文本数据的聚类方法、装置、存储介质及电子设备与流程
本技术涉及人工智能领域,具体而言,涉及一种文本数据的聚类方法、装置、存储介质及电子设备。
背景技术:
1、在很多业务场景的分析中,我们经常需要将某一类具有相似特征的数据划分在一起,然后用于判别这些数据之间是否有很强的联系性。例如,金融领域中电商企业经常将同一地区商户归属地址相似划分在一起,判断这些商户地址是否过于集中,是否存在虚假填写等问题,或者将电商中用户的收获地址填写是否存在相似聚集情况,来判断这些用户是否属于集中套利行为。常见的文本聚类方法是使用tf-idf、lda、word2vec等方法得到文本的特征向量,然后采用k-means算法进行聚类划分。然而tf-idf、lda、word2vec分别通过计算文档频率,词袋模型等方式得到的特征向量的方法,只简单得到了文本特征的词频信息或局部静态语义信息,没有学习到文本之间强的语义信息。k-means聚类方法虽然计算速度快,拓展性强,但是由于对初始值敏感,仅适用于凸形簇,导致对非凸形状的数据集聚类效果不佳。
2、针对相关技术中对文本数据进行聚类时,没有考虑到文本数据之间语义信息的联系,导致聚类结果的准确率较低的问题,目前尚未提出有效的解决方案。
技术实现思路
1、本技术的主要目的在于提供一种文本数据的聚类方法、装置、存储介质及电子设备,以解决相关技术中对文本数据进行聚类时,没有考虑到文本数据之间语义信息的联系,导致聚类结果的准确率较低的问题。
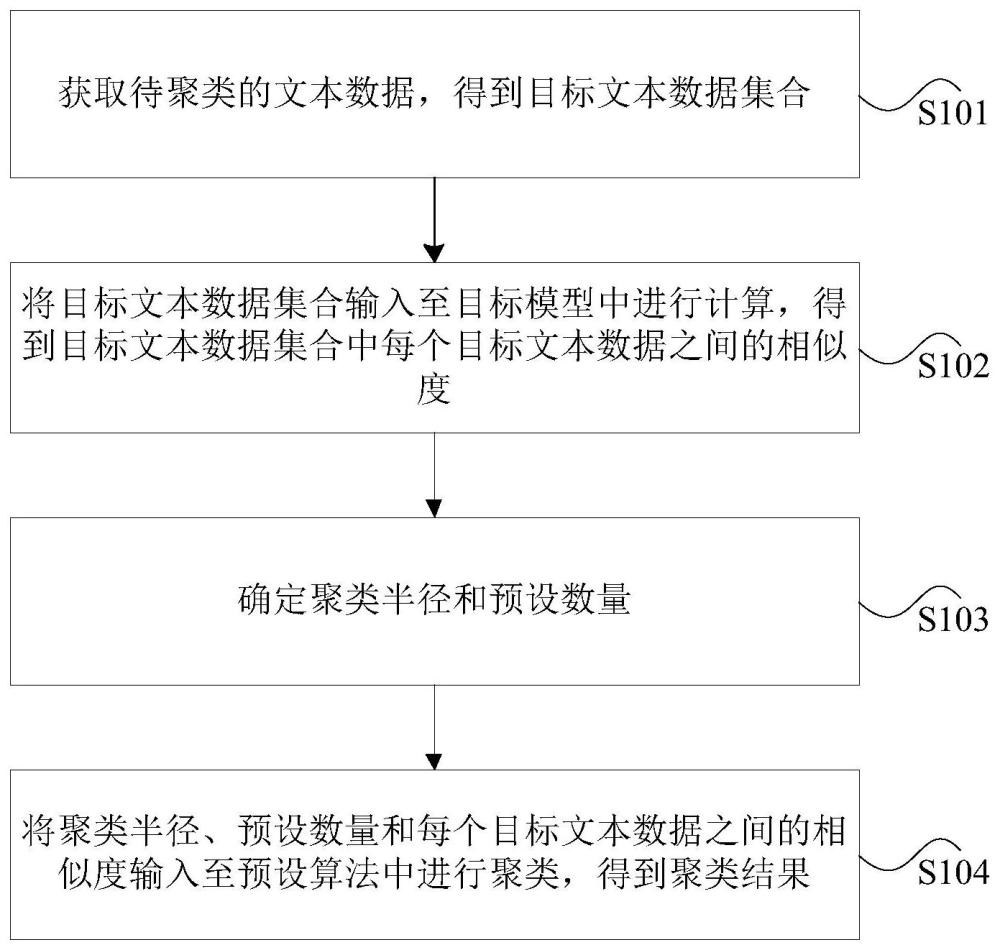
2、为了实现上述目的,根据本技术的一个方面,提供了一种文本数据的聚类方法,该方法包括:获取待聚类的文本数据,得到目标文本数据集合;将所述目标文本数据集合输入至目标模型中进行计算,得到所述目标文本数据集合中每个目标文本数据之间的相似度,其中,所述目标模型是采用文本数据对第一子模型和第二子模型进行训练后得到的模型,所述第一子模型用于提取文本数据的词向量,所述第二子模型用于计算文本数据之间的相似度;确定聚类半径和预设数量,其中,所述预设数量是指聚类后每类文本数据的数量区间;将所述聚类半径、所述预设数量和每个目标文本数据之间的相似度输入至预设算法中进行聚类,得到聚类结果。
3、进一步地,所述目标模型由以下步骤得到:获取文本数据,并对所述文本数据进行预处理操作,得到文本数据集合;对所述文本数据集合中的文本数据进行组合和标注,得到样本数据集合;将所述样本数据集合的每条样本数据输入所述第一子模型和所述第二子模型中进行计算,得到每个样本数据对应的相似度;采用每个样本数据的相似度和每个样本数据的标签对所述第一子模型的模型参数和所述第二子模型的模型参数进行迭代训练,得到所述目标模型。
4、进一步地,对所述文本数据集合中的文本数据进行组合和标注,得到样本数据集合包括:将所述文本数据集合中的每条文本数据与其它文本数据进行组合,得到m个组合后的文本数据,其中,m是正整数;将所述m个组合后的文本数据发送至目标对象,其中,所述目标对象对所述m个组合后的文本数据进行标注,得到所述m个组合后的文本数据的标签;依据所述m个组合后的文本数据和所述m个组合后的文本数据的标签确定m个样本数据,并将所述m个样本数据进行组合得到所述样本数据集合。
5、进一步地,将所述样本数据集合的每条样本数据输入所述第一子模型和所述第二子模型中进行计算,得到每个样本数据对应的相似度包括:将所述样本数据集合中的每个样本数据输入所述第一子模型中进行计算,得到每个样本数据的词向量;将每个样本数据的词向量输入所述第二子模型中进行计算,得到每个样本数据对应的相似度。
6、进一步地,所述第二子模型中至少包括:全连接层、激活函数。
7、进一步地,将所述目标文本数据集合输入至目标模型中进行计算,得到所述目标文本数据集合中每个目标文本数据之间的相似度包括:将所述目标文本数据集合中的每条目标文本数据与其它目标文本数据进行组合,得到组合后的目标文本数据;将所述组合后的目标文本数据输入所述目标模型中进行计算,得到所述目标文本数据集合中每个目标文本数据之间的相似度。
8、进一步地,在将所述聚类半径、所述预设数量和每个目标文本数据之间的相似度输入至预设算法中进行聚类,得到聚类结果之后,包括:确定所述聚类结果中的n类目标文本数据,其中,n是正整数;在所述n类目标文本数据中存在预设信息的第一类目标文本数据的情况下,依据所述第一类目标文本数据包含的目标文本数据生成告警信息;将所述告警信息发送至目标对象,其中,所述目标对象依据所述告警信息对所述第一类目标文本数据进行处理。
9、为了实现上述目的,根据本技术的另一方面,提供了一种文本数据的聚类装置,该装置包括:获取单元,用于获取待聚类的文本数据,得到目标文本数据集合;计算单元,用于将所述目标文本数据集合输入至目标模型中进行计算,得到所述目标文本数据集合中每个目标文本数据之间的相似度,其中,所述目标模型是采用文本数据对第一子模型和第二子模型进行训练后得到的模型,所述第一子模型用于提取文本数据的词向量,所述第二子模型用于计算文本数据之间的相似度;第一确定单元,用于确定聚类半径和预设数量,其中,所述预设数量是指聚类后每类文本数据的数量区间;聚类单元,用于将所述聚类半径、所述预设数量和每个目标文本数据之间的相似度输入至预设算法中进行聚类,得到聚类结果。
10、进一步地,所述计算单元包括:获取子单元,用于获取文本数据,并对所述文本数据进行预处理操作,得到文本数据集合;标注子单元,用于对所述文本数据集合中的文本数据进行组合和标注,得到样本数据集合;第一计算子单元,用于将所述样本数据集合的每条样本数据输入所述第一子模型和所述第二子模型中进行计算,得到每个样本数据对应的相似度;训练子单元,用于采用每个样本数据的相似度和每个样本数据的标签对所述第一子模型的模型参数和所述第二子模型的模型参数进行迭代训练,得到所述目标模型。
11、进一步地,所述标注子单元包括:组合模块,用于将所述文本数据集合中的每条文本数据与其它文本数据进行组合,得到m个组合后的文本数据,其中,m是正整数;发送模块,用于将所述m个组合后的文本数据发送至目标对象,其中,所述目标对象对所述m个组合后的文本数据进行标注,得到所述m个组合后的文本数据的标签;确定模块,用于依据所述m个组合后的文本数据和所述m个组合后的文本数据的标签确定m个样本数据,并将所述m个样本数据进行组合得到所述样本数据集合。
12、进一步地,所述计算子单元包括:第一计算模块,用于将所述样本数据集合中的每个样本数据输入所述第一子模型中进行计算,得到每个样本数据的词向量;第二计算模块,用于将每个样本数据的词向量输入所述第二子模型中进行计算,得到每个样本数据对应的相似度。
13、进一步地,所述第二子模型中至少包括:全连接层、激活函数。
14、进一步地,所述计算单元包括:组合子单元,用于将所述目标文本数据集合中的每条目标文本数据与其它目标文本数据进行组合,得到组合后的目标文本数据;第二计算子单元,用于将所述组合后的目标文本数据输入所述目标模型中进行计算,得到所述目标文本数据集合中每个目标文本数据之间的相似度。
15、进一步地,所述装置包括:第二确定单元,用于在将所述聚类半径、所述预设数量和每个目标文本数据之间的相似度输入至预设算法中进行聚类,得到聚类结果之后,确定所述聚类结果中的n类目标文本数据,其中,n是正整数;生成单元,用于在所述n类目标文本数据中存在预设信息的第一类目标文本数据的情况下,依据所述第一类目标文本数据包含的目标文本数据生成告警信息;发送单元,用于将所述告警信息发送至目标对象,其中,所述目标对象依据所述告警信息对所述第一类目标文本数据进行处理。
16、为了实现上述目的,根据本技术的一个方面,提供了一种计算机可读存储介质,所述计算机可读存储介质包括存储的计算机程序,其中,在所述计算机程序运行时控制所述计算机可读存储介质所在设备执行上述任意一项所述文本数据的聚类方法。
17、为了实现上述目的,根据本技术的一个方面,提供了一种电子设备,包括一个或多个处理器和存储器,存储器用于存储一个或多个程序,其中,当一个或多个程序被一个或多个处理器执行时,使得一个或多个处理器实现上述任意一项所述文本数据的聚类方法。
18、通过本技术,采用以下步骤:获取待聚类的文本数据,得到目标文本数据集合;将所述目标文本数据集合输入至目标模型中进行计算,得到所述目标文本数据集合中每个目标文本数据之间的相似度,其中,所述目标模型是采用文本数据对第一子模型和第二子模型进行训练后得到的模型,所述第一子模型用于提取文本数据的词向量,所述第二子模型用于计算文本数据之间的相似度;确定聚类半径和预设数量,其中,所述预设数量是指聚类后每类文本数据的数量区间;将所述聚类半径、所述预设数量和每个目标文本数据之间的相似度输入至预设算法中进行聚类,得到聚类结果,解决了相关技术中对文本数据进行聚类时,没有考虑到文本数据之间语义信息的联系,导致聚类结果的准确率较低的问题。通过对第一子模型和第二子模型进行训练,得到目标模型,能够利用第一子模型学习到上下文词语之间强的动态语义关系,从而学习到文本句子之间的相似性,解决了采用传统提取文本词向量的方法得到的词向量包含的语义信息过少,无法充分学习文本句子之间相似关系,导致相似度计算结果不准确和聚类结果不准确的问题,提高了计算结果的准确性,同时通过dbscn密度聚类函数将相似程度高的文本句子聚类在一起,提高了文本数据聚类结果的准确性。
- 还没有人留言评论。精彩留言会获得点赞!