一种基于改进的WMD文本相似度计算方法及装置与流程
本技术涉及文本处理领域,尤其涉及一种基于改进的wmd文本相似度计算方法及装置。
背景技术:
1、自然语言处理领域一直以来都是人工智能研究的热点之一。随着互联网和信息爆炸的时代来临,文本数据的增长呈现出爆炸性的趋势,对文本理解和处理的需求也越来越迫切。在这个背景下,文本相似度计算成为自然语言处理领域的一个核心问题,它涉及信息检索、推荐系统、文本聚类等多个应用领域。
2、目前,基于词向量的文本相似度计算已经取得了一定的成果,其中word mover'sdistance(wmd)是一种常用的算法。然而,传统的wmd算法存在一些缺陷,主要体现在以下几个方面:1.未考虑上下文语法结构信息,传统wmd算法主要关注词向量之间的距离,而忽略了词在句子中的上下文语法结构信息。在一些语境复杂的句子中,忽略上下文可能导致相似度计算的误差;2.忽略词序信息的影响,传统wmd算法没有考虑词的顺序对相似度计算的影响。然而,同样的词汇在不同的顺序中可能表达出截然不同的语义;3.对语境依赖性较强,传统wmd算法在处理一些特定语境下的文本时,由于缺乏对语境的深层次理解,可能导致相似度计算的不准确。
3、在当前自然语言处理领域,许多应用场景都需要高效准确的文本相似度计算。信息检索、智能问答、情感分析等领域对文本相似度计算提出了更高的要求。然而,传统方法在处理上述问题时存在明显缺陷。
4、本发明通过引入依存句法分析,将上下文语法结构信息融入文本相似度计算中,从而更好地捕捉词在句子中的语法关系。通过节点加权向量的设计,考虑了节点距离的权重,使得在文本相似度计算中更加灵活。同时,通过对子树边权重的计算,解决了传统方法对于词序信息和依赖程度信息的忽视。本技术的创新点主要体现在对语法结构信息的深度挖掘,以及对节点距离和边权重的精准考虑。
技术实现思路
1、本技术的目的在于提供一种基于改进的wmd文本相似度计算方法及装置,解决上述的问题。
2、本技术的目的采用以下技术方案实现:
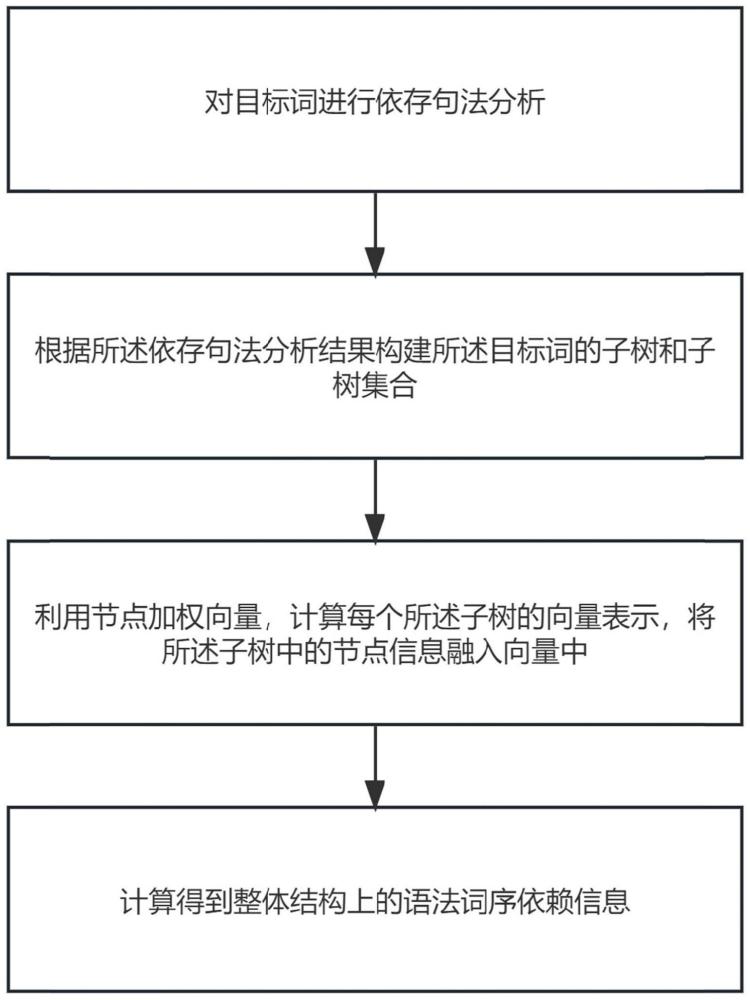
3、第一方面,本技术提供了一种基于改进的wmd文本相似度计算方法,包括以下步骤,对目标词进行依存句法分析;根据所述依存句法分析结果构建所述目标词的子树和子树集合;利用节点加权向量,计算每个所述子树的向量表示,将所述子树中的节点信息融入向量中;计算得到整体结构上的语法词序依赖信息。
4、该技术方案的有益效果在于:通过引入依存句法分析,该方法能够更全面地捕捉文本中词之间的语法结构关系,从而实现更准确的语义建模;传统wmd算法可能忽略上下文信息,而该方法通过子树集合的构建,充分考虑了上下文语法结构,提升了对文本语义的理解能力;依存句法分析结果的引入使得该方法对语境依赖性更加敏感;通过引入超参数m来控制子树集合的构建,可以根据具体应用场景和需求进行灵活地调节;通过综合考虑词义、词序和语法结构等多方面信息,该方法在文本相似度计算方面具有更高的准确性。
5、在对所述目标词进行依存句法分析前还包括:
6、对文本数据进行清理,去除停用词等无关信息,为每个词生成词向量表示并构建向量矩阵。
7、该技术方案的有益效果在于:通过在依存句法分析之前进行文本数据清理,去除停用词等无关信息,可以减少分析的文本数据量,提高计算效率,这对于大规模文本数据的处理尤为重要,可以有效降低计算成本和时间复杂度;在清理后的文本数据上生成词向量,可以避免无关信息对词向量表示的干扰,清理后的文本更加集中于关键信息,有助于生成更具代表性的词向量,提高了文本表示的质量;清理文本数据并生成词向量时,可以更加关注上下文信息,识别并保留对依存句法分析有帮助的信息,这有助于提高文本相似度计算对语境信息的理解和利用能力。
8、对目标词进行依存句法分析的具体步骤为,确定中心词,基于所述中心词确定依存项,基于所述中心词和所述依存项构建以所述中心词为基础的树状结构。
9、该技术方案的有益效果在于:通过确定中心词和依存项,可以清晰地识别出目标词与其他词之间的语法关系,这有助于理解句子的结构,使得依存树更加直观和易于解释;中心词的确定有助于更准确地确定依存项,从而构建准确的依存关系,这种准确性对于理解词与词之间的语法联系至关重要,尤其是在复杂的句子结构中;以确定的中心词为基础构建树状结构,使得分析结果更加集中于目标词的语法环境,这有助于聚焦于与目标词相关的语法信息,提高了对目标词上下文的关注度;构建以中心词为基础的树状结构有助于后续的处理和分析,例如,在计算子树向量或者进行其他特征提取时,树状结构的清晰性使得处理步骤更加顺利和可控。
10、所述中心词与所述依存项间存在依存关系,所述依存关系包括nsubj、obj、iobj、csubj、nmod、amod、compound、fixed、obl;
11、其中nsubj表示名词主语关系;obj表示宾语关系;iobj表示间接宾语关系;csubj表示从句主语关系;nmod表示名词修饰语关系;amod表示形容词修饰语关系;compound表示复合表达式关系;fixed表示固定表达式关系;obl表示间接名词关系。
12、该技术方案的有益效果在于:通过包括不同类型的依存关系,能够提供更全面、更多样化的语法信息,不同类型的依存关系涵盖了不同的语法结构,如主谓关系、修饰关系、从句关系等,这使得该技术方案能够适应包括复杂结构在内的多种语法形式,提高了适应性和通用性,由于涵盖了多种依存关系类型,该技术方案适用于不同的自然语言处理任务,如信息检索、问答系统、机器翻译等,满足了不同任务对不同依存关系分析的需求。
13、根据所述依存句法分析结果构建所述目标词的子树中包括m阶子树,所述m为超参数,不同的所述m对应形成不同层级的所述子树,将不同层级的所述子树归为同一集合即为所述子树集合。
14、该技术方案的有益效果在于:对于不同复杂性的文本,可以通过调整m的值来适应,当处理简单的句子时,可以选择较小的m值,而对于复杂结构的句子,可以选择较大的m值,以覆盖更多的语法层次。
15、根据所述依存句法分析结果构建所述目标词的子树和子树集合还包括,计算子树集合之间的距离来表示两条文本中两个目标词的上下文语法结构上的距离。
16、该技术方案的有益效果在于:通过计算子树集合之间的距离,系统可以更全面地比较两个目标词在语法结构上的相似性,这种方法不仅考虑了单一子树的特征,还考虑了不同子树之间的关系,使得相似度计算更加全面。
17、子树中节点加权的向量具体为:
18、
19、k表示非当前节点距离当前节点的距离,表示词i的词向量,k的取值基于与当前节点的距离,与当前节点相邻的距离为1,与当前节点间隔一个节点距离为2,以此类推。
20、该技术方案的有益效果在于:对于子树中的每个节点,使用一个权重向量来表示该节点,并且权重向量中的每个元素都通过一个指数衰减函数进行计算,这个权重向量的计算考虑了节点与目标节点的距离,距离越近的节点在权重向量中的影响越大,距离越远的节点在权重向量中的影响越小,这种设计的目的是捕捉子树结构中节点之间的语法关系,同时对距离远的节点进行较弱的考虑。
21、对所述子树中的所有边进行边权重求和平均,得到整体结构上的语法词序依赖信息,其中所述边权重为反映词序信息及词之间依赖程度的量,所述边权重求和平均为子树结构上词和词之间词序信息及依赖程度的一个反映,a指向b边权重为记为,计算表达式如下:
22、
23、对子树边权重求和平均得到整体结构上的语法词序依赖信息,记为ee,表达式如下:
24、
25、其中,fa→b表示语料库中所有同时包含词a和词b的文本并且依存分析形成的子树中词a指向词b出现次数。fab表示语料库中词a和词b同时出现的次数,e表示子树边个数,vadj表示子树相邻节点对集合。
26、该技术方案的有益效果在于:这样的设计可以反映词之间的语法关系,考虑了它们在语料库中的共现以及依存关系,进而综合考虑了词序信息及词之间的依赖程度,这种方法能够更全面地捕捉文本结构中词与词之间的关系,有助于提高文本相似度计算的准确性
27、所述子树向量表示为:
28、
29、其中,v表示子树节点集合,|v|表示子树节点个数。
30、该技术方案的有益效果在于:通过加权节点向量的方法,考虑了子树中不同节点对整体结构的贡献。
31、对所述子树中的所有边进行边权重求和平均,得到整体结构上的语法词序依赖信息还包括:
32、选取两个词i和j;
33、计算各自包含i和j的两个子树向量的欧几里得距离;
34、计算两个词向量的余弦距离;
35、根据所述两个词向量的余弦距离和包含两个词的子树的欧几里得距离计算词i和j的距离表达式;
36、依据表达式和wmd算法确定整体结构上的语法词序依赖信息。
37、该技术方案的有益效果在于:通过考虑两个词在子树向量空间中的距离,综合考虑了它们的语法和语义的相似性,使得结果更加精确。
38、两个子树向量的欧几里得距离,表达式如下:
39、de=||si-sj||2
40、其中,si和sj分别表示包含词i的子树向量和包含词j的子树向量。
41、两个词向量的余弦距离表达为:
42、
43、其中,和分别表述词i和词j的词向量,表示词向量和的余弦距离。
44、两条文本中词i和词j距离ci,j表达式如下:
45、
46、其中,si和sj分别表示包含词i的子树集合和包含词j的子树集合,|si|和|sj|分别表示两个子树集合包含子树的个数,α表示词i子树集合和词j子树集合之间距离的权重,其值越大,表示两个词上下文语法结构信息上的距离对两个词距离计算影响越大,两个词的词向量语义距离对两个词距离计算影响越小。
47、第二方面本技术提供一种计算机可读存储介质,能够实现上述内容中任一项所述的文本相似度计算方法。
- 还没有人留言评论。精彩留言会获得点赞!