一种识别岩溶管道中暂时存储模型参数的方法
本发明属于水文地质参数反演,具体涉及一种识别岩溶管道中暂时存储模型参数的方法。
背景技术:
1、岩溶含水层是全球范围内一种重要的供给水源,为世界上1/4的人口提供水资源。岩溶含水层中往往发育大型岩溶管道,由于岩溶管道极强的导水能力,污染物通过岩溶管道快速运移扩散到其他地方,容易造成该地区地下水大面积污染。定量示踪试验是一种研究岩溶管道溶质运移过程的有力工具,通过穿透曲线的定量解译能了解岩溶管道的内部空间结构特征(管道截面积、管道体积)、水动力特征(地下水流速)和溶质运移特征(弥散度、滞后和衰减系数等)。野外示踪试验的穿透曲线常包含明显拖尾,无法通过传统对流弥散方程进行解译。岩溶管道内暂时存储区的存在是导致穿透曲线拖尾的主要因素之一,很多研究采用暂时存储模型(transient storage model,tsm)模拟和解译穿透曲线拖尾现象,在otis-p程序中实现这一过程。
2、尽管如此,对岩溶管道中暂时存储模型参数的不确定性的研究很少。尤其是,当示踪参数和/或管道长度未知需要校正时,模型参数的不确定性如何变化仍然未知。otis-p程序,虽然能模拟穿透曲线,但不能在校正模型参数之外同时校正其他参数,而且不能充分评价模型参数的不确定性。传统的方法,如梯度型或启发式搜索方法,也难以充分量化不确定性,并可能产生不存在或非唯一的解决方案。
3、为了评价模型不确定性,人们提出了:全贝叶斯方法,如马尔可夫链蒙特卡罗(mcmc)算法。但在解决高维反问题时,采用该方法的计算成本可能很高。集合数据同化(eda)方法,如集合平滑(es)和集合卡尔曼滤波(enkf),在解决地下水水文逆问题方面越来越受欢迎。与mcmc方法相比,eda方法的计算效率更高,同时能处理参数不确定性。此外,多数据同化集合平滑优化方法(es-mda)也越来越受欢迎,并有效地应用于污染源识别和含水层性质的估计。然而,值得注意的是,对于非高斯分布的参数,es-mda的更新效果不能达到最好。
技术实现思路
1、本发明公开了一种识别岩溶管道中暂时存储模型参数的方法,该方法的基础是将正态分布转换(normal-score transform)纳入es-mda(即normal-score es-mda(ns-es-mda)),以解决先验和后验参数的潜在非高斯性,并首次将ns-es-mda用于识别岩溶管道暂态存储模型参数。es-mda可以同时反演模型参数、其他示踪剂参数和管道长度,计算成本较低。同时,它可以生成后验参数集合,以充分量化不确定性。此外,ns-es-mda确保联合参数向量服从高斯边缘分布,从而采用es-mda反演参数时能获得最优效果。本发明理论可行、实践方便、耗时短,能够在示踪参数和管道长度未知的条件下准确识别模型参数,且模型参数的不确定性较低。
2、为实现上述目的,本发明的技术方案是:
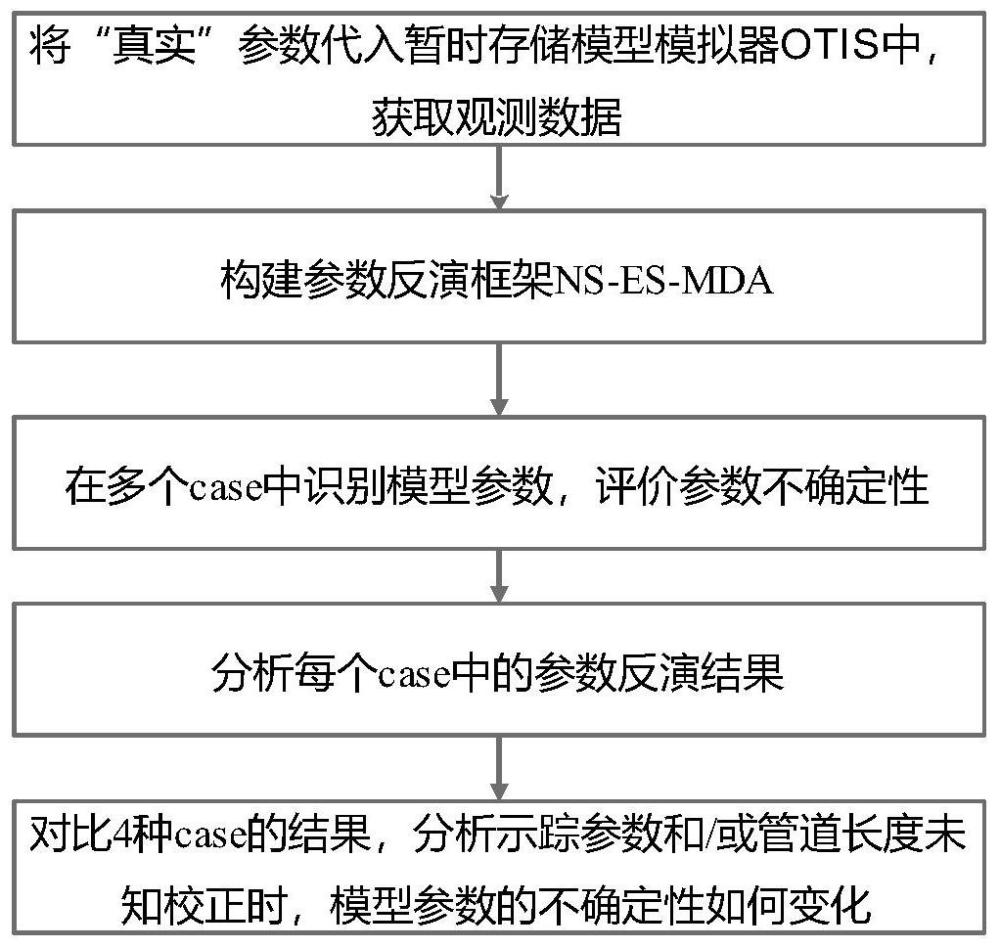
3、一种识别岩溶管道中暂时存储模型参数的方法,包括如下步骤:
4、步骤一:假设模型参数已知,将其称为“真实”模型参数,将“真实”模型参数代入暂时存储模型tsm模拟器即otis软件中,模拟生成穿透曲线,以穿透曲线的数据作为观测数据;
5、步骤二:构建参数反演框架ns-es-mda;根据观测数据,反演获得模型参数,并评价模型参数的不确定性;
6、步骤三:在多种case中识别模型参数,评价参数不确定性;
7、步骤四:分析每个case中的参数反演结果;
8、步骤五:对比多种case的结果,分析示踪参数和/或管道长度从已知变为未知时,模型参数的不确定性如何变化。
9、优选的,所述的步骤一包括:
10、(1)“真实”模型参数源于前期基于室内管道的研究,采用“真实”模型参数在otis软件中模拟生成穿透曲线时设置的管道长度l为104.5m,释放浓度ci为20g/l,释放初始时间ti为0.0028h,释放持续时间td为0.0056h,即l的“真实”值为104.5m;ci的“真实”值为20g/l,ti的“真实”值为0.0028h,td的“真实”值为0.0056h;
11、(2)tsm模拟器将模拟区域划分为主通道和存储区域,并将主通道和存储区域之间进行线性溶质交换;主通道中,流速较快,溶质通过对流和弥散向下游运移;存储区中流速较慢,相比主通道中快速流视为静止,不发生对流和弥散作用,tsm模拟器方程如下:
12、
13、
14、式(1)、(2)中,t为时间;x为注入点下游距离;c和cs分别为主通道和存储区中浓度;a和as分别为主通道和存储区截面积;q为管道流量;d为弥散系数,α为交换系数。
15、优选的,所述的步骤二包括:
16、首先,通过es-mda方法反演参数,步骤如下:
17、(1)根据参数的先验分布生成参数集:先验参数集为-ne为参数集容量,n为参数集向量m中包含的参数个数;
18、(2)将先验参数集代入至otis软件即tsm模拟器中正演生成穿透曲线数据上标0指迭代次数;i=1,2,…,ne,nd为穿透曲线中浓度数据点个数;
19、(3)采用以下方程对参数集进行迭代更新:
20、
21、方程(1)中,l=1,2,…,na指迭代步,na为数据同化次数,即es-mda的总迭代数;指第l次迭代更新后的参数;为当前参数集和模拟浓度数据间的协方差矩阵,见方程(2);为模拟浓度数据的自协方差矩阵,见方程(3);
22、
23、
24、方程(1)中,为同化数据(dobs)观测误差的协方差矩阵;指第l迭代步带有误差的观察数据;
25、
26、方程(4)中,zd指从标准正态分布中随机采样数据;αl指用户自定义的当前迭代步的膨胀系数,该系数应该满足以下方程:
27、
28、然后,采用es-mda方法对参数集更新之前对参数向量的每个元素进行正态分布转换(normal-score transform),之后再对参数进行逆转换(back-transform),形成ns-es-mda方法,步骤如下:
29、(1)normal-score transform,即将非高斯分布的先验参数集m转换为高斯分布的参数集p:
30、
31、(2)基于高斯分布的参数集p进行迭代更新:
32、
33、
34、(3)将迭代更新后的参数集p进行逆变换back-transform,获得更新后的参数集m:
35、
36、方程(7)和方程(1)唯一的区别是方程(7)用于对转换后的参数集进行迭代更新,方程(7)中为当前参数集和模拟浓度数据间的协方差矩阵,的算法见方程(8)。
37、优选的,所述的步骤三中,基于4个cases进行岩溶管道中暂时存储模型参数的识别,其中,在case 1中,只校正4个模型参数,即d,a,as,α;在case 2中,同时校正4个模型参数和3个示踪参数,即ti,td,ci;在case 3中,同时校正4个模型参数和管道长度l;在case 4中,同时校正4个模型参数、3个示踪参数和管道长度。
38、优选的,所述的步骤三中,校正参数,指该参数在otis模拟器中未知,其初始值从均匀分布中随机采样获得;
39、在case 1中,首先研究基础场景,基础场景中,观测误差均值为0,方差为1×10-4,浓度监测限值为1×10-8,穿透曲线中有358个数据点,即nd=358,数据同化次数设为10,即na=10,所有迭代步中设置相同的膨胀系数即αi=10,见方程(5);
40、在其他case中,基础场景的观测误差、浓度监测限和case1相同,观测误差均值为0,方差为1×10-4;穿透曲线中有358个数据点即nd=358;在case 2和case 3中,na=16;在case4中,na=20;同样,所有迭代步中设置相同的膨胀系数,见方程(5);
41、在所有case中,设置不同的浓度监测限值为1×10-7,1×10-6,1×10-5,1×10-4,1×10-3,探讨其对参数识别性能的影响;相应地,穿透曲线中有329,301,271,240,207个数据点,即nd=329,301,271,240,207;除此之外,设置不同观测误差方差值为1×10-6,1×10-5,1×10-3,1×10-2,1×10-1,探讨其对参数识别性能的影响。
42、优选的,所述的步骤三中,设置不同观测误差方差值,探讨其对参数识别性能的影响包括:
43、首先生成300个参数集,构成先验参数集合,即ne=300,每个参数向量中的参数分别从均匀分布中独立进行采样;
44、然后,将初始参数集分别代入otis软件中,模拟生成穿透曲线,采用方程(3)-(9)去更新每一个参数向量,在每一次新的迭代中,将更新后的参数集代入otis软件中;
45、将最后一次迭代后的参数集称为后验参数集,相比先验参数集,后验参数集模拟得到的穿透曲线更加匹配“真实”穿透曲线;为了评价估计参数的不确定性,绘制箱型图;为了说明参数之间的相关关系,利用最后一次迭代后的后验参数集绘制相关系数热力图。
46、优选的,所述的步骤四包括:在每个case中,从3个方面分析参数反演结果,首先,在基础场景中从两方面分析:1)将后验参数集中值视为该方法对参数的估计值,根据箱型图,对比后验参数集中值(下文简称“后验中值”)和“真实”值的偏差,偏差越小说明参数识别效果越好;2)根据箱型图,分析后验参数集的不确定性大小,后验参数集中不同数据大小越接近说明不确定性越小,参数识别效果越好;之后,将基础场景以及其他不同浓度监测限值的箱型图放到一张图中进行对比,分析浓度监测限值从1×10-8逐渐增加至1×10-3时,参数识别效果的变化趋势;最后,将基础场景以及其他不同观测误差方差的箱型图放到1张图中进行对比,分析观察误差方差从1×10-6逐渐增加至1×10-1时,参数识别效果的变化趋势。
47、优选的,所述的步骤五包括:将case 2和case 1对比,分析示踪参数从已知变为未知时,模型参数不确定性的变化;将case 3和case 1对比,分析管道长度从已知变为未知时,模型参数不确定性的变化;将case 4和case 1对比,分析示踪参数和管道长度从已知变为未知时,模型参数不确定性的变化。
48、本发明一种识别岩溶管道中暂时存储模型参数的方法的有益效果为:
49、将正态分布转换(normal-score transform)纳入es-mda(即normal-score es-mda(ns-es-mda)),以解决先验和后验参数的潜在非高斯性,并首次将ns-es-mda用于识别岩溶管道暂态存储模型参数。es-mda可以同时反演模型参数、其他示踪剂参数和管道长度,计算成本较低。同时,它可以生成后验参数集合,以充分量化不确定性。此外,ns-es-mda确保联合参数向量服从高斯边缘分布,从而采用es-mda反演参数时能获得最优效果。本发明理论可行、实践方便、耗时短,能够在示踪参数和管道长度未知的条件下准确识别模型参数,且模型参数的不确定性较低。
50、说明书附图
51、图1、本发明识别岩溶管道中暂时存储模型参数方法流程图。
52、图2、ns-es-mda方法流程图。
53、图3、case 1中后验参数分布箱型图(不同observation limit监测限值)。
54、图4、case 1中后验参数分布箱型图(不同error variance观测误差方差)。
55、图5、case 2中后验参数分布箱型图(不同observation limit监测限值)。
56、图6、case 2中后验参数分布箱型图(不同error variance观测误差方差)。
57、图7、case 2中后验参数相关系数热力图。
58、图8、case 3中后验参数分布箱型图(不同observation limit监测限值)。
59、图9、case 3中后验参数分布箱型图(不同error variance观测误差方差)。
60、图10、case 3中后验参数相关系数热力图。
61、图11、case 4中后验参数分布箱型图(不同observation limit监测限值)。
62、图12、case 4中后验参数分布箱型图(不同error variance观测误差方差)。
63、图13、case 4中后验参数相关系数热力图。
64、图14、不同case中参数识别结果对比。
- 还没有人留言评论。精彩留言会获得点赞!