一种零知识、免真实数据的模型推理攻击方法
本发明属于数据隐私保护和数据安全的,更具体地,涉及一种零知识、免真实数据的模型推理攻击方法。
背景技术:
1、随着深度学习的快速发展,云计算提供商已经将深度学习作为服务提供给客户,这些服务包括数据可视化、api、人脸识别、自然语言处理、预测分析等。客户只需要像使用其它云服务一样,就可以快速使用人工智能技术,无需安装软件。虽然深度学习作为服务带来了许多便利,但安全问题也接踵而至。即便使用加密技术进行防护,这种端对端的服务模式也不一定安全,在这种模式下,其中一个主要的威胁是由模型推理引起的,被称为模型推理攻击。例如在某些面向服务的应用中,每个用户都可以不受限制的随时访问模型接口。
2、因此,一些恶意用户可能会准确推断出所使用的模型。而深度学习模型往往需要付出昂贵的成本,如时间、数据、金钱,许多公司依靠这种服务盈利,如果这些商业模式被窃取并提供免费的服务(如盗版软件),将损害健康的商业竞争。当模型泄露时,对手可以利用模型反转攻击恢复训练数据,这严重侵犯了数据持有者的隐私,尤其是在医疗和金融领域;许多服务平台将机器学习应用于恶意检测,如垃圾邮件分类和恶意代码检测,对抗者在获取目标模型后,可以构建对抗样本来规避安全检测。因此,必须重视模型的隐私和安全,尤其是在金融、医疗等模型具有巨大经济价值的领域。
3、本发明的目标是提出一种方法,即使是纯粹的通过采样也可以在深度学习作为服务的场景下推断出模型,完成模型推理攻击,这对未来的模型安全和隐私研究具有重要意义。
4、现有的模型推断的方法有很多,其目的也不相同,包括推断目标模型的决策边界、模型结构、参数等信息。tramer等人构建了各种查询样本来获取目标模型的输出,接着结合输入和输出对建立一个方程,通过求解这个方程来重构模型参数。baluja等人建立了一个元模型,将目标模型的输出作为输入,试图推断出目标模型的结构和训练集的统计数据等信息。chandrasekaran等人探讨了主动学习与模型推理之间的关系。hong等人则将模型推理扩展到了超参数的推理。papernot等人使用基于雅各布矩阵的数据增强技术(jbda)来合成样本以捕捉目标模型输出,从而建立相似的替代模型。juuti等人则对jbda进行了推广,使合成数据能让替代模型更专业地执行其它有害行为。这些推理攻击给人们敲响了警钟。
5、中国专利文献cn115329984a提出一种机器学习中的针对属性推理攻击的防御方法,该方法基于原始数据集构造得到伪装数据集,并采用原始数据集和伪装数据集对机器学习模型进行训练,得到投票模型,再基于原始数据集重新构造新的伪装数据集,采用投票模型对新的伪装数据集进行数据筛选,对于新的伪装数据集中的每一条样本,使用投票模型的输出作为其新的标签,完成对新的伪装数据集的重构,将重构后的伪装数据集和原始数据集共同参与训练,生成新的投票模型,重复迭代,直至达到最大迭代次数。该方法在保证机器学习模型效用的前提下提高模型的安全性。
6、以及,中国专利文献cn116361846a提出一种用于使服务抵御个人隐私推理攻击的方法和服务器,由处理器根据效用目标训练聊天机器人的语言模型lm,并由处理器利用个人属性预测器应用一个或多个防御目标,通过使用虚假攻击者模型和具有带注释的数据集的预定义属性,以对聊天机器人的目标lm进行微调,再由处理器使用聊天机器人的目标lm来抵御推理攻击,使得输入并发送到聊天机器人的内容的个人隐私无法被外部预测器预测,从而使聊天机器人的安全级别得到保证。
7、尽管上述的方法实现了好的效果,但对攻击者或攻击场景做了假设和限制。比如,攻击者在攻击过程中知道部分模型结构或训练数据的统计特征、需要一个真实的海量辅助数据集来推断模型、要求攻击者与受害者有物理连接。对于攻击者想获得模型结构或训练数据的统计特征来说具有挑战性。而要求攻击者与受害者有物理连接在云服务提供商向用户提供服务的场景中来说并不合理。这些局限性使得前人的工作不能彻底反映模型推理的威胁。
技术实现思路
1、本发明旨在克服上述现有技术的至少一种缺陷,提供一种零知识、免真实数据的模型推理攻击方法,以解决现有推理攻击方法中攻击者需要知道目标模型和训练集信息才能进行攻击的局限性这一技术问题。
2、本发明详细的技术方案如下:
3、一种零知识、免真实数据的模型推理攻击方法,所述方法包括:
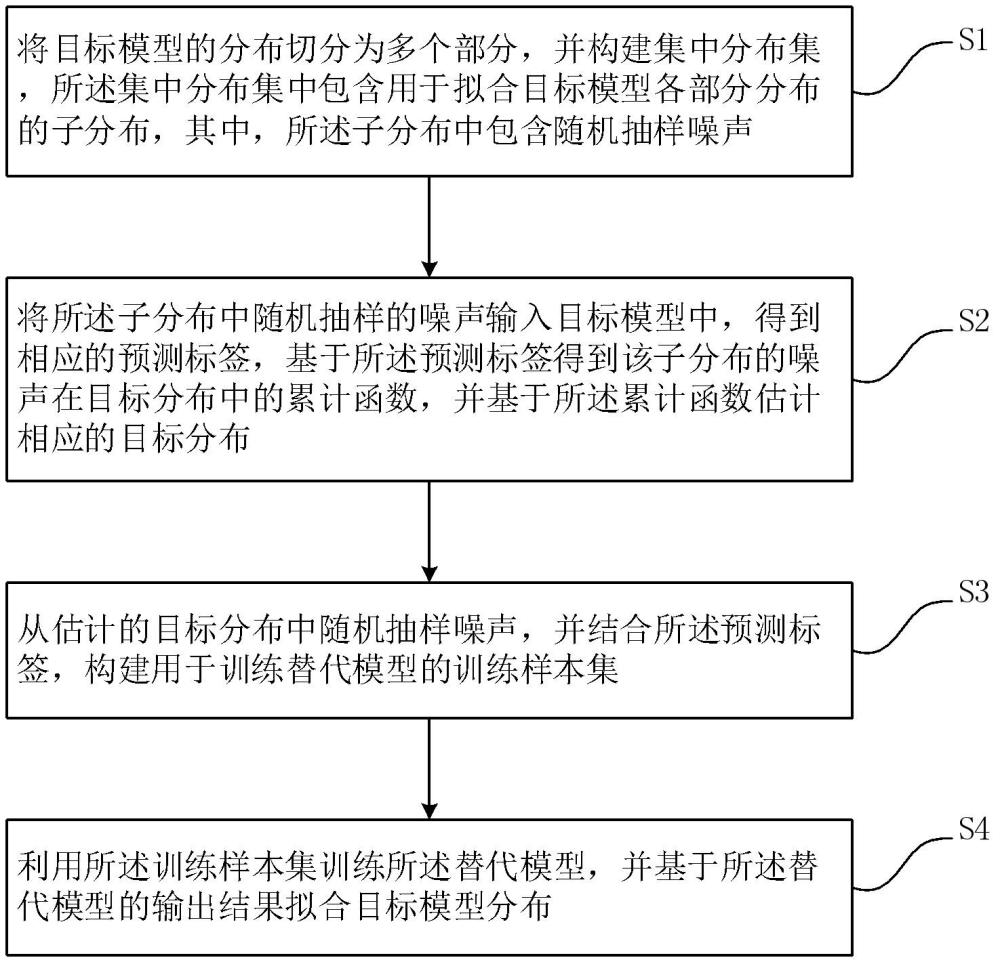
4、步骤s1、将目标模型的分布切分为多个部分,并构建集中分布集,所述集中分布集中包含用于拟合目标模型各部分分布的子分布,其中,所述子分布中包含随机抽样噪声;
5、步骤s2、将所述子分布中随机抽样的噪声输入目标模型中,得到相应的预测标签,基于所述预测标签得到该子分布的噪声在目标分布中的累计函数,并基于所述累计函数估计相应的目标分布;
6、步骤s3、从估计的目标分布中随机抽样噪声,并结合所述预测标签,构建用于训练替代模型的训练样本集;
7、步骤s4、利用所述训练样本集训练所述替代模型,并基于所述替代模型的输出结果拟合目标模型分布,以完成模型推理攻击。
8、根据本发明优选的,所述步骤s1中,所述将目标模型的分布切分为多个部分,并构建集中分布集,具体包括:
9、s11、使用多个集中分布函数构建所述集中分布集,所述集中分布集中包含多个集中分布;
10、s12、从所述集中分布集中随机抽样噪声,并将抽样噪声所在的集中分布标记为子分布。
11、根据本发明优选的,所述步骤s2进一步包括:计算所述估计的目标分布的平均值,以得到目标分布下的期望值,即有:
12、(1)
13、式(1)中,表示估计的目标分布的平均值,表示噪声样本, o表示目标分布,表示目标函数,表示来自目标分布 o中的噪声样本,表示目标分布下的期望值。
14、根据本发明优选的,所述步骤s2中,所述估计的目标分布与随机抽样的噪声之间满足:
15、(2)
16、式(2)中,表示子分布中的随机抽样总数,表示子分布下的期望值;且当趋于无穷大时,越接近于,即估计的目标分布越准确。
17、根据本发明优选的,所述步骤s2进一步还包括:计算目标函数的经验平均值的估计值,以得到目标函数经验平均值的估计值的期望值,即有:
18、(3)
19、(4)
20、式(3)-(4)中,表示目标函数的经验平均值的估计值,表示子分布中的第个噪声样本,表示目标函数经验平均值的估计值的期望值;
21、其中,结合公式(1)可得:
22、(5)
23、式(5)中,表示来自目标分布 o中的第个噪声样本;
24、并结合公式(2)可得:
25、(6)
26、且当趋于无穷大时,有:
27、(7)
28、即,所述目标函数的经验平均值的估计值与估计的目标分布的平均值相等,表示估计的目标分布的平均值为无偏估计。
29、根据本发明优选的,所述步骤s2中,基于所述累计函数估计相应的目标分布,并使用方差衡量估计误差,即有:
30、(8)
31、式(8)中,表示方差,表示从子分布抽样来估计目标函数经验平均值的估计误差,表示子分布的方差。
32、根据本发明优选的,所述步骤s2中,当使用个子分布的累计函数估计相应的目标分布时,估计总误差为:
33、(9)
34、式(9)中,表示个子分布的估计总误差,表示第个子分布,表示从第个子分布抽样的样本输入目标函数中, '表示个子分布中的随机抽样总数,且>;
35、此时,得到估计的目标分布为:
36、(10)
37、式(10)中,表示子分布集,表示子分布集的期望值,表示从第个子分布中随机抽取的第个噪声样本,表示总体目标分布,表示总体目标分布的期望值;
38、根据大数定律,得到以下等式:
39、(11)。
40、根据本发明优选的,所述步骤s4进一步包括:将所述训练样本集输入替代模型,所述替代模型的输出类型为纯标签输出,在该输出类型下,所述替代模型训练过程中的损失函数为:
41、(12)
42、式(12)中,表示纯标签输出下的损失函数,表示噪声样本的真实标签,表示替代模型对标签预测的概率,表示目标分布的概率分布函数,表示训练样本集中的样本总数,表示训练样本集中的样本类别总数,表示类别,的取值为0或1,表示当第个样本为类时取值为1,否则为0,表示第个样本被替代模型预测为类的概率。
43、根据本发明优选的,所述步骤s4进一步还包括:将所述训练样本集输入替代模型,所述替代模型的输出类型为纯概率输出,在该输出类型下,所述替代模型训练过程中的损失函数为:
44、(13)
45、式(13)中,表示纯概率输出下的损失函数,是一个正数,用于调整权重比。
46、与现有技术相比,本发明的有益效果为:
47、(1)本发明提供的一种零知识、免真实数据的模型推理攻击方法,通过构建子分布,并从子分布中随机抽样噪声输入到目标模型中,以得到相应的预测标签和目标分布,然后从得到的目标分布中随机抽样噪声并与预测标签相结合,得到新的数据样本,再将新的数据样本构建为训练样本集用于对替代模型进行训练,以拟合目标分布,从而实现模型推理。
48、(2)本发明利用多个子分布的累计函数来估计相应的目标分布,并通过一系列计算验证以及结合大数定律,验证了当应用多个集中分布来拟合一个更广泛的分布时,只要采样数足够大,最终估计的目标分布就是个合理的无偏估计,保证了本发明方法的合理性及有效性。
49、(3)本发明与现有的爬山法和模拟退火法等方法进行对比,通过对比结果可以看出本发明的方法准确度更高,推理效果更好。
- 还没有人留言评论。精彩留言会获得点赞!