一种基于边界互信息的跨模态哈希检索方法
本发明涉及计算机视觉领域的大数据处理及分析,特别涉及哈希优化算法和跨模态检索方法。
背景技术:
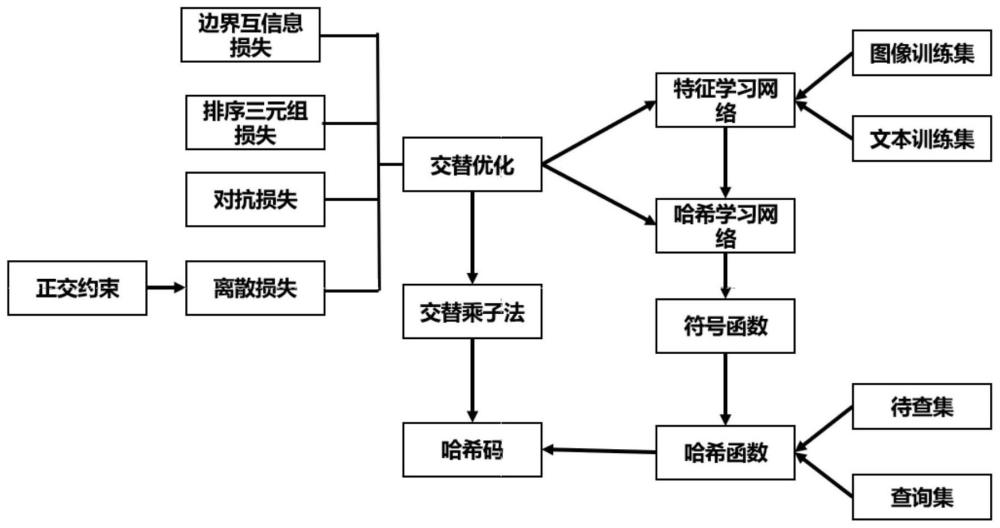
1、随着技术的不断发展和突破,信息开始通过多媒体进行传输,大规模的跨模态检索在日常生活中得到了广泛的应用。跨模态检索是一种信息检索任务,旨在从不同的媒体或模态中检索相关内容或数据。由于不同模态的特征表示不同,语义鸿沟仍是亟需解决的问题。与此同时,检索任务的时间成本和存储成本迅速上升。哈希作为一种高效的方法,由于其存储容量小、检索效率高的优点,已被广泛采用,跨模态哈希检索应运而生。跨模态哈希检索是一种跨模态检索任务,通过构建哈希函数将不同模态的数据映射到一个共享的哈希空间,以便能够快速且有效地在不同模态之间检索相关内容。一方面,哈希函数将高维原始特征映射成低维哈希码,同时保留了原始的相似结构,这大大降低了计算成本,提高了检索速度。另一方面,设计有效的损失函数和匹配策略是跨模态哈希检索的关键。这些损失函数通常衡量了在哈希空间中模态之间的相似性,以便在检索时能够获得相关的跨模态结果。然而,如何弥合异构鸿沟、保持语义一致性、减小信息冗余仍是跨模态哈希检索需要解决的问题,同时,因为哈希码是离散的,其优化问题是一个np问题,如何高效优化也成了该领域的另一难题。
技术实现思路
1、为了克服现有跨模态哈希检索方法中存在的异构鸿沟、信息冗余等问题,本发明提供一种优化算法收敛、检索精度高的基于边界互信息的跨模态哈希检索方法,引入了对抗学习来减少异构鸿沟,并提出了基于边界互信息的目标函数以保持语义一致性,同时在哈希码上添加了正交约束以减少信息冗余,并采用交替方向乘子法(admm)算法和随机梯度下降法对哈希函数进行优化,进而得到哈希函数,使用哈希函数将图像和文本转换为哈希码,检索时使用哈希码进行图文检索。
2、本发明解决其技术问题所采用的技术方案是:
3、一种基于边界互信息的跨模态哈希检索方法,其特征在于,所述方法包括以下步骤:
4、步骤1:构建特征学习网络和哈希学习网络,特征学习网络和哈希学习网络均由多层全连接层组成的生成对抗网络构成,过程如下:
5、步骤1.1:构建特征学习网络,特征学习网络由两个生成网络和一个判别网络构成;
6、步骤1.2:构建哈希学习网络,哈希学习网络由两个生成网络和一个判别网络构成,
7、步骤2:构建哈希函数与量化损失,过程如下:
8、步骤2.1:对哈希学习网络的最后输出作符号运算;
9、步骤2.2:哈希函数的定义是特征空间到汉明空间的映射函数。由哈希函数的定义构建哈希函数;
10、步骤2.3:构建量化损失。量化损失由离散损失组成,并添加正交约束以减小哈希码的信息冗余;
11、步骤3:相似性保持损失构建,由排序余弦三元损失、边界互信息损失组成;
12、步骤4:目标函数优化,运用交替优化的方法对网络参数和哈希码进行更新,过程如下:
13、步骤4.1:固定哈希码,运用反向传播算法对网络参数优化;
14、步骤4.2:固定网络参数,运用交替方向乘子法对哈希码进行优化;
15、步骤5:网络训练和哈希函数学习,过程如下:
16、步骤5.1:将数据集划分为查询集q与待查集p,并取待查集p的一部分作为训练集t;
17、步骤5.2:使用vgg网络提取图像的深度特征,使用词袋模型得到文本的表征向量;
18、步骤5.3:将训练集的图像深度特征,文本表征向量和标签信息输入;
19、步骤5.4:随机初始化网络参数;
20、步骤5.5:按步骤4从步骤4.1到4.2依次迭代优化直至收敛;
21、步骤5.6:根据步骤2.2构建的哈希函数,将最优的网络参数带入,得到哈希函数;
22、步骤6:图文检索与精度测试。
23、进一步,所述步骤6的过程如下:
24、步骤6.1:将查询集q与待查集p输入训练好的特征学习网络和哈希函数,分别得到查询集q中的图像文本的哈希码q+,q-,待查集p中的图像文本的哈希码p+,p-;
25、步骤6.2:图像检索文本,计算查询集q中每一张图像的哈希码q+与待查集p中所有文本的哈希码p-之间的汉明距离,并按照汉明距离从小到大进行排序作为检索结果;
26、步骤6.3:文本检索图像,计算查询集q中每一个文本的哈希码q-与待查集p中所有图像的哈希码p+之间的汉明距离,并按照汉明距离从小到大进行排序作为检索结果;
27、步骤6.4:比较查询图像或文本标签和检索文本或图像对应的标签,根据信息检索中的评价准则计算所有查询图像或文本的平均准确率,输出计算结果。
28、再进一步,所述步骤1.1的程如下:
29、步骤1.1.1:构建由三层全连接层组成的判别网络,relu作为每层激活函数;
30、步骤1.1.2:图像模态上,构建由三层全连接层组成的生成网络,relu作为每层激活函数;
31、步骤1.1.3:文本模态上,构建由三层全连接层组成的生成网络,relu作为每层激活函数;
32、步骤1.1.4:特征学习部分对抗学习,构建特征学习网络的对抗损失,即交叉熵损失。
33、更进一步,所述步骤1.2的过程如下:
34、步骤1.2.1:构建两层全连接层的判别网络,relu作为每层激活函数;
35、步骤1.2.2:图像模态上,构建单层全连接层的生成网络,tanh函数作为激活函数;
36、步骤1.2.3:文本模态上,构建单层全连接层的生成网络,tanh函数作为激活函数;
37、步骤1.2.4:哈希学习部分对抗学习,构建哈希学习网络的对抗损失,即交叉熵损失。
38、本发明的有益效果:一方面,为了对齐不同模态的特征,引入对抗学习来学习更好的特征。另一方面,为了在生成哈希码的过程中保持不同模态之间的原始语义相关性,提出了边界互信息来最小化汉明分布的重叠,这可以减少边界模糊性,并最大化汉明空间中不同类别样本之间的距离。为了减少信息冗余并生成更高质量的哈希码,在离散损失中添加了正交约束。对抗学习,边界互信息及正交约束的加入均有效地提高了检索精度。
技术特征:
1.一种基于边界互信息的跨模态哈希检索方法,其特征在于,所述方法包括以下步骤:
2.如权利要求1所述的一种基于边界互信息的跨模态哈希检索方法,其特征在于,所述步骤6的过程如下:
3.如权利要求1或2所述的一种基于边界互信息的跨模态哈希检索方法,其特征在于,所述步骤1.1的程如下:
4.如权利要求3所述的一种基于边界互信息的跨模态哈希检索方法,其特征在于,所述步骤1.2的过程如下:
技术总结
一种基于边界互信息的跨模态哈希检索方法,包括以下步骤:步骤1、搭建网络,构建特征学习网路和哈希学习网络,每个模态的特征学习网络和哈希学习网络均由多层全连接层组成的生成对抗网络构成;步骤2、构建哈希函数;步骤3、构建由交叉熵损失,排序余弦三元损失、边界互信息损失、带正交约束的离散损失构成的目标函数;步骤4、目标函数优化;步骤5、将数据集划分为查询集Q与待查集P,并取待查集P的一部分作为训练集T,将训练集数据和标签信息作为网络的输入,并初始化网络参数和哈希码,重复步骤4,迭代得到最优的网络参数和哈希码,根据步骤2获得最优的哈希函数;步骤6、跨模态检索与精度测试。本发明优化收敛,检索精度高。
技术研发人员:马青,蒋悦,白琮
受保护的技术使用者:浙江工业大学
技术研发日:
技术公布日:2024/2/25
- 还没有人留言评论。精彩留言会获得点赞!