一种词标注的嵌套实体识别方法、装置、设备及介质与流程
本发明涉及知识库构建,特别涉及一种词标注的嵌套实体识别方法、装置、设备及介质。
背景技术:
1、随着互联网快速发展,数据呈次数级增长。nested ner(nested named entityrecognition,命名实体识别)旨在从文本中识别出具有实际含义的文本片段,这个片段能够表达一定的信息量,比如“复旦大学是一所综合性研究型大学。”中的实体是“复旦大学”。命名实体识别因有助于提高下游任务的性能引起了研究人员的极大关注。以前的工作主要集中在平面命名实体识别,他们将平面命名实体识别视为一个序列标注任务,并假设每个标签只有一个标签,因此无法识别具有嵌套结构的实体。最近,为从文本中识别具有嵌套结构的实体,人们提出了各种方法,可以大致分为五类:(1)layered-based方法;(2)hypergraph-based方法;(3)transition-based方法;(4)seq2seq(sequence to sequence)方法;(5)region-based方法,region-based方法主要有两类策略,第一种首先从文本中定位候选实体跨度,然后将候选实体跨度分类到预定义的类别;第二种是首先列举了实体类别,然后定位候选实体跨度。上述的方法存在以下缺点,layered-based方法由于序列标注方法在表示实体的嵌套结构方面的根本限制,该方法在错误传播和识别不准确的方面存在缺点;hypergraph-based方法在推理过程中受到虚假结构和结构模糊性问题的影响;transition-based方法需要大量的人力来定义过渡动作,并沿着句子的词逐渐产生过渡,这可能会导致过渡动作状态的识别不准确;seq2seq方法可能会受到解码效率问题和暴露偏差的影响;region-based方法的第一种方法受到最大跨度长度的限制,并且由于其枚举性质,导致了相当大的计算成本,第二种方法因分别独立检测实体跨度和类别,这导致了错误的传播。此外,这些方法没有考虑实体跨度和实体类别之间的关联性,这会导致实体边界识别不准。
2、由上可见,如何避免受到虚假结构、结构模糊性问题、解码效率问题以及暴露偏差的影响,提高嵌套实体识别的效率和实体边界识别的准确性,降低计算成本是本领域有待解决的问题。
技术实现思路
1、有鉴于此,本发明的目的在于提供一种词标注的嵌套实体识别方法、装置、设备及介质,能够避免受到虚假结构、结构模糊性问题、解码效率问题以及暴露偏差的影响,提高嵌套实体识别的效率和实体边界识别的准确性,降低计算成本。其具体方案如下:
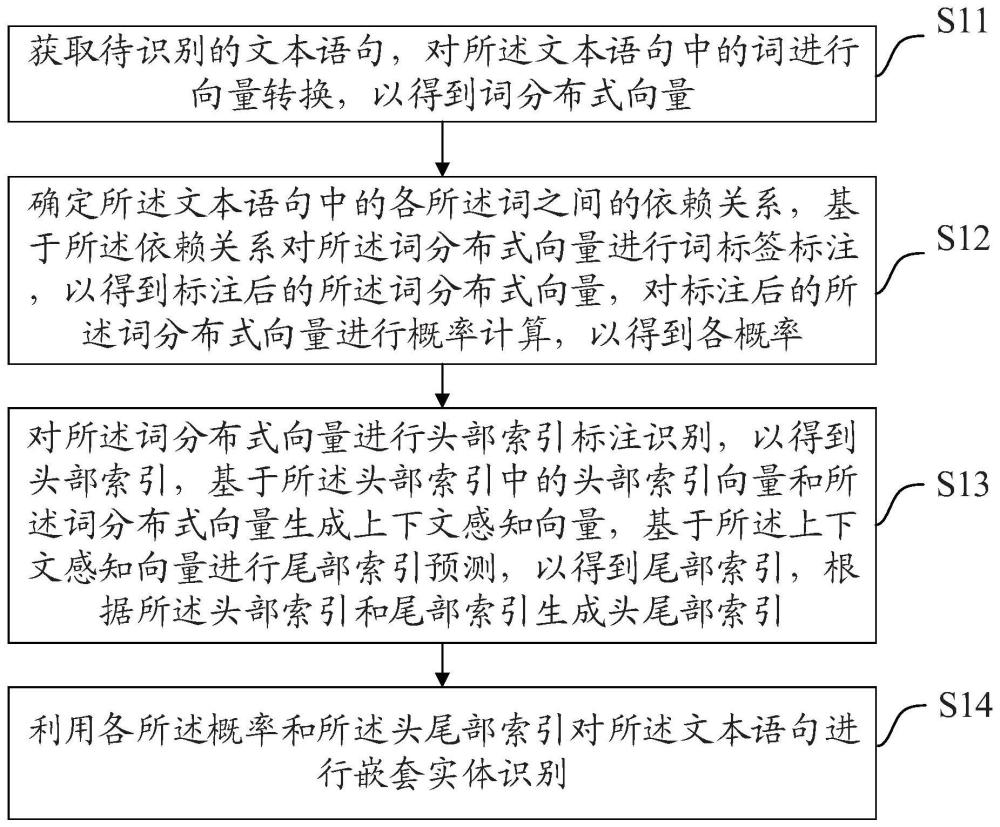
2、第一方面,本技术公开了一种词标注的嵌套实体识别方法,应用于预设的多任务学习框架,包括:
3、获取待识别的文本语句,对所述文本语句中的词进行向量转换,以得到词分布式向量;
4、确定所述文本语句中的各所述词之间的依赖关系,基于所述依赖关系对所述词分布式向量进行词标签标注,以得到标注后的所述词分布式向量,对标注后的所述词分布式向量进行概率计算,以得到各概率;
5、对所述词分布式向量进行头部索引标注识别,以得到头部索引,基于所述头部索引中的头部索引向量和所述词分布式向量生成上下文感知向量,基于所述上下文感知向量进行尾部索引预测,以得到尾部索引,根据所述头部索引和尾部索引生成头尾部索引;
6、利用各所述概率和所述头尾部索引对所述文本语句进行嵌套实体识别。
7、可选的,所述获取待识别的文本语句,对所述文本语句中的词进行向量转换,以得到词分布式向量,包括:
8、利用本地的编码器获取待识别的所述文本语句,并对所述文本语句中的所述词分别进行字符嵌入向量转换、词嵌入向量转换以及语境词嵌入向量转换,以得到字符嵌入分布式向量、词嵌入分布式向量以及语境词嵌入分布式向量;
9、基于所述字符嵌入分布式向量、所述词嵌入分布式向量以及所述语境词嵌入分布式向量生成所述词分布式向量。
10、可选的,所述对所述文本语句中的所述词分别进行字符嵌入向量转换、词嵌入向量转换以及语境词嵌入向量转换,以得到字符嵌入分布式向量、词嵌入分布式向量以及语境词嵌入分布式向量,包括:
11、采用字符嵌入技术,并利用bilstm模型对所述文本语句中的所述词进行字符嵌入向量转换,以得到所述字符嵌入分布式向量;
12、采用词嵌入技术,并利用glove模型对所述文本语句中的所述词进行词嵌入向量转换,以得到所述词嵌入分布式向量;
13、采用语境词嵌入技术,并利用bert模型对所述文本语句中的所述词进行语境词嵌入向量转换,以得到所述语境词嵌入分布式向量。
14、可选的,所述确定所述文本语句中的各所述词之间的依赖关系,基于所述依赖关系对所述词分布式向量进行词标签标注,包括:
15、利用本地的词元依存标注器并采用条件层归一化方法确定所述文本语句中的各所述词之间的依赖关系;
16、采用序列标注的方法并基于所述依赖关系对所述词分布式向量进行词标签标注。
17、可选的,所述对所述词分布式向量进行头部索引标注识别,以得到头部索引,包括:
18、利用本地的词元级联标注器中的头部标注器对所述词分布式向量进行头部索引标注识别,以得到所述头部索引;
19、相应的,所述基于所述上下文感知向量进行尾部索引预测,以得到尾部索引,包括:
20、利用所述词元级联标注器中的尾部标注器,并基于所述上下文感知向量进行尾部索引预测,以得到所述尾部索引。
21、可选的,所述基于所述头部索引中的头部索引向量和所述词分布式向量生成上下文感知向量,包括:
22、从所述头部索引中的确定头部索引向量,并从所述词分布式向量中筛选出部分词分布式向量;
23、采用多头注意力机制将所述头部索引向量和所述部分词分布式向量进行拼接,以生成所述上下文感知向量。
24、可选的,所述利用各所述概率和所述头尾部索引对所述文本语句进行嵌套实体识别,包括:
25、利用各概率从头尾部索引中筛选目标头尾部索引;
26、采用最近邻匹配算法,并基于所述目标头尾部索引完成对文本语句的嵌套实体识别。
27、第二方面,本技术公开了一种词标注的嵌套实体识别装置,应用于预设的多任务学习框架,包括:
28、向量转换模块,用于获取待识别的文本语句,对所述文本语句中的词进行向量转换,以得到词分布式向量;
29、词标签标注模块,用于确定所述文本语句中的各所述词之间的依赖关系,基于所述依赖关系对所述词分布式向量进行词标签标注,以得到标注后的所述词分布式向量,对标注后的所述词分布式向量进行概率计算,以得到各概率;
30、索引识别预测模块,用于对所述词分布式向量进行头部索引标注识别,以得到头部索引,基于所述头部索引中的头部索引向量和所述词分布式向量生成上下文感知向量,基于所述上下文感知向量进行尾部索引预测,以得到尾部索引,根据所述头部索引和尾部索引生成头尾部索引;
31、嵌套实体识别模块,用于利用各所述概率和所述头尾部索引对所述文本语句进行嵌套实体识别。
32、第三方面,本技术公开了一种电子设备,包括:
33、存储器,用于保存计算机程序;
34、处理器,用于执行所述计算机程序,以实现前述的词标注的嵌套实体识别方法。
35、第四方面,本技术公开了一种计算机存储介质,用于保存计算机程序;其中,所述计算机程序被处理器执行时实现前述公开的词标注的嵌套实体识别方法的步骤。
36、可见,本技术提供了一种词标注的嵌套实体识别方法,包括获取待识别的文本语句,对所述文本语句中的词进行向量转换,以得到词分布式向量;确定所述文本语句中的各所述词之间的依赖关系,基于所述依赖关系对所述词分布式向量进行词标签标注,以得到标注后的所述词分布式向量,对标注后的所述词分布式向量进行概率计算,以得到各概率;对所述词分布式向量进行头部索引标注识别,以得到头部索引,基于所述头部索引中的头部索引向量和所述词分布式向量生成上下文感知向量,基于所述上下文感知向量进行尾部索引预测,以得到尾部索引,根据所述头部索引和尾部索引生成头尾部索引;利用各所述概率和所述头尾部索引对所述文本语句进行嵌套实体识别。本技术应用于预设的多任务学习框架,将文本语句中的词向量转换为词分布式向量,然后确定词之间的依赖关系,以便对词分布式向量进行词标签标注,以对标注后的词分布式向量进行概率计算,以得到各概率,并对词分布式向量进行头部索引标注识别,得到头部索引,从而预测出尾部索引,避免受到虚假结构、结构模糊性问题、解码效率问题以及暴露偏差的影响,最后利用概率和头尾部索引对文本语句进行嵌套实体识别,本技术考虑实体跨度和实体类别之间的关联性,将实体识别作为先验知识,指导模型预测实体的边界,从而提高实体边界识别的准确性,并且本技术不依赖于任何外部知识资源或复杂的人工注释,因此可以很容易地适应特定领域的数据,提高嵌套实体识别的效率,降低计算成本。
- 还没有人留言评论。精彩留言会获得点赞!