系统的整体性能,解决现有技术中对主表进行增删改查操作时,均需要向所有该主表涉及分区上的数据节点发送请求,使得数据库系统的整体性能较低、实用性差的问题。
2、本发明采用如下技术方案:
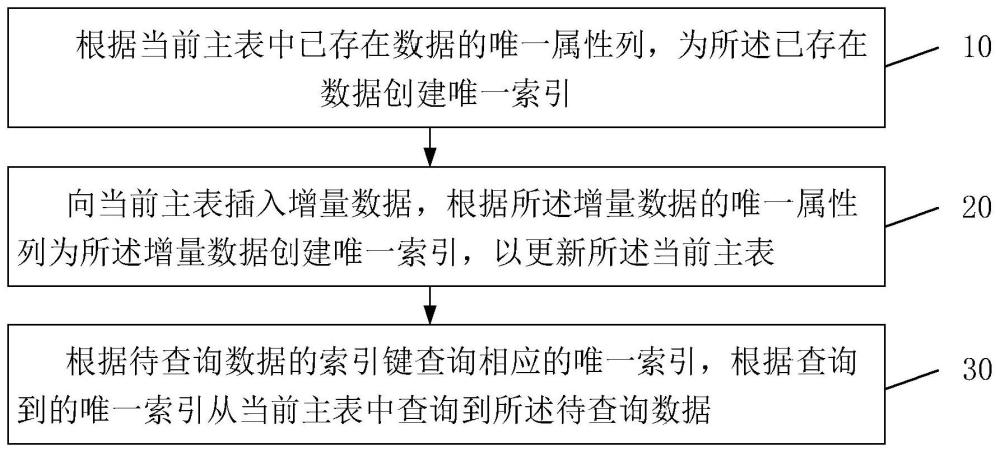
3、第一方面,本发明提供了一种分布式原生图数据库唯一索引的存储方法,包括:
4、根据当前主表中已存在数据的唯一属性列,为所述已存在数据创建唯一索引;
5、向当前主表插入增量数据,根据所述增量数据的唯一属性列为所述增量数据创建唯一索引,以更新所述当前主表;
6、根据待查询数据的索引键查询相应的唯一索引,根据查询到的唯一索引从当前主表中查询到所述待查询数据。
7、进一步地,所述根据当前主表中已存在数据的唯一属性列,为所述已存在数据创建唯一索引包括:
8、数据节点根据所述唯一属性列计算所述已存在数据所在的分区,根据所述唯一属性列从所述分区中抽取所述已存在数据的唯一标识;将所述唯一属性列与相应的唯一标识之间的映射关系作为唯一索引;
9、数据节点根据所述唯一索引的数据量及分配情况,按照所述唯一索引涉及的所有数据节点的数量,对所述唯一索引进行分片存储;存储完成后向管理节点发送状态信息;
10、当数据节点发现创建中的唯一索引违反唯一性约束时,向管理节点发送错误消息;所述管理节点接收所述错误消息,通知所有涉及所述唯一索引的数据节点删除所有创建中的唯一索引;
11、管理节点整合所有状态信息,根据所述所有状态信息更新存储唯一索引的元数据信息,以完成创建所述唯一索引。
12、进一步地,所述数据节点根据所述唯一索引的数据量及分配情况,按照所述唯一索引涉及的所有数据节点的数量,对所述唯一索引进行分片存储包括:
13、根据所述数据量及分配情况,按照所述唯一索引涉及的所有数据节点的数量,确定所述唯一索引所需存储至的多个数据节点的索引分区信息;
14、根据所述索引分区信息建立本地索引表和远端索引表,将所述唯一索引分别写入至所述本地索引表和所述远端索引表;
15、根据所述索引分区信息,向远端的数据节点发送同步请求,以便于所述远端的数据节点接收所述同步请求,同步所述远端索引表,以通过本地索引表和远端索引表实现对唯一索引的分片存储。
16、进一步地,每个数据节点同步维护本地索引表和远端索引表。
17、进一步地,在对已存在数据进行批量装载过程中,所述分布式原生图数据库唯一索引的存储方法还包括:
18、根据已存在数据的唯一标识确定已存在数据的数据节点,根据已存在数据的唯一属性列确定相应的唯一索引所需存储的数据节点;
19、将需要发送至同一数据节点的已存在数据和/或唯一索引进行分组封装,得到需要发送至各个数据节点的分组数据;
20、将分组数据发送至相应的数据节点。
21、进一步地,所述向当前主表插入增量数据,根据所述增量数据的唯一属性列为所述增量数据创建唯一索引,以更新所述当前主表包括:
22、将所述增量数据插入至所述当前主表,获取所述增量数据的唯一标识;
23、根据所述增量数据的唯一属性列,计算得到所述增量数据的待插入索引分区;
24、根据所述唯一标识,判断在所述待插入索引分区中创建的所述唯一索引是否违反唯一性约束;
25、若违反唯一性约束,则不创建所述唯一索引;
26、若不违反唯一性约束,则将所述唯一属性列作为索引键,将所述索引键和对应的唯一标识之间的映射关系作为唯一索引,将所述唯一索引插入至所述待插入索引分区。
27、进一步地,所述将所述增量数据插入至所述当前主表,获取所述增量数据的唯一标识包括:
28、对增量数据所处图的集合id与预设与运算参数进行按位与运算,得到所述集合id的预设序列值;
29、对所述增量数据所处的节点分区id与预设或运算参数进行按位或运算,得到分区初始结果;清除所述分区初始结果中除预设分区位以外的数据,得到分区中间结果;将所述分区中间结果中所述预设分区位的数据移到高位,得到预设分区值;
30、根据所述增量数据的数据类型进行按位或运算,得到类型初始结果;清除所述类型初始结果中除预设类型位以外的数据,得到类型中间结果;将所述类型中间结果中所述预设类型位的数据移到高位,得到预设类型值;
31、根据所述预设序列值、所述预设分区值和所述预设类型值,得到所述唯一标识。
32、进一步地,所述根据所述预设序列值、所述预设分区值和所述预设类型值,得到所述唯一标识包括:
33、当所述预设序列值、所述预设分区值和所述预设类型值的位数之和大于所述唯一标识的位数时,所述预设序列值的位数不变,根据预设调整策略减少所述预设分区值的位数和/或所述预设类型值的位数,以使所述预设序列值、所述预设分区值和所述预设类型值的位数之和等于所述唯一标识的位数,以得到所述唯一标识。
34、进一步地,所述根据待查询数据的索引键查询相应的唯一索引,根据查询到的唯一索引从当前主表中查询到所述待查询数据包括:
35、根据待查询数据的索引键,得到所述待查询数据的本地索引表和/或远端索引表;根据待查询数据的索引键得到唯一索引;
36、根据所述唯一索引,在所述本地索引表和/或远端索引表查找到所述待查询数据的唯一标识;
37、根据所述唯一标识,得到所述待查询数据所在的数据节点,在所述数据节点查询出所述待查询数据。
38、第二方面,本发明还提供了一种分布式原生图数据库唯一索引的存储装置,用于实现第一方面所述的分布式原生图数据库唯一索引的存储方法,所述分布式原生图数据库唯一索引的存储装置包括:
39、至少一个处理器;以及,与所述至少一个处理器通信连接的存储器;其中,所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述处理器执行,用于执行第一方面所述的分布式原生图数据库唯一索引的存储方法。
40、第三方面,本发明还提供了一种非易失性计算机存储介质,所述计算机存储介质存储有计算机可执行指令,该计算机可执行指令被一个或多个处理器执行,用于完成第一方面所述的分布式原生图数据库唯一索引的存储方法。
41、区别于现有技术,本发明至少具有以下有益效果:
42、本发明根据已存在数据的唯一属性列,实现创建已存在数据的唯一索引;通过向当前主表插入增量数据,根据所述增量数据的唯一索引的索引键,更新所述当前主表,实现直接对增量数据建立唯一索引;根据待查询数据的索引键查询相应的唯一索引,根据查询到的唯一索引从当前主表中查询到所述待查询数据,实现直接基于唯一索引进行查询;本发明无需向所有当前主表涉及分区上的数据节点发送请求,即可对当前主表进行增删改查操作,优化了各个数据节点在计算过程中的通信交互和网络开销,利用唯一索引提升了对当前主表进行增删改查操作的效率,避免cpu和i/o资源的浪费,极大地提高了数据库系统的整体性能。
- 还没有人留言评论。精彩留言会获得点赞!