基于云边端协同管理调度的数据处理方法及系统与流程
本技术涉及数据处理领域,具体涉及一种基于云边端协同管理调度的数据处理方法及系统。
背景技术:
1、云边端协同管理调度在生产监测中的应用为企业提供了全面的数据采集、智能分析、远程监控和资源优化等功能,帮助企业提高生产效率、产品质量和资源利用率,推动制造业的智能化转型与升级。通过结合云计算、边缘计算和物联网技术,实现对分布式设备和传感器网络的集中管理和调度。随着制造业的智能化和数字化进程加快,生产过程中产生的大量数据需要高效地采集、处理和分析。云边端协同管理调度为生产监测提供了全面的解决方案。通过边缘设备和传感器节点的部署,可以实时采集生产过程中的各种参数和指标,如温度、湿度、压力等,以及设备状态信息。这些数据通过边缘计算节点进行初步处理和分析,然后传输到云端进行进一步的存储和分析,实现对生产过程的全面监测。云端利用强大的计算和存储资源,对采集到的数据进行深入分析和建模。通过机器学习和人工智能算法,可以实现对生产过程中的异常检测、故障预测和质量优化等功能。这样可以提前发现潜在问题并采取相应的措施,提高生产效率和产品质量。
2、云端在处理相关数据时,用于获取的数据基础非常大,并不会将所有的数据均进行计算,而是获取监测数据中的部分进行处理得到分析结果,但是在数据选取时,如何进行数据的有效筛选直接决定后续的分析结果,如果筛选过密,运算开销过大,而少量筛选不准确,又可能引起分析效果偏离。
技术实现思路
1、本技术提供了一种基于云边端协同管理调度的数据处理方法及系统。
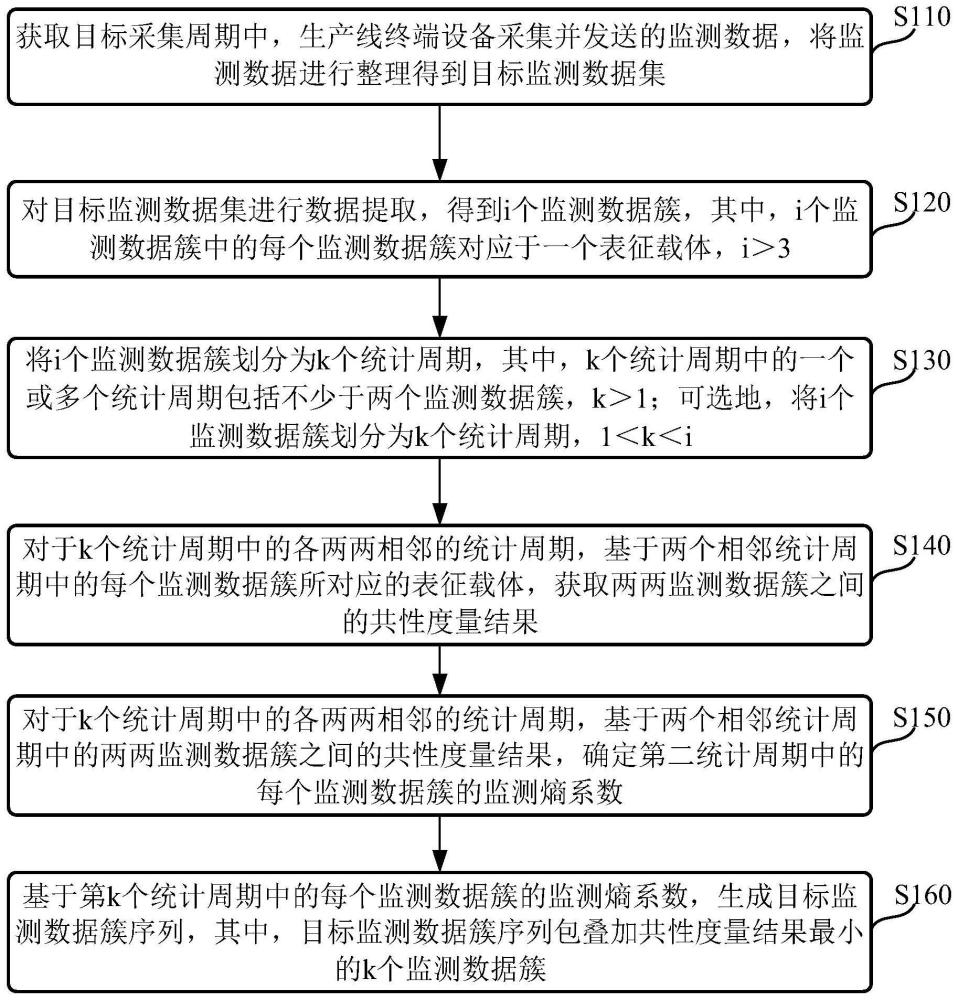
2、根据本技术的一方面,提供了一种基于云边端协同管理调度的数据处理方法,应用于云计算服务器,所述方法包括:
3、获取目标采集周期中,生产线终端设备采集并发送的监测数据,将所述监测数据进行整理得到目标监测数据集;
4、对所述目标监测数据集进行数据提取,得到i个监测数据簇,其中,所述i个监测数据簇中的每个监测数据簇对应于一个表征载体,所述i>3;
5、将所述i个监测数据簇划分为k个统计周期,其中,所述k个统计周期中的一个或多个统计周期包括不少于两个监测数据簇,所述k>1;
6、对于所述k个统计周期中的各两两相邻的统计周期,基于两个相邻统计周期中的每个监测数据簇所对应的表征载体,获取两两监测数据簇之间的共性度量结果;所述两个相邻统计周期包括第一统计周期和第二统计周期,所述两两监测数据簇分别选取自所述第一统计周期和所述第二统计周期,所述第二统计周期为所述第一统计周期邻接的后一统计周期;
7、对于所述k个统计周期中的各两两相邻的统计周期,基于所述两个相邻统计周期中的所述两两监测数据簇之间的共性度量结果,确定所述第二统计周期中的每个监测数据簇的监测熵系数,其中,所述监测熵系数用于表征选取自不同统计周期的全部监测数据簇的最小叠加共性度量结果,所述不同统计周期为包括所述第二统计周期和所述第二统计周期之前的各个统计周期;
8、基于第k个统计周期中的每个监测数据簇的监测熵系数,生成目标监测数据簇序列,其中,所述目标监测数据簇序列包叠加共性度量结果最小的k个监测数据簇。
9、作为一种实施方式,所述对目标监测数据集进行数据提取,得到i个监测数据簇,包括:
10、依据预设提取密度对所述目标监测数据集进行数据提取,得到所述i个监测数据簇;
11、所述对目标监测数据集进行数据提取,得到i个监测数据簇之后,所述方法还包括:
12、将所述i个监测数据簇中的每个监测数据簇作为表征载体抽取算子的输入,依据所述表征载体抽取算子得到所述每个监测数据簇所对应的表征载体;
13、所述将所述i个监测数据簇划分为k个统计周期,包括:
14、如果所述i被k除尽,则得到所述k个统计周期,其中,所述k个统计周期中的每个统计周期包括数量一致的监测数据簇;
15、如果所述i不能被k除尽,则对所述i除以k的值进行往前取整数,得到所述k个统计周期,其中,所述k个统计周期中的j个统计周期分别包括数量一致的监测数据簇,所述k个统计周期中的余下统计周期包括一个或多个监测数据簇,其中,j=k-1。
16、作为一种实施方式,所述对于所述k个统计周期中的各两两相邻的统计周期,基于所述两个相邻统计周期中的所述两两监测数据簇之间的共性度量结果,确定所述第二统计周期中的每个监测数据簇的监测熵系数,包括:
17、对于所述k个统计周期中的各两两相邻的统计周期,对所述两个相邻统计周期中的所述两两监测数据簇之间的共性度量结果进行相反值计算,得到所述两两监测数据簇之间的共性度量结果约束值;
18、对于所述k个统计周期中的各两两相邻的统计周期,基于所述两两监测数据簇之间的共性度量结果约束值与所述第一统计周期中的每个监测数据簇的监测熵系数,确定所述第二统计周期中的每个监测数据簇的监测熵系数。
19、作为一种实施方式,所述基于所述两两监测数据簇之间的共性度量结果约束值与所述第一统计周期中的每个监测数据簇的监测熵系数,确定所述第二统计周期中的每个监测数据簇的监测熵系数,包括:
20、分别对两个监测数据簇之间的共性度量结果约束值与所述第一统计周期中的监测数据簇的监测熵系数进行相加,得到所述第二统计周期中的每个监测数据簇的一个或多个候选监测熵系数,其中,所述两个监测数据簇选取自所述两两监测数据簇;
21、分别在所述第二统计周期中的每个监测数据簇的一个或多个候选监测熵系数中,确定数值最大的候选监测熵系数作为所述第二统计周期中的每个监测数据簇的监测熵系数;
22、所述基于第k个统计周期中的每个监测数据簇的监测熵系数,生成目标监测数据簇序列,包括:
23、获取所述第k个统计周期中的每个监测数据簇所对应的监测数据簇序列,其中,所述监测数据簇序列中,包含用以确定监测熵系数的k个监测数据簇,所述k个监测数据簇中的每个监测数据簇分别选取自所述k个统计周期;
24、基于所述第k个统计周期中的每个监测数据簇的监测熵系数,确定对应最大监测熵系数所对应的监测数据簇;
25、将对应所述最大监测熵系数的监测数据簇所对应的监测数据簇序列确定为所述目标监测数据簇序列。
26、作为一种实施方式,所述对于所述k个统计周期中的各两两相邻的统计周期,基于所述两个相邻统计周期中的所述两两监测数据簇之间的共性度量结果,确定所述第二统计周期中的每个监测数据簇的监测熵系数,包括:
27、对于所述k个统计周期中的各两两相邻的统计周期,将所述两个相邻统计周期中的所述两两监测数据簇之间的共性度量结果作为共性度量结果约束值;
28、对于所述k个统计周期中的各两两相邻的统计周期,基于所述两两监测数据簇之间的共性度量结果约束值与所述第一统计周期中的每个监测数据簇的监测熵系数,确定所述第二统计周期中的每个监测数据簇的监测熵系数。
29、作为一种实施方式,所述基于所述两两监测数据簇之间的共性度量结果约束值与所述第一统计周期中的每个监测数据簇的监测熵系数,确定所述第二统计周期中的每个监测数据簇的监测熵系数,包括:
30、分别对两个监测数据簇之间的共性度量结果约束值与所述第一统计周期中的监测数据簇的监测熵系数进行相加,得到所述第二统计周期中的每个监测数据簇的一个或多个候选监测熵系数,其中,所述两个监测数据簇选取自所述两两监测数据簇;
31、分别在所述第二统计周期中的每个监测数据簇的一个或多个候选监测熵系数中,确定数值最小的候选监测熵系数作为所述第二统计周期中的每个监测数据簇的监测熵系数;
32、所述基于第k个统计周期中的每个监测数据簇的监测熵系数,生成目标监测数据簇序列,包括:
33、获取所述第k个统计周期中的每个监测数据簇所对应的监测数据簇序列,其中,所述监测数据簇序列中,包含用以确定监测熵系数的k个监测数据簇,所述k个监测数据簇中的每个监测数据簇分别选取自所述k个统计周期;
34、基于所述第k个统计周期中的每个监测数据簇的监测熵系数,确定对应最小监测熵系数所对应的监测数据簇;
35、将对应所述最小监测熵系数的监测数据簇所对应的监测数据簇序列确定为所述目标监测数据簇序列。
36、作为一种实施方式,所述基于第k个统计周期中的每个监测数据簇的监测熵系数,生成目标监测数据簇序列之后,所述方法还包括:
37、基于所述目标监测数据簇序列,依据状态推理算法获取目标置信度向量,其中,所述目标置信度向量包括v个状态置信度,所述v≥1;
38、在所述目标置信度向量中存在一个或多个状态置信度不小于预设置信度时,基于所述一个或多个状态置信度,生成所述目标监测数据集所对应的状态推理结果。
39、作为一种实施方式,所述状态推理算法的调试过程包括:
40、获取监测数据簇序列模板库,其中,所述监测数据簇序列模板库包括一个或多个监测数据簇序列模板,每个监测数据簇序列模板包括一组状态注释集合,每组状态注释集合包括一个或多个状态注释;
41、基于所述监测数据簇序列模板库,依据所述状态推理算法获取所述每个监测数据簇序列模板所对应的推理置信度向量,其中,所述推理置信度向量包括v个推理状态置信度;
42、基于所述每个监测数据簇序列模板所对应的推理置信度向量以及状态注释集合,基于第一误差算法对所述状态推理算法的算法配置变量进行优化。
43、作为一种实施方式,所述基于第k个统计周期中的每个监测数据簇的监测熵系数,生成目标监测数据簇序列之后,所述方法还包括:
44、基于所述目标监测数据簇序列,依据异常识别算法获取目标置信度分布,其中,所述目标置信度分布包括不少于两个异常类别置信度;
45、将所述目标置信度分布中的最大异常类别置信度所对应的异常类别作为所述目标监测数据集的数据集异常类别;
46、标注所述目标监测数据集所对应的数据集异常类别;
47、所述异常识别算法的调试过程包括:
48、获取监测数据簇序列模板库,其中,所述监测数据簇序列模板库包括一个或多个监测数据簇序列模板,每个监测数据簇序列模板具有一个标注异常类别;
49、基于所述监测数据簇序列模板库,依据所述异常识别算法获取所述每个监测数据簇序列模板所对应的推理置信度分布;
50、基于所述每个监测数据簇序列模板所对应的推理置信度分布以及标注异常类别,基于第二误差算法对所述异常识别算法的算法配置变量进行优化。
51、根据本技术的另一方面,提供了一种云边端协同管理调度系统,包括终端设备、边缘节点和云计算服务器,所述云计算服务器包括:
52、至少一个处理器;
53、以及与所述至少一个处理器通信连接的存储器;其中所述存储器存储有可被所述至少一个处理器执行的指令,所述指令被所述至少一个处理器执行,以使所述至少一个处理器能够执行以上所述的方法。
54、本技术至少包括如下有益效果:
55、本技术实施例提供了一种基于云边端协同管理调度的数据处理方法,通过对目标监测数据集进行数据提取,得到i个监测数据簇,将i个监测数据簇划分为k个统计周期。如此,对于k个统计周期中的各两两相邻的统计周期,基于两个相邻统计周期中的每个监测数据簇所对应的表征载体,获取两两监测数据簇之间的共性度量结果。再基于两个相邻统计周期中的两两监测数据簇之间的共性度量结果,确定后一个统计周期中的每个监测数据簇的监测熵系数。其中,监测熵系数用于表征选取自不同统计周期的全部监测数据簇的最小叠加共性度量结果。将叠加共性度量结果最小的k个监测数据簇作为叠加共性度量结果最小的目标监测数据簇序列。如此,不仅在每个统计周期中确定一监测数据簇用以生成目标监测数据簇序列,可以减少监测数据簇的数量,缓解运算开销。而且,将选取自不同统计周期中叠加共性度量结果最小的全部监测数据簇作为目标监测数据簇序列,可以让目标监测数据簇序列的可鉴识性更高,摒弃多余重复数据,生产监测的准确性更高。
56、应当理解,本部分所描述的内容并非旨在标识本技术的实施例的关键或重要特征,也不用于限制本技术的范围。本技术的其它特征将通过以下的说明书而变得容易理解。
- 还没有人留言评论。精彩留言会获得点赞!