预测模型生成方法、PM2.5预测方法、系统和计算设备
本发明涉及时间序列预测,更具体地说,本发明涉及一种预测模型生成方法、pm2.5预测方法、系统和计算设备。
背景技术:
1、近年来,绿色生态文明理念深入人心,而pm2.5是空气中的可吸入人体颗粒物,在大气中的停留时间长,输送距离远,对人体健康和大气环境质量的影响较大,准确预测pm2.5浓度,对于指导生产生活意义重大。然而,综合各种条件的情况下,准确预测pm2.5浓度的难度比较大。目前,对于pm2.5浓度的预测方法主要有两类,一类为统计学预测方法,另一类为基于机器学习的预测方法。时间序列预测(time-series forecasting)一直是机器学习的重点领域,在现实中是比较基础却又十分重要的研究场景。因为时间序列预测的历史数据量大、计算复杂性高,以及对预测精度的要求较高,成为序列预测研究的难点。而对于pm2.5浓度预测领域的方法及其效果也还有进步的空间。
2、pm2.5浓度受人类活动和天气条件如温度、大气压等不确定因素的影响,一些单变量预测方法仅基于pm2.5浓度本身的历史数值对未来时刻进行预测,在准确度上难免有待商榷。而多变量预测综合考虑多方面因素,不仅基于pm2.5浓度历史数值,还涉及其他影响pm2.5浓度的条件。在影响pm2.5浓度的变量中,不仅存在对其不利的变量条件如so2浓度,还会有温度等对pm2.5浓度有积极影响的因素。
3、分类研究可以细致化处理数据信号,提取到更有用的信息,提高预测准确度。在统计学中,皮尔逊相关系数(pearson correlation coefficient)是用于度量两个变量x和y之间的相关性。利用皮尔逊相关系数逐一分析特征变量和pm2.5浓度变量之间的相关性,筛选出正负相关的特征变量,然后进行正、负相关变量分类,并映射变量到高维空间,捕捉对pm2.5浓度影响较大的数据信号。
4、transformer是一种使用自注意力机制(self-attention)实现的神经网络模型,同时也是最近几年被广泛研究的深度学习模型之一。它可以并行处理输入序列信息,从而加速计算并提高模型性能。transformer模型计算量较大、复杂性高。但近年来芯片处理性能有巨大的提升,很好解决了性能不足导致训练速度慢的问题。如果运用transformer处理时间序列预测领域的问题,其成本较高,性价比低。利用简单的transformer编码器,再经过mlp感知器和linear线性层生成预测结果,可以降低成本,提高性价比,还可以保证并行处理序列信号,加快训练速度,提高预测准度。关于优化算法adam对于模型处理稀疏数据问题具有优势,且收敛速度快,但在训练后期有可能使模型达不到全局最优。
技术实现思路
1、本发明的目的在于克服现有技术的不足,设计开发了一种预测模型生成方法、基于transformer的多变量分类研究的pm2.5预测方法、系统和计算设备,利用皮尔逊相关系数计算不同特征变量和pm2.5浓度之间的相关性并对变量进行分类,再通过简单的transformer编码器、mlp感知器和linear线性层构建网络模型,并利用组合优化算法adam和sgd调优模型,从而实现对pm2.5浓度的预测。
2、为了实现本发明的这些目的和其它优点,本发明提供的一种预测模型生成方法,包括:
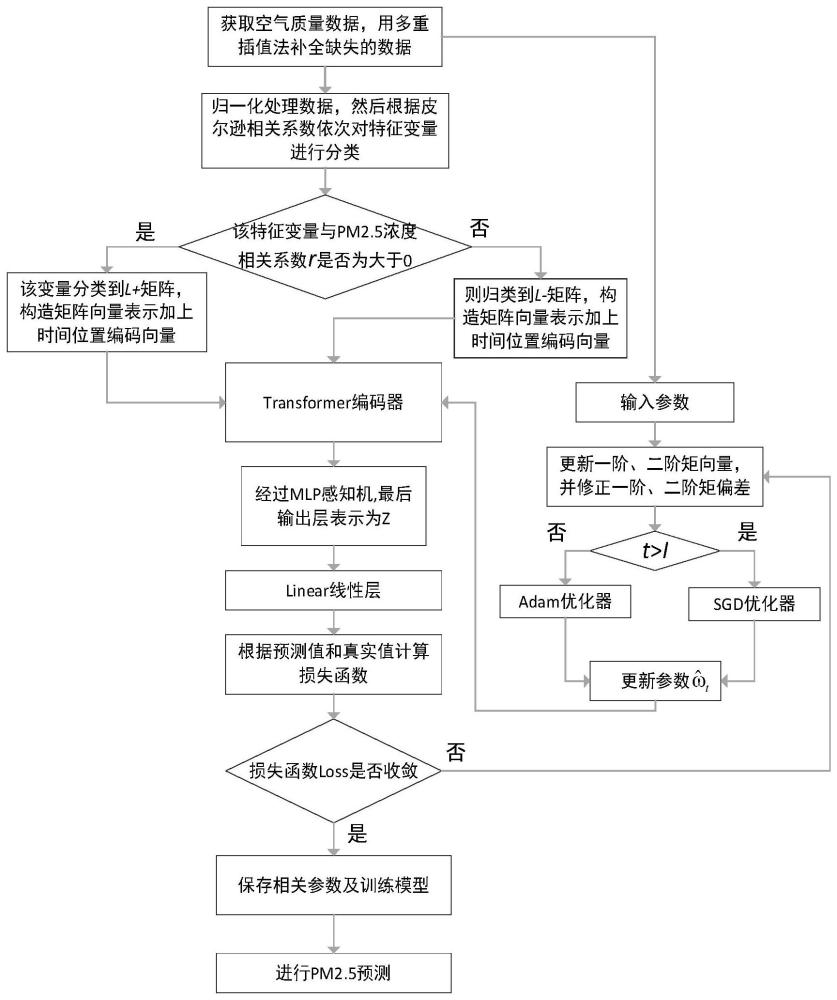
3、获取历史数据;根据预测目标运用皮尔逊系数对所得历史数据进行正负相关分类;根据分类,构造正负相关的输入矩阵向量,加上时间序列位置编码,得到模型输入向量;将所得模型输入向量输入构建好的网络模型中,所述网络模型包括简单的transformer编码器、mlp感知器、linear线性层;调用优化组合算法adam和sgd进行调优,直至网络模型的损失函数收敛,得到训练好的预测模型。
4、优选的是,所述的预测模型生成方法具体包括:
5、获取采样站点一段时间的历史数据;若其中某个时刻含有缺失值的数据,利用多重插值法填补缺失值,得到完整的历史数据集;
6、对历史数据集进行归一化处理;
7、运用皮尔逊相关系数计算归一化处理数据中特征变量和预测目标变量的相关性,系数rb>0为正相关,反之则为负相关,然后根据系数大小将特征变量进行正负相关分类;
8、根据分类,构造两个正负相关的输入矩阵向量,得到每个数据的嵌入向量,矩阵大小均为l+,-∈r4*n;模型输入向量表示由数据嵌入向量矩阵加上预测目标数据对应的每个时刻的时间序列位置编码得到;
9、将相加后的输入向量表示l+和l-输入到构建好的网络模型中,该网络模型由简单的transformer编码器、mlp感知器、linear线性层组成;
10、首先经过简单的transformer编码器,将注意到的信号数据映射为潜在的向量表示z+,-,映射表示为l++pe=l+→z+和l-+pe=l-→z-;
11、生成的向量表示z+,-,经过mlp感知器,最后的输出层表示为:
12、最后经过平整的linear线性层,输出未来时刻的预测值,用均方误差来计算预测值与真实值之间的误差,测量预测值与真实值之间的匹配程度;当损失函数loss收敛时,停止训练,得到相关参数及预测模型;否则,调用优化算法调整相关参数;
13、优化算法adam和sgd组合优化预测模型参数,在模型训练前期,利用adam优化器的优势,加速下降梯度,加快模型收敛;当t≥i(i=sum(x)/2)时,切换到优化器sgd充分调优参数,以稳定模型,让预测模型达到全局最优。
14、本发明提供的一种基于transformer的多变量分类研究的pm2.5预测方法,利用任一所述预测模型生成方法生成的预测模型进行pm2.5预测。
15、优选的是,所述的基于transformer的多变量分类研究的pm2.5预测方法中,历史数据包括:时间,温度,大气压,风速,so2,o3,no2,pm2.5浓度数据。
16、优选的是,所述的基于transformer的多变量分类研究的pm2.5预测方法中,so2,no2,大气压与pm2.5浓度为正相关;温度,o3,风速与pm2.5浓度数据为负相关。
17、优选的是,具体的,一种基于transformer的多变量分类研究的pm2.5预测方法,操作步骤如下:
18、1)获取某地区不同采样站点过往12小时~5年的空气质量数据,监测时间间隔1小时。优选的是,针对其中某个时刻含有缺失值的数据,利用多重插值法填补缺失值。同时,输入优化组合算法所需的相关参数。
19、2)对于处理好的数据集进行归一化处理,将数据集按一定的比例划分为训练集和测试集。优选的是,按7:3的比例划分为训练集和测试集。
20、3)运用皮尔逊相关系数计算特征变量和pm2.5浓度变量的相关性,系数rb>0为正相关,反之则为负相关,然后根据系数大小将特征变量进行正负相关分类。
21、4)根据分类,构造两个正负相关的输入矩阵向量,得到每个数据的嵌入向量,矩阵大小均为l+,-∈r4*n。模型输入表示由数据嵌入向量矩阵加上pm2.5浓度数据对应的每个时刻的时间序列位置编码得到。
22、5)将相加后的输入向量表示l+和l-输入到构建好的网络模型中,该网络模型由简单的transformer编码器、mlp感知器、linear线性层组成。
23、首先经过简单的transformer编码器,将注意到的信号数据映射为潜在的向量表示z+,-,映射表示为l++pe=l+→z+和l-+pe=l-→z-。
24、6)生成的向量表示z+,-,经过mlp感知器,最后的输出层表示为:
25、7)最后经过平整的linear线性层,输出未来时刻的预测值,用均方误差(mse)来计算预测值与真实值之间的误差,测量预测值与真实值之间的匹配程度。当损失函数loss收敛时,停止训练,保存相关参数及模型。否则,调用优化算法调整相关参数。
26、8)根据选择的组合优化算法adam和sgd优化pm2.5浓度预测模型参数,在模型训练前期,利用adam优化器的优势,可以加速下降梯度,加快模型收敛。当t≥i(i=sum(x)/2)时,切换到优化器sgd充分调优参数,以稳定模型,让pm2.5浓度预测模型达到全局最优。
27、9)将训练好的pm2.5浓度预测模型用于未来时刻的pm2.5预测。
28、一种pm2.5预测系统,包括:
29、数据获取模块,其配置为采样站点一段时间的历史数据;
30、分类模块,其配置为根据预测目标运用皮尔逊系数对所得历史数据进行正负相关分类;
31、输入向量生成模块,其配置为根据分类,构造正负相关的输入矩阵向量,加上时间序列位置编码,得到模型输入向量;
32、网络模型模块,其配置为将模型输入向量依次经简单的transformer编码器、mlp感知器、linear线性层处理;
33、调优模块,其配置为组合算法adam和sgd进行调优,直至网络模型的损失函数收敛。
34、优选的是,所述的pm2.5预测系统中,还包括归一化处理模块,其配置为对历史数据进行归一化处理。
35、一种计算设备,包括处理器和存储器,所述存储器中存储有可执行代码,所述处理器执行所述可执行代码时,实现任一项所述的预测模型生成方法或pm2.5预测方法。
36、本发明至少包括以下有益效果:
37、1、运用皮尔逊系数相关性对多变量特征进行分类,从正负相关两方面处理数据信号,有效提升预测准确度。
38、2、不限于特定领域,改变特定的参数可应用于其它领域的预测分析,无需重新构建模型,具有灵活性和迁移性。
39、3、使用简单的transformer编码器,以及优化参数组合算法adam和sgd调优,在保留可并行训练模型的同时,加快训练速度,快速稳定模型性能。关于优化算法adam对于模型处理稀疏数据问题具有优势,且收敛速度快,但在训练后期有可能使模型达不到全局最优。因此,在训练后期切换sgd(随机梯度下降)优化算法精调参数。综合利用两者的优势,前期加速训练,在训练后期则逐渐精调参数使模型性能稳定,让最终的pm2.5浓度预测模型达到全局最优。
40、4、对设备性能要求不高,有效降低成本。
41、本发明的其它优点、目标和特征将部分通过下面的说明体现,部分还将通过对本发明的研究和实践而为本领域的技术人员所理解。
- 还没有人留言评论。精彩留言会获得点赞!