基于Pytorch的脉冲神经网络突触延时实现方法与流程
本发明涉及神经网络,尤其涉及一种基于pytorch的脉冲神经网络突触延时实现方法。
背景技术:
1、在脉冲神经网络中,神经元发放的脉冲信号会通过突触传递到连接的神经元,而传递的脉冲信号从发送到接收之间存在一定的时间延时,称为突触延时,它可以模拟真实生物神经系统中信号传递的速度与时间相关性。通过调整神经元之间的突触延时,可以实现网络的同步、协调和动态适应性,进而影响网络的功能和行为,因此突触延时至关重要。
2、目前主流的支持突触延时的库和工具各有优势,但也都存在部分缺点与不足:1、灵活性不足,以spinnaker为例,虽然spinnaker可以支持大规模脉冲神经网络模拟,并提供了多种的突触延时选项,但是spinnaker是一个专用的硬件平台,需要特定的硬件和软件工具链支持,相比于通用的计算平台,获取更为不易,因此灵活性有限;2、使用较为复杂,以nest神经模拟工具为例,虽然nest适用于大规模网络仿真,支持自定义神经元类型、突触连接方式以及步长等参数,但是配置和使用nest相对比较复杂,存在一定的学习成本和使用成本;3、计算效率相对较低,以neuron软件工具为例,虽然在neuron中支持更加精细的突触模型分类,也提供了多种突触延时实现的方法,用户在构建神经元模型时可以根据需要灵活选择,但是neuron是基于python开发的,计算效率不如基于c++、cuda实现的脉冲神经网络库。
技术实现思路
1、本发明的目的在于克服现有技术中的不足,提供一种基于pytorch的脉冲神经网络突触延时实现方法,以解决现有支持突触延时的库和工具存在灵活性不足、使用复杂及计算效率低的问题。
2、为解决上述技术问题,本发明是采用下述方案实现的:
3、第一方面,本发明提供了一种基于pytorch的脉冲神经网络突触延时实现方法,用于在pytorch框架下实现一对一连接的突触延时,包括:
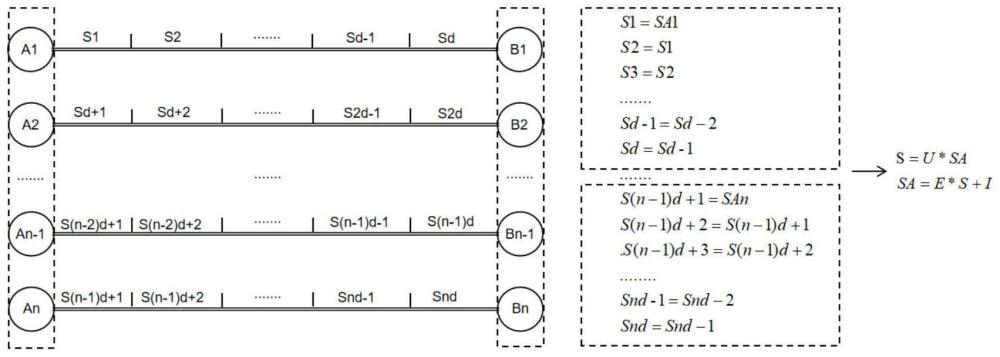
4、步骤a:自定义突触延时d-1;
5、步骤b:创建状态更新矩阵u(n*d,n*d),用于更新突触建模的状态变量;
6、步骤c:创建状态矩阵s(n*d,1),表示当前时间步存储的前后种群神经元传递管道间的所有脉冲信号状态变量;
7、步骤d:创建输入更新矩阵sa(n*d,1),表示当前时间步存储的前种群神经元的脉冲信号状态变量及传递管道前(d-1)个部分的脉冲信号状态变量;
8、步骤e:创建平移矩阵e(n*d,n*d),用于将状态矩阵s(n*d,1)的状态变量更新到输入更新矩阵sa(n*d,1) 的状态变量;
9、步骤f:创建脉冲扩维输入矩阵i(n*d,1),用于储存当前时间步的脉冲信号并更新到输入更新矩阵sa(n*d,1)的状态变量;
10、步骤g:创建脉冲输出矩阵o(n,1),表示后种群神经元的脉冲输入信号;
11、步骤h:创建索引index1,用于计算突触延时的脉冲信号在状态矩阵s(n*d,1)的位置信息;
12、步骤i:创建列表select_list,用于存储后种群神经元接收到的脉冲输入信号数据;
13、步骤j:执行sa=e*s+i,添加当前时间步的脉冲信号并更新输入更新矩阵sa(n*d,1)的状态变量;
14、步骤k:执行s=u*sa,突触建模,更新状态矩阵s(n*d,1)的状态变量,实现脉冲信号前向传递;
15、步骤l:遍历前种群神经元更新index1,并将s[index1]添加到列表select_list,执行o=torch.cat(select_list,dim=0),循环重复步骤j、步骤k,将前种群神经元经过突触延时后的脉冲信号一对一传递给后种群神经元;
16、其中,n表示建立一对一连接的前种群神经元的数量,torch.cat()为pytorch中用于将张量沿指定维度进行拼接的方法。
17、进一步地,状态更新矩阵u(n*d,n*d)初始化为单位矩阵,状态矩阵s(n*d,1)、输入更新矩阵sa(n*d,1)、脉冲扩维输入矩阵i(n*d,1)和脉冲输出矩阵o(n,1)初始化为全零张量矩阵,索引index1初始化为0。
18、进一步地,平移矩阵e(n*d,n*d)为下次对角矩阵。
19、第二方面,本发明提供了一种基于pytorch的脉冲神经网络突触延时实现方法,用于在pytorch框架下实现fromlist连接的突触延时,包括:
20、步骤a:自定义突触延时矩阵d(n,m);
21、步骤b:根据突触延时矩阵d,统计每一行的最大延时d[i],将每一行的最大延时进行累加,得到sum_max_delay;
22、步骤c:创建状态矩阵s((sum_max_delay+n)*m,1),状态矩阵s((sum_max_delay+n)*m,1)包括连接的n段大小为((d[i]+1)*m,1)的状态子矩阵s[i];
23、步骤d:创建状态更新矩阵u((sum_max_delay+n)*m,(sum_max_delay+n)*m),状态更新矩阵u((sum_max_delay+n)*m,(sum_max_delay+n)*m)为n个状态更新子矩阵u[i]填充的对角阵;
24、步骤e:遍历突触延时矩阵d的每一行d[i],根据每一行的最大延时计算状态更新子矩阵u[i],对角填充状态更新矩阵u((sum_max_delay+n)*m,(sum_max_delay+n)*m);
25、步骤f:创建输入更新矩阵sa((sum_max_delay+n)*m,1),输入更新矩阵sa((sum_max_delay+n)*m,1)能够分为n段,第i段sa[i]的大小为((d[i]+1)*m,1);
26、步骤g:创建平移矩阵e((sum_max_delay+n)*m,(sum_max_delay+n)*m),平移矩阵e((sum_max_delay+n)*m,(sum_max_delay+n)*m)能够分为n段,第i段e[i]的大小为((d[i]+1)*m,(d[i]+1)*m);
27、步骤h:创建脉冲扩维输入矩阵i((sum_max_delay+n)*m,1),脉冲扩维输入矩阵i((sum_max_delay+n)*m,1)能够分为n段,i[i]表示前种群第i神经元的脉冲信号;
28、步骤i:创建脉冲输出矩阵o(m,n),o[i][j]表示前种群第(j+1)个神经元对后种群第(i+1)个神经元的脉冲输入;
29、步骤j:创建索引index2,用于计算突触延时的脉冲信号在状态矩阵s((sum_max_delay+n)*m,1)的位置信息;
30、步骤k:执行sa=e*s+i,添加当前时间步的脉冲信号并更新输入更新矩阵sa((sum_max_delay+n)*m,1)的状态变量;
31、步骤l:执行s=u*sa,突触建模,更新状态矩阵s((sum_max_delay+n)*m,1)的状态变量,实现脉冲信号前向传递;
32、步骤m:遍历前种群神经元和后种群神经元更新index2,执行o[i][j]=s[index2],循环重复步骤k和步骤l,将前种群神经元经过突触延时后的脉冲信号对应地传递给后种群神经元;
33、其中,i表示前种群第i个神经元。
34、进一步地,状态矩阵s((sum_max_delay+n)*m,1)的状态子矩阵s[i]、填充状态更新矩阵u((sum_max_delay+n)*m的状态更新子矩阵u[i] 、输入更新矩阵sa((sum_max_delay+n)*m,1)的输入更新矩阵子矩阵sa[i]、脉冲扩维输入矩阵i((sum_max_delay+n)*m,1)的脉冲扩维输入子矩阵i[i]和脉冲输出矩阵o(m,n)的脉冲输出子矩阵o[i][j]初始化为全零张量矩阵,索引index2初始化为0。
35、进一步地,平移矩阵e((sum_max_delay+n)*m,(sum_max_delay+n)*m)为下次对角矩阵。
36、第三方面,本发明还提供一种电子设备,包括存储器、处理器及存储在存储器上并可在处理器上运行的计算机程序,所述处理器执行所述程序时实现第一方面或第二方面中所述基于pytorch的脉冲神经网络突触延时实现方法的步骤。
37、第四方面,本发明还提供一种计算机可读存储介质,其上存储有计算机程序,其特征在于,该计算机程序被处理器执行时实现第一方面或第二方面中任一项所述基于pytorch的脉冲神经网络突触延时实现方法的步骤。
38、与现有技术相比,本发明所达到的有益效果:
39、1、本发明灵活性强,pytorch本身就是一个灵活的深度学习框架,用户可以根据需要自定义模型和计算图,本发明在pytorch框架上实现了脉冲神经网络的突触延时功能,可以在自定义的模型上任意指定突触延时,而且不需要特定的硬件支撑。
40、2、本发明易于使用,对于使用基于pytroch开发的库来说,例如spikingjelly,在使用突触延时功能时,只需指定前后种群的权重矩阵和延时矩阵,直接调用本发明提供的api接口即可,不存在学习成本。
41、3、本发明实现并行计算,pytorch在处理稀疏矩阵乘法时提供了加速方法,并且支持gpu加速和并行计算,本发明在突触建模更新时使用了稀疏矩阵乘法的优化方法,并在gpu上并行处理tensor张量以提高计算效率。
- 还没有人留言评论。精彩留言会获得点赞!