基于联邦学习的模型分享方法、系统及相关设备
本技术实施例涉及互联网,尤其涉及基于联邦学习的模型分享方法、系统及相关设备。
背景技术:
1、联邦学习作为一种协作式的机器学习方法,有望减轻机器学习模型训练中对于数据和算力的庞大需求。联邦学习通过分布在边缘设备上的大量数据和未充分利用的计算资源,满足机器学习模型训练的需要,同时规避了对于原始数据的访问。用户可以通过参与联邦学习模型的训练过程,在不泄露隐私数据的前提下,获取和使用最终训练有素的联邦学习全局模型,从而降低用户获取机器学习的门槛并产生显著的社会效益。
2、然而,参与模型训练会给参与方带来相关的参与成本(如花费计算资源、通信资源或数据标记成本等),故具有个人理性约束的自利用户,可能会犹豫是否参与联邦学习并贡献其相关资源。此情况下,若只有少量的用户参与联邦学习模型的训练过程,会使得联邦学习难以实现发挥协作的优势,降低整体的社会效益(如模型预测时的准确度和/或用时等价值)。因此,有必要激励用户做出参与联邦学习的决策。
技术实现思路
1、本技术实施例提供了基于联邦学习的模型分享方法、系统及相关设备,用于增强联邦学习模型的预测效果和受众量。
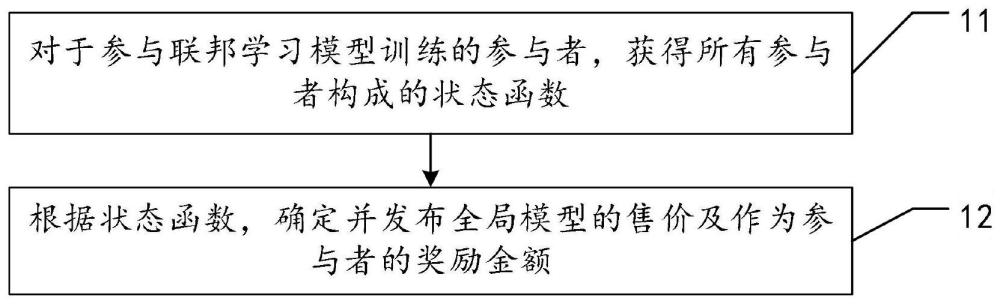
2、本技术实施例第一方面提供一种基于联邦学习的模型分享方法,包括:
3、对于参与联邦学习模型训练的参与者,获得所有所述参与者构成的状态函数;所述状态函数用于反映,所述参与者的数量对联邦学习训练得到的全局模型相应产生的效用;
4、根据所述状态函数,确定并发布所述全局模型的售价及作为所述参与者的奖励金额,以引导用户按所述售价购得所述全局模型的使用权或成为所述参与者。
5、可选地,所述获得当前所有所述参与者构成的状态函数,包括:
6、根据所述参与者的数量和所述训练过程得到的目标参数,计算所述全局模型的泛化误差;
7、基于所述泛化误差,量化所述全局模型对于所述参与者而言的效用函数,并通过所述参与者的数量和所述效用函数构建所述状态函数。
8、可选地,所述根据所述参与者的数量和所述训练过程得到的目标参数,计算所述全局模型的泛化误差,包括:
9、对当前所有所述参与者进行分类,以得到按不同用户类型划归的多个用户类型集合;
10、基于各所述用户类型集合下的参与者数量和所述目标参数间的比例关系,计算所述全局模型在各类参与者贡献下的泛化误差。
11、可选地,所述对当前所有所述参与者进行分类,包括:
12、依据用户终端投用到所述训练过程的数据集大小,对当前所有所述参与者进行分类,以得到多个用户类型集合。
13、可选地,所述确定并发布所述全局模型的售价及作为所述参与者的奖励金额,包括:
14、基于均为目标类型的所述参与者数量和购买者数量,计算所述全局模型所达到的效益;
15、根据所述效益推算所述全局模型的售价和作为所述参与者的奖励金额,其中,所述售价和所述奖励金额因所述效用函数取值的不同而不同。
16、可选地,因购买所述全局模型产生的总收入大于等于对所有所述参与者分配的所述奖励金额;所述奖励金额随所述参与者数量的增加而增加。
17、可选地,所述方法还包括:
18、向决定成为所述参与者的各用户终端发送初始模型参数,以使各所述用户终端通过本地数据集对所述初始模型参数进行本地迭代调整,直至得到满足预设损失条件的一轮初始模型参数;
19、接收并聚合各所述用户终端上传的所述一轮初始模型参数,得到更新的初始模型参数,并返回所述向决定成为所述参与者的各用户终端发送初始模型参数的步骤,直至聚合后的初始模型参数满足收敛条件时停止训练,得到所述全局模型。
20、可选地,根据所述状态函数,确定并发布所述全局模型的售价及作为所述参与者的奖励金额之后,所述方法还包括:
21、对于预就所述全局模型做出不同决策的各类用户,确定并发布所述各类用户因所述决策所具有的决策收益,以供用户决定是否购买所述全局模型的使用权或成为所述参与者;
22、其中,所述决策为参与模型训练时,所述决策收益根据所述效用函数、参与成本和所述奖励金额确定;所述决策为购买所述全局模型时,所述决策收益(或称个人收益)根据所述效用函数和所述售价确定。
23、可见,本技术实施例的主要目的是提供一种基于联邦学习的模型交易和分享(mts)框架,通过引入机器学习模型交易来提高模型性能和可获取性,并在对于联邦学习模型训练特性及异构用户决策博弈(网络效应)理论分析的基础上,设计社会高效semts机制,从而激励异构用户最大化社会效益,即最大化全体用户收益。本技术实施例的主要特点是在原始联邦学习框架的基础上,允许异构用户通过额外的直接购买方式获取训练后的联邦学习全局模型,以增强社会福利。同时依托于semts机制,在完全和不完全信息场景下均可激励用户跨越负向网络效应,利用用户参与的正向网络效应引导个人理性约束的异构用户达到社会高效状态。可选地,semts机制仅依赖于mts框架下模型购买者支付的费用以及(部分)参与者支付的费用(即负参与奖励),而无需额外的外部激励。
24、本技术第一方面所述的方法在具体实施时可采用本技术第二方面所述的内容实现。
25、本技术实施例第二方面提供一种基于联邦学习的模型分享系统,包括:获取单元、处理单元;
26、对于参与联邦学习模型训练的参与者,所述获取单元用于获得所有所述参与者构成的状态函数;所述状态函数用于反映,所述参与者的数量对联邦学习训练得到的全局模型相应产生的效用;
27、所述处理单元用于根据所述状态函数,确定并发布所述全局模型的售价及作为所述参与者的奖励金额,以引导用户按所述售价购得所述全局模型的使用权或成为所述参与者。
28、本技术实施例第三方面提供一种电子设备,包括:
29、中央处理器,存储器以及输入输出接口;
30、所述存储器为短暂存储存储器或持久存储存储器;
31、所述中央处理器配置为与所述存储器通信,并执行所述存储器中的指令操作以执行本技术实施例第一方面或第一方面的任一具体实现方式所描述的方法。
32、本技术实施例第四方面提供一种计算机可读存储介质,包括指令,当所述指令在计算机上运行时,使得计算机执行如本技术实施例第一方面或第一方面的任一具体实现方式所描述的方法。
33、本技术实施例第五方面提供一种包含指令或计算机程序的计算机程序产品,当所述计算机程序产品在计算机上运行时,使得计算机执行如本技术实施例第一方面或第一方面的任一具体实现方式所描述的方法。
34、从以上技术方案可以看出,本技术实施例至少具有以下优点:
35、本技术实施例考量了参与者的数量对全局模型效用的影响,使得对参与者奖励金额的设立具备可靠性或说服力,有助于激励更多的用户参与到联邦学习过程中,从而提高全局模型的预测性能。此外,开放购买渠道,可降低非参与者获取全局模型的门槛,同时,借助购买者支付的费用可反过来激励更多参与者加入模型训练过程,提高联邦学习模型的性能,形成良性循环。
- 还没有人留言评论。精彩留言会获得点赞!