一种金融风险预测方法及系统与流程
本发明属于机器学习,具体涉及一种金融风险预测方法及系统。
背景技术:
1、传统的金融监管方法是大多是通过人工线下调查,随着互联网的发展,许多公司将其基本数据公布在互联网,以及部分重要数据上传至金融监管机构,使得金融监管人员通过分析其数据即可完成调查,对金融监管以及企业本身都方便了很多。并且随着经济发展愈发迅速,越来越多的企业在市面上涌入,导致金融监管工作量急剧上升,而人工监管成本高、效率低。金融监管人员迫切希望减轻工作压力,同时企业人员希望快速了解本公司的风险状况。
2、为了解决人工监管存在的问题,现有技术常常采用机器学习的方式进行金融风险的预测,从而可以实现监管作用。而现有机器学习常常采用梯度下降法、粒子群算法、遗传算法等等优化算法进行神经网络的优化,虽然能够实现数据的自动识别,但是由于算法缺陷,往往会在优化过程中陷入局部最优当中,从而导致神经网络参数的优化效果较差。
技术实现思路
1、本发明提供一种金融风险预测方法及系统,用以解决现有技术在机器学习过程中,容易陷入局部最优以及参数优化效果较差问题。
2、第一方面,本发明提供一种金融风险预测方法,包括:
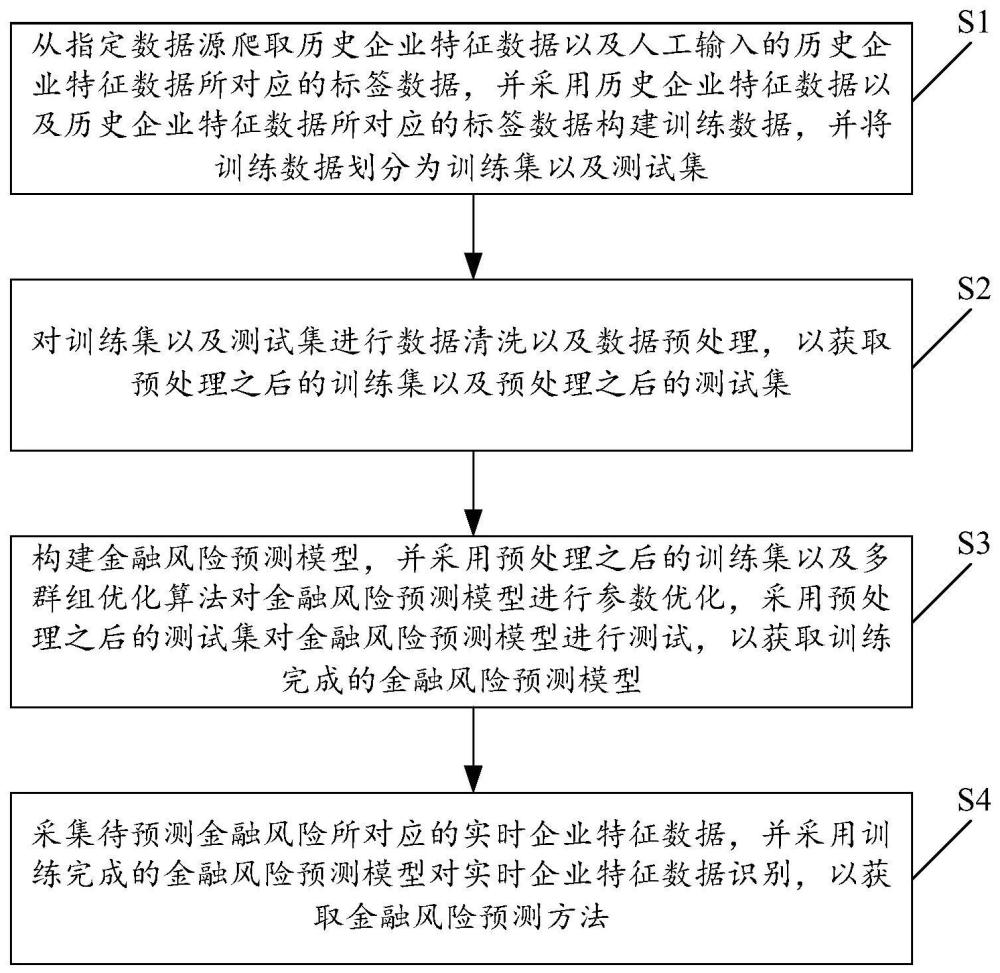
3、从指定数据源爬取历史企业特征数据以及人工输入的历史企业特征数据所对应的标签数据,并采用历史企业特征数据以及历史企业特征数据所对应的标签数据构建训练数据,并将训练数据划分为训练集以及测试集;
4、对训练集以及测试集进行数据清洗以及数据预处理,以获取预处理之后的训练集以及预处理之后的测试集;
5、构建金融风险预测模型,并采用预处理之后的训练集以及多群组优化算法对金融风险预测模型进行参数优化,采用预处理之后的测试集对金融风险预测模型进行测试,以获取训练完成的金融风险预测模型;
6、采集待预测金融风险所对应的实时企业特征数据,并采用训练完成的金融风险预测模型对实时企业特征数据识别,以获取金融风险预测方法。
7、进一步地,对训练集以及测试集进行数据清洗以及数据预处理,以获取预处理之后的训练集以及预处理之后的测试集,包括:
8、获取训练集中存在缺失值或者异常值的历史企业特征数据,得到第一待清洗数据;
9、判断第一待清洗数据的数量是否超过预设的数量阈值,若是,则将缺失值或者异常值更换为同类型数据的平均值获取中位数,得到第一清洗数据,否则直接将第一待清洗数据去除,得到第一清洗数据;
10、获取测试集中存在缺失值或者异常值的历史企业特征数据,得到第二待清洗数据;
11、判断第二待清洗数据的数量是否超过预设的数量阈值,若是,则将缺失值或者异常值更换为同类型数据的平均值获取中位数,得到第二清洗数据,否则直接将第二待清洗数据去除,得到第二清洗数据;
12、对第一清洗数据以及第二清洗数据进行归一化处理,得到预处理之后的训练集以及预处理之后的测试集。
13、进一步地,构建金融风险预测模型,并采用预处理之后的训练集以及多群组优化算法对金融风险预测模型进行参数优化,包括:
14、构建神经网络模型,并将构建的神经网络模型作为金融风险预测模型;
15、初始化金融风险预测模型所对应的种群规模为p、最小并行训练组数为q1以及最大并行训练组数为q2,且种群规模p为训练组数q2!的整数倍;
16、以所述种群规模p为基础,初始化金融风险预测模型的模型参数,获取包括p个训练个体的训练种群,每个训练个体包括金融风险预测模型的所有模型参数;
17、以最小并行训练组数q1基础,初始化当前训练组数qt的值为q1;采用预处理之后的训练集,获取每个训练个体所对应的适应度值;
18、将训练个体按照适应度值从大到小的顺序排列,并以当前训练组数qt基础,取出前qt个训练个体分别作为qt个训练组的局部领导者,取出适应度值最大的训练个体作为全局领导者,将剩余的训练个体均匀分配至qt个训练组中;
19、针对每个训练组,采用局部领导者引导策略、第一自适应优化策略以及贪心优化策略对训练组中的每个训练个体进行局部搜索,得到局部搜索之后的训练组;
20、针对每个局部搜索之后的训练组,采用概率优化策略、全局领导者引导策略、第二自适应优化策略以及贪心优化策略对训练组中的每个训练个体进行全局搜索,得到全局搜索之后的训练组;
21、以全局搜索之后的训练组为基础,重新选取全局领导者以及每个训练组的局部领导者;
22、判断每个训练组的局部领导者是否在l1次训练过程中未发生变化,若是,则采用概率扰动策略以及变异策略对局部领导者进行更新,并进入全局领导者的判断步骤,否则直接进入全局领导者的判断步骤;
23、判断全局领导者是否在l2次训练过程中未发生变化,若是,则进入当前训练组数的判断步骤,否则进入迭代结束条件的判断步骤;
24、判断当前训练组数是否大于最大并行训练组数为q2,若是,则保持每个训练组的局部领导者不变,将其他训练个体重新随机均匀分配至每个训练组中,并进入迭代结束条件的判断步骤,否则令当前训练组数qt的计数值加一,并前qt个训练个体分别作为qt个训练组的局部领导者,取出适应度值最大的训练个体作为全局领导者,将剩余的训练个体均匀分配至qt个训练组中,进入迭代结束条件的判断步骤;
25、判断是否满足迭代结束条件,若是,则输出全局领导者作为金融风险预测模型的最终模型参数,得到参数优化之后的金融风险预测模型,否则返回局部搜索的步骤。
26、进一步地,以所述种群规模p为基础,初始化金融风险预测模型的模型参数,获取包括p个训练个体的训练种群,包括:
27、生成第i个训练个体的第d维模型参数为:
28、xid=xmind+r(0,1)*(xmaxd-xmind)
29、其中,xid表示第i个训练个体的第d维模型参数,d=1,2,…,d,d表示模型参数总数,r(0,1)表示[0,1]上均匀分布的随机数,xmaxd表示第d维模型参数的最大值,xmind表示第d维模型参数的最小值;
30、重复生成p个训练个体的模型参数,得到训练种群。
31、进一步地,采用预处理之后的训练集,获取每个训练个体所对应的适应度值,包括:
32、将第i个训练个体应用至金融风险预测模型中,并从预处理之后的训练集取出n个历史企业特征数据作为金融风险预测模型的输入,获取金融风险预测模型的实际输出为yi,nm;
33、以历史企业特征数据所对应的标签数据作为期望输出并根据实际输出yi,nm以及期望输出获取第i个训练个体的适应度值为:
34、
35、其中,fi表示第i个训练个体的适应度值,i=1,2,…,p;yi,nm表示第i个训练个体应用至金融风险预测模型中,且第n个历史企业特征数据作为金融风险预测模型的输入,得到的金融风险预测模型的第m个输出神经元的输出;n=1,2,…,n,m=1,2,…,m,m表示金融风险预测模型的输出神经元总数,即风险类别总数;表示第n个历史企业特征数据所对应的期望输出;α表示大于0且小于1的常数项。
36、进一步地,针对每个训练组,采用局部领导者引导策略、第一自适应优化策略以及贪心优化策略对训练组中的每个训练个体进行局部搜索,得到局部搜索之后的训练组,包括:
37、针对每个训练组中的每个训练个体,为训练个体随机生成一个新个体,并判断新个体的适应度值是否大于原有训练个体的适应度值,若是,则采用新个体替换对应的原有训练个体,得到初始搜索之后的训练个体,否则保留原有训练个体,得到初始搜索之后的训练个体;
38、针对初始搜索之后的训练个体,为初始搜索之后的训练个体随机生成一个[0,1]之间的第一随机数,并判断第一随机数是否大于局部更新概率,若是,则采用局部领导者引导策略、第一自适应优化策略以及贪心优化策略对初始搜索之后的训练个体进行更新,否则不对初始搜索之后的训练个体进行更新;
39、遍历所有训练个体,获取局部搜索之后的训练组;
40、其中,采用局部领导者引导策略以及贪心优化策略对初始搜索之后的训练个体进行更新包括:
41、获取第一更新值为:
42、
43、式中,表示第t次训练过程中第q个训练组中第j个训练个体的第d维模型参数,表示对应的第一更新值;q=1,2,…,qt,表示第q个训练组对应的局部领导者的第d维模型参数,表示第q个训练组中除之外的随机个体的第d维模型参数,表示第一自适应优化步长,且tmax表示最大训练次数,λ表示(-0.1,0.1)之间的随机数;
44、判断第一更新值的适应度值是否增大,若是,则接受该更新,否则拒绝该更新。
45、进一步地,针对每个局部搜索之后的训练组,采用概率优化策略、全局领导者引导策略、第二自适应优化策略以及贪心优化策略对训练组中的每个训练个体进行全局搜索,得到全局搜索之后的训练组,包括:
46、获取全局更新概率为:
47、
48、式中,pri表示第i个训练个体对应的全局更新概率,fi表示第i个训练个体的适应度值,fmax表示全局领导者的适应度值;
49、针对局部搜索之后的训练个体,为局部搜索之后的训练个体随机生成一个[0,1]之间的第二随机数,并判断第二随机数是否小于全局更新概率,若是,则采用全局领导者引导策略、第二自适应优化策略以及贪心优化策略对局部搜索之后的训练个体进行更新,否则不对局部搜索之后的训练个体进行更新;
50、遍历所有训练个体,获取全局搜索之后的训练组;
51、其中,采用全局领导者引导策略、第二自适应优化策略以及贪心优化策略对局部搜索之后的训练个体进行更新,包括:
52、获取第二更新值为:
53、
54、式中,表示第i个训练个体的第d维模型参数,表示对应的第二更新值,表示全局领导者的第d维模型参数,表示除之外的随机个体,r(0,1)表示(0,1)之间的随机数,r(-1,1)表示(-1,1)之间的随机数,表示第二自适应优化步长,且当第i个训练个体的适应度值fit大于所有训练个体的平均适应度值时,step2t取值预设最大值否则取值为表示对应的预设最小值,fave表示所有训练个体的平均适应度值,fmin表示所有训练个体的最小适应度值;
55、判断第二更新值的适应度值是否增大,若是,则接受该更新,否则拒绝该更新。
56、进一步地,采用概率扰动策略以及变异策略对局部领导者进行更新,包括:
57、针对全局搜索之后的训练个体,为全局搜索之后的训练个体随机生成一个[0,1]之间的第三随机数,并判断第三随机数是否小于全局更新概率,若是,则对训练个体进行第一扰动更新,否则对训练个体进行第二扰动更新;
58、遍历所有全局搜索之后的训练个体,得到扰动更新之后的训练个体;
59、针对扰动更新之后的训练个体,获取训练个体的变异更新值,并采用贪心优化策略对变异更新值进行保留选择;
60、其中,第一扰动更新为:
61、
62、式中,表示全局搜索之后,第i个训练个体的第d维模型参数的更新值;
63、第二扰动更新为:
64、
65、式中,表示全局搜索之后的第i个训练个体的第d维模型参数,r1表示[0,1]上均匀分布的第四随机数,r2表示[0,1]上均匀分布的第五随机数,表示全局搜索之后的全局领导者的第d维模型参数,表示全局搜索之后除第i个训练个体之外的随机个体的第d维模型参数;
66、获取训练个体的变异更新值为:式中,β1表示随着训练次数增加,从2到0线性递减的缩放因子;π表示圆周率;β2表示[0,1]上均匀分布的随机数。
67、进一步地,采用预处理之后的测试集对金融风险预测模型进行测试,以获取训练完成的金融风险预测模型,包括:
68、以预处理之后的测试集作为金融风险预测模型的训练样本,获取金融风险预测模型的准确率、精准度以及召回率;
69、当金融风险预测模型的准确率、精准度以及召回率均满足预设要求时,将参数优化之后的金融风险预测模型作为训练完成的金融风险预测模型;
70、当金融风险预测模型的准确率、精准度以及召回率任一项不满足预设要求时,则对金融风险预测模型重新进行训练,直至当金融风险预测模型的准确率、精准度以及召回率均满足预设要求时,将参数优化之后的金融风险预测模型作为训练完成的金融风险预测模型。
71、第二方面,本发明提供一种金融风险预测系统,包括数据获取模块、数据清洗模块、模型训练模块以及风险预测模块;
72、所述数据获取模块,用于从指定数据源爬取历史企业特征数据以及人工输入的历史企业特征数据所对应的标签数据,并采用历史企业特征数据以及历史企业特征数据所对应的标签数据构建训练数据,并将训练数据划分为训练集以及测试集;
73、所述数据清洗模块,用于对训练集以及测试集进行数据清洗以及数据预处理,以获取预处理之后的训练集以及预处理之后的测试集;
74、所述模型训练模块,用于构建金融风险预测模型,并采用预处理之后的训练集以及多群组优化算法对金融风险预测模型进行参数优化,采用预处理之后的测试集对金融风险预测模型进行测试,以获取训练完成的金融风险预测模型;
75、所述风险预测模块,用于采集待预测金融风险所对应的实时企业特征数据,并采用训练完成的金融风险预测模型对实时企业特征数据识别,以获取金融风险预测方法。
76、本发明提供的一种金融风险预测方法及系统,通过引入机器学习对金融风险进行监管,能够解决人工监管存在的费时费力、成本高的问题,并且针对现有机器学习算法中存在的问题,提出了一种多群组优化算法,不仅能够有效地提高收敛速度以及收敛精度,还能够有效地增加全局搜索的能力,从而实现更好的参数优化效果,解决了现有优化算法中存在的缺陷。
- 还没有人留言评论。精彩留言会获得点赞!