一种基于3D提示信息的彩色和深度图像单目标跟踪算法
本发明属于深度学习、多模态目标跟踪、提示学习领域,涉及动态图卷积网络、k近邻聚类算法、单目标跟踪算法ostrack,具体涉及一种基于3d提示信息的彩色和深度图像单目标跟踪算法。
背景技术:
1、彩色图像的单目标跟踪任务作为计算机视觉领域的基础组成部分,在虚拟现实、增强现实和自动驾驶等多个领域中都有应用。近些年来,在该领域的发展主要得益于transformer结构以及多个大规模数据集的提出。基于transformer结构的单目标跟踪算法,如mixformer、neighbortrack、ostrack等,已经超越了基于卷积结构的算法。这些算法取得的成就不仅得益于transformer结构,同时也得益于多个大规模rgb跟踪数据集,如lasot、got-10k和tracknet。
2、虽然利用彩色图像的单目标跟踪算法取得了显著的成果,但是这些算法在面临一些挑战性场景,如极端光照变化、背景杂乱和运动模糊等,仍然会出现性能不够的问题。而多模态信息,如深度图,可以帮助算法更好地定位和跟踪目标。然而最近的彩色和深度图像跟踪算法,如dal、det和vipt等,往往将深度视为一种额外的视觉特征,这导致了整体依然依赖于外观线索和特征。仅依赖于外观信息,难以在复杂场景中进行精确跟踪。相比之下,3d几何信息提供了对物体形状和空间布局更全面的信息,为目标的具体位置提供了更准确的估计。
3、此外,考虑到彩色和深度图像跟踪数据集的规模远小于彩色图像数据集,直接在小规模数据集上进行训练,往往会破坏原有模型的泛化性。近年来,提示学习在下游任务的迁移上取得了显著成果,如adaptformer、vpt和convpass等。该方法为各种下游任务提供了一种有效的方式,使其能够更好地利用预训练模型,同时只需增加少量的可训练参数即可实现这一目标。
技术实现思路
1、本发明旨在提供一种基于3d提示信息的彩色和深度图像单目标跟踪算法,提升算法的在各场景中的泛化能力,同时提升算法在极端条件下的性能。
2、本发明所述的方法可部署在自动驾驶场景中的诸多设备上,为视觉定位导航提供目标信息。
3、本发明的技术方案:
4、一种基于3d提示信息的彩色和深度图像单目标跟踪算法,步骤如下:
5、步骤1:借助彩色图像传感器和深度图像传感器,分别获取彩色图像和深度图像;
6、步骤2:给定目标初始帧与当前帧的边界框;初始帧的边界框作为模板,并依据当前帧t时刻的边界框,确定下一帧t+1时刻的搜索区;
7、步骤3:根据模板和搜索区的边界框,获取对应区域的彩色图像以及点云信息;
8、(3.1)首先根据边界框的信息,将模板和搜索区的彩色图像和深度图像切割出来,这个过程包括切割、缩放和填充操作,并根据这些操作获取对应的矫正矩阵;
9、(3.2)根据相机内参以及矫正矩阵,将模板和搜索区对应的深度图像投影至相机坐标系,获取对应的点云;
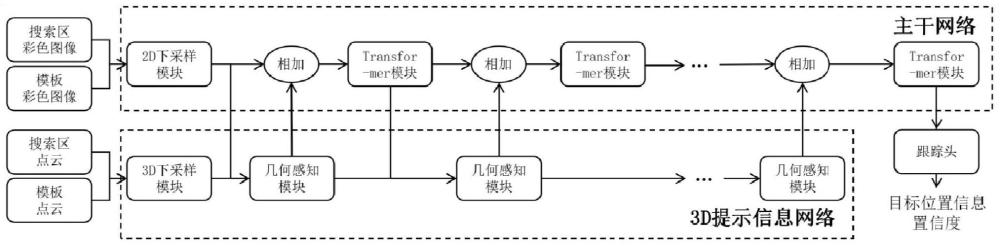
10、步骤4:输入连续视频流,经过transformer主干网络、3d提示信息网络以及跟踪头的计算后,获得t+1时刻的目标边界框;
11、transformer主干网络的输入是搜索区和模板的彩色图像,输出是经过16倍下采样后搜索区和模板对应的特征图;transformer主干网络的主要由l个transformer模块组成,每个transformer模块包含3个不同的线性层用于计算query、key和value,一个自注意力层以及一个多层感知器;若transformer主干网络中涉及到下采样的操作,下采样的倍率为m,则使用一个卷积核大小为m×m,步长为m的卷积层,来进行下采样的操作;
12、3d提示信息网络主要用于提取3d提示信息特征,并将该3d提示信息特征与transformer主干网络中对应特征相结合,从而增强transformer主干网络对于3d特征信息的理解能力;3d提示信息网络包含l个几何感知模块,每个几何感知模块有两个输入,一个是来自于transformer主干网络的2d特征,另一个是3d提示信息特征,该3d提示信息特征是来自于上一个几何感知模块的输出;该几何感知模块输出有且仅有一个3d提示信息特征;
13、3d提示信息网络中的下采样包括两类:对特征图的下采样与对点云的下采样;其中,对特征图的下采样直接采用与transformer主干网络相同的下采样方式;对点云的下采样,则是先对深度图中的有效点进行步长为m,窗口大小为m×m的最小池化,将下采样后的深度图重新投影到3d空间中;
14、几何感知模块的主要计算流程如下:
15、(4.1)几何感知模块的输入为来自于transformer主干网络中第l-1个transformer模块的输出以及来自于3d提示信息网络中第l-1个几何感知模块的输出它们分别经过一个线性层,得到通道数量为8的特征和
16、(4.2)对于包含2d信息的特征经过一个平滑操作获得2d提示特征
17、
18、其中,⊙代表逐元素相乘,α为可学习的参数,初始值为10.0,用于特征平滑;
19、(4.3)然后需要对含3d信息的特征进行信息提取;
20、(4.3.1)首先对这部分特征对应的点云p根据3d坐标信息进行knn聚类,其聚类结果为pknn;
21、(4.3.2)对于任意一点pi∈p,它与其k近邻内的点之间的关系为:
22、
23、其中,fi3d为点i在中的特征;之后将和fknn一起送入一个轻量化的动态图卷积神经网络中,得到3d空间下的特征
24、(4.3.3)之后,对进行空间注意力加权:
25、
26、其中,σ为sigmoid操作,linear为一个输出通道数量为1的线性层;
27、(4.4)几何感知模块的最终输出由对和进行逐元素相加得到;
28、
29、对于第l个transformer模块的输入,则是由和进行逐元素相加得到;
30、跟踪头的输入为搜索区经过transformer主干网络以及3d提示信息网络计算后的特征,输出为目标的边界框信息(如中心点坐标以及大小)以及目标的置信度;
31、步骤5:重复步骤2~步骤4直至视频结束。
32、本发明的有益效果:
33、(1)本发明采用3d提示信息的方式,赋予2d预训练模型对于3d环境的感知能力,提高了跟踪算法对于目标位置的计算精度,降低了干扰物对在跟踪过程中的影响。此外,降低了网络对于训练数据量的需求,同时提升了跟踪算法的精度。
34、(2)本发明提升了多模态单目标跟踪算法的鲁棒性与泛化性。有效提高了算法在面临挑战性场景时的性能,同时在面临多种不同的场景时,能够更为有效地区分目标与干扰物。
技术特征:
1.一种基于3d提示信息的彩色和深度图像单目标跟踪算法,其特征在于,步骤如下:
技术总结
本发明属于深度学习、多模态目标跟踪和提示学习领域,涉及动态图卷积网络、K近邻聚类算法和单目标跟踪算法OSTrack。本发明提出了一种基于3D提示信息的彩色和深度图像单目标跟踪算法,旨在提升算法在各种场景中的泛化能力,同时提高其在极端条件下的性能。该方法可部署在自动驾驶场景中的多种设备上,为视觉定位导航提供目标信息。本发明的优势在于:通过使用3D提示信息赋予2D预训练模型对3D环境的感知能力,提高了跟踪算法对目标位置的计算精度,并降低了干扰物在跟踪过程中的影响。同时,这种方法降低了网络对训练数据量的需求,并提升了跟踪算法的精度。
技术研发人员:卢湖川,李柏岑,王立君,王一帆
受保护的技术使用者:大连理工大学
技术研发日:
技术公布日:2024/3/12
- 还没有人留言评论。精彩留言会获得点赞!