一种结合协变量偏移检测的洪水预测方法与流程
本发明属于水文预报领域,尤其是涉及一种结合协变量偏移检测的洪水预测方法。
背景技术:
1、洪水因具有突发性、多变性、规模性等特点,在生命财产安全,社会生产和经济运行,生态保护等方面造成了巨大破坏。因此实现目标流域内准确的降雨-径流预报对于防洪和水资源利用等方面具有重要意义。传统的物理模型存在对输入数据准确性的要求过高以及建模成本较高等问题。在计算机技术快速发展的背景下,利用人工智能技术实现水文预报是必然的趋势。
2、以传统的循环神经网络为代表的经典时间序列预测模型在应对长期预报任务时往往不能很好地捕捉到降雨和径流量的时间特征和潜在关联。同时在进行数据集的划分时时,外部环境或内部因素的变化往往会导致时间序列数据出现协变量偏移现象导致训练样本和测试样本的分布不一致。
3、因此,如何避免信息丢失和保证训练集与测试集分布的一致性,建立流域内准确的降雨-径流预报机制是目前需要解决的技术问题。
技术实现思路
1、为解决上述技术上的问题,本发明提供一种结合协变量偏移检测的洪水预测方法,此预测方法可有效解决信息丢失和数据分布不平衡的问题。
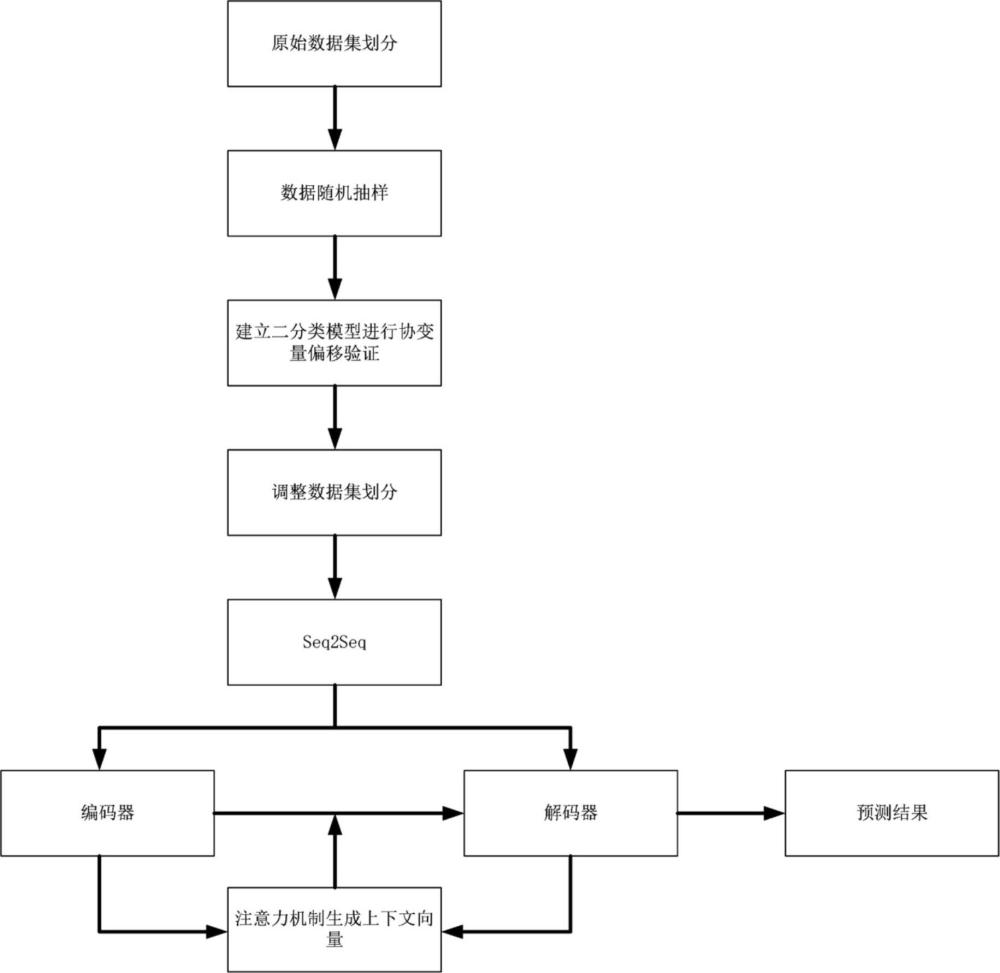
2、为了实现上述的技术特征,本发明的目的是这样实现的:一种结合协变量偏移检测的洪水预测方法,包括以下步骤:
3、s1.搜集预报区间内各降雨观测站的降雨数据与径流数据构建数据集;输入部分为待预测时间段之前连续多小时的降雨量和径流量,标签部分为待预测时间段的径流序列;
4、s2.将s1得到的数据集经过符号聚合近似算法进行压缩,按一定比例初步划分为训练集与测试集并插入分类标签,分别对训练集与测试集进行等量随机采样,得到新的数据集;
5、s3.将s2中得到的数据集用于二分类模型的训练与预测,将分类模型的预测结果与真实分类做相关性分析,根据相关性分析结果动态调整原始数据集训练集与测试集的比例,得到最佳划分结果;
6、s4.将s3中得到的训练集送入引入注意力机制的由单层lstm构成的seq2seq模型进行训练,得到径流预报模型;
7、s5.将s3中测试集任意场次的各观测站的降雨量和历史径流量作为s4中得到的径流预报模型的输入,得到对应的径流预测值。
8、在步骤s1中所述的数据集构建过程为:
9、s11.搜集预报区间内的水文数据,包括各降雨观测站点的降雨量数据以及径流量数据,构成原始数据集d;
10、s12.对s11中得到的原始数据集d的各特征进行线性归一化处理,等分为多个预报场次并进行打乱,形成数据集,线性归一化过程如下式所示:
11、
12、其中:表示第 i个特征的第 j个数值,和分别表示第 i个特征中的最大值和最小值,为第 i个特征的第 j个数值的线性归一化结果。
13、所述s2包含以下步骤:
14、s21.将s1得到的数据集以场次为基本单位,利用符号聚合近似算法进行压缩处理,将降雨-径流场次转化为二进制数表达的一维向量,形成数据集;
15、s22.将s21得到的数据集按照一定比例划分为训练集与测试集,其中训练集当中的场次数取值区间为(m,n),取值下界为m,取值间隔为1,取值上界为n;
16、s23.对训练集与测试集分别插入分类标签,记训练集中数据类型为0,测试集中数据类型为1;
17、s24.在训练集和测试集中分别随机采集数量相同的样本,对其打乱并构成新的数据集。
18、所述s3包含以下步骤:
19、s31.将s2中得到的数据集按8:2的比例划分为训练集与测试集;
20、s32.构建二分类模型,将s31中得到的训练集送入模型用于分类任务的训练;
21、s33.将s31中的测试集送入s32中已训练完成的二分类模型,利用马修斯相关系数将模型的分类结果与测试集的真实分类情况进行相关性分析,马修斯相关系数的计算如下式所示:
22、
23、其中: tp与 tn代表真阳性与真阴性样本的数量, fp与 fn代表假阳性与假阴性的数量,为计算求得的马修斯相关系数;
24、s34.将s22中训练集大小的取值区间等分为多个子区间,并逐步地计算每一个取值点对应的 mcc值;
25、s35. 将训练集样本容量纳入考虑因素与s34中计算得到的各子区间的马修斯相关系数的最小值进行分别进行加权处理求得 p值,计算过程如下式所示:
26、
27、其中: c为每个子集中的场次数, n为场次总数, y为训练集包含的子集数,与 b分别为马修斯相关系数和样本容量的权重, p值越小,证明数据集的划分越合理。
28、所述s4包含以下步骤:
29、s41.编码器中的每个lstm单元产生输出的过程如下式所示:
30、
31、其中:与分别为作为时刻编码器输入的隐藏状态变量与细胞状态,为训练集时刻的样本输入,为构成编码器的lstm单元所定义的映射关系,与分别为时刻编码器输出的隐藏状态变量与细胞状态;
32、s42. 在引入注意力机制后,将解码器在时刻的隐藏状态输出作为查询,编码器各状态的隐藏变量作为键与值进行上下文向量的生成,引入注意力机制的解码器的工作过程可用下式进行描述:
33、
34、
35、
36、
37、其中:为作为时刻解码器输出的隐藏状态与编码器各时刻隐藏状态的相关性评分,tanh与 softmax为激活函数,分别为查询,键和值的权重矩阵,为全连接层定义的线性映射关系,为编码器各时刻状态变量根据相关性评分进行加权求和得到的上下文向量,将上下文向量与隐藏状态拼接传入全连接层得到的结果为解码器在时刻产生的输出结果;
38、s43. 以真实值与预测值的均方根误差为损失函数,利用训练集不断迭代模型,当达到迭代终止条件时,停止训练输出,得到最终的降雨-径流预测模型,预测预报区间内的径流值大小。
39、所述s4中用于构建seq2seq模型的lstm单元,其结构为下式所示:
40、
41、
42、
43、
44、
45、
46、其中:与为lstm单元的细胞状态与隐藏状态输入,为特征序列 t时刻的值,为各门控单元可学习的参数矩阵,为各门控单元的偏置参数,与为激活函数,分别为遗忘门,输入门与输出门的输出结果,为经过输入门更新后的细胞状态,与为lstm单元的隐藏状态与细胞状态输出。
47、所述s11中,各站点的降雨量和径流量采样的固定间隔δt为1小时。
48、所述s21包含以下步骤:
49、s211.将历史降雨与径流数据等分为长度为w的子序列,使用各子序列的方差进行表征;
50、s212. 选定字符集大小,根据断点表格将代表每一子序列的方差转化为对应的字符,即将原始序列转化为一段字符串,将其进行one-hot编码,得到用于表征原始降雨数据集的one-hot编码矩阵,其中矩阵中的每一行代表一个降水场次。
51、所述s211中w的取值与输入历史序列长度相等。
52、本发明有如下有益效果:
53、1.本发明基于预报区间的降雨-径流数据,通过注意力机制在解码过程中对历史信息进行过滤,使其被赋予合适的权重,令模型具有更好的上下文信息融合能力和关键信息的表达能力。
54、2.本发明通过sax算法结合二分类模型实现了对数据集的协变量偏移检测,并采用马修斯相关系数对分布的一致性进行量化,通过与训练集样本容量的综合考虑进行数据集的划分。同时实现了对数据集分布一致性和训练集数据多样性的保证,增强了模型的泛化能力。
- 还没有人留言评论。精彩留言会获得点赞!