一种基于云原生分布式数据库的跨节点数据访问优化方法与流程
本发明涉及云数据库,尤其涉及一种基于云原生分布式数据库的跨节点数据访问优化方法。
背景技术:
1、基于传统关系型数据库架构的分布式系统设计具有较高的技术复杂度,其主要有两个方面的原因,一方面复杂的关系模型对数据的组织和访问提出了很高要求,另一方面存储和计算耦合增加了系统在水平扩展、资源调度、故障转移、备份恢复等方面的难度,抛开依赖专有硬件的解决方案,业界主流的方案从上面两点入手,例如众多mpp架构的数据库系统采用share-nothing架构,在集群扩展性方面具有优势,但对于单个数据分片,还是传统的主从架构,存储和计算耦合的问题未能有效解决。而以存算分离为基础的各种云原生方案,虽然已经发展出多主架构,但为了平衡分布式场景带来的延迟和性能挑战,通常采用乐观锁一类的方式实现状态同步,这在实际应用时对业务提出更高的要求,如果业务不做流量的合理拆分,其写能力理论上也无法线性扩展。一种可行的方案是结合两种架构,具体的可以将mpp数据库运行在存算分离的架构上,这种架构结合二者的优势,能同时解决上述两个问题。
2、例如授权公告号为cn110990483b的中国专利公开了一种用于分布式缓存中的缓存节点的数据访问方法、控制方法、分布式缓存系统、分布式缓存中的业务节点及分布式缓存中的中心控制节点,待访问数据以erlang数据结构存储于缓存节点,缓存节点对应有虚拟节点,在访问待访问数据时,基于hash函数利用待访问数据的标识查找与待访问数据的标识相映射的虚拟节点,然后远程调用缓存节点并从缓存节点中本地查找以erlang数据结构存储的待访问数据。如果缓存节点中存在该待访问数据,则从缓存节点中读取待访问数据,避免了直接从数据库中读取待访问数据,避免了对数据库io造成巨大的压力。
3、以上专利均存在本背景技术提出的问题:复杂的关系模型对数据的组织和访问提出了很高要求,存储和计算耦合增加了系统在水平扩展、资源调度、故障转移、备份恢复等方面的难度,为解决以上问题,本技术设计了一种基于云原生分布式数据库的跨节点数据访问优化方法。
技术实现思路
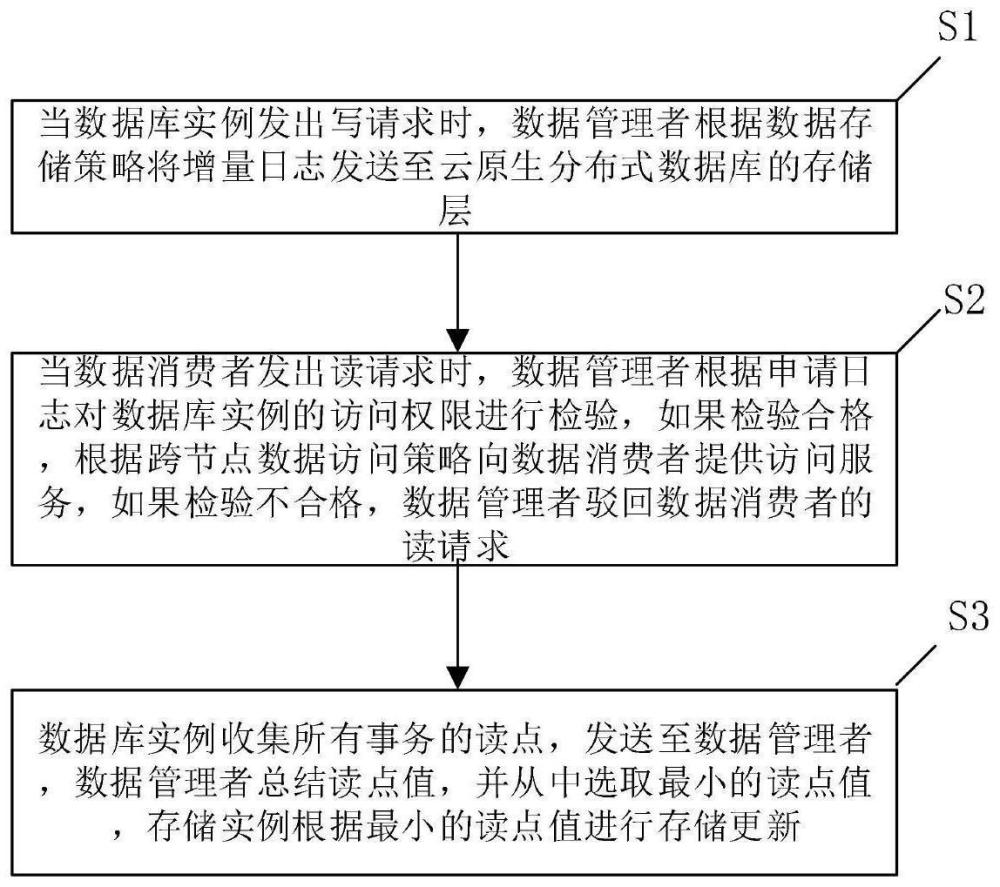
1、本发明所要解决的技术问题是针对现有技术的不足,提供了一种基于云原生分布式数据库的跨节点数据访问优化方法,首先数据管理者根据数据存储策略将增量日志发送至云原生分布式数据库的存储层,其次当数据消费者发出读请求时,数据管理者根据申请日志对数据库实例的访问权限进行检验根据跨节点数据访问策略向数据消费者提供访问服务,最后数据库实例收集所有事务的读点,发送至数据管理者,数据管理者总结读点值,并从中选取最小的读点值,存储实例根据最小的读点值进行存储更新。
2、为实现上述目的,本发明提供如下技术方案:
3、一种基于云原生分布式数据库的跨节点数据访问优化方法,包括以下步骤;
4、s1:当数据库实例发出写请求时,数据管理者根据数据存储策略将增量日志发送至云原生分布式数据库的存储层;
5、s2:当数据消费者发出读请求时,数据管理者根据申请日志对数据库实例的访问权限进行检验,如果检验合格,根据跨节点数据访问策略向数据消费者提供访问服务,如果检验不合格,数据管理者驳回数据消费者的读请求;
6、s3:数据库实例收集所有事务的读点,发送至数据管理者,数据管理者总结读点值,并从中选取最小的读点值,存储实例根据最小的读点值进行存储更新;
7、所述s1中所述增量日志包括待存储的数据和数据库实例的写请求;
8、所述s1中所述数据存储策略的具体步骤如下:
9、s1.1:数据管理者接收数据库实例发出写请求,将写请求和待存储的数据进行封装,将增量日志转发至云原生分布式数据库的存储层;
10、s1.2:存储层中的存储实例接收增量日志,并对存储的数据进行排序,根据递增原则对新接收的增量日志的日志序列号进行更新,存储层对新接收的增量日志进行重新封装,添加日志序列号,转发至数据管理者;
11、s1.3:数据管理者接收添加日志序列号的增量日志,并将日志序列号添加至已完成持久化日志,对已完成持久化日志的日志序列号序列进行检查,如果检查不合格,发出报错,如果检查合格,将已完成持久化日志中最新的日志序列号作为一致性读点;
12、s1.4:数据管理者将最新的一致性读点添加至增量日志,并将更新后的增量日志转发给数据库实例;
13、s1.5:数据库实例持续从数据管理者获取最新的增量日志,根据增量日志中的一致性读点更新数据库实例的一致性读点序列,同时在内存中回放一致性读点之前的所有日志操作;
14、所述s1.3中所述检查包括连续性检查和完整性检查,所述连续性检查包括序号连续性检查,所述完整性检查包括内容完整性检查和流程完整性检查;
15、所述s2中所述申请日志包括数据消费者的访问权限和数据消费者的读请求;
16、所述跨节点数据访问策略的具体步骤如下:
17、s2.1:数据管理者接收数据消费者的申请日志,并从申请日志中提取出待执行的申请访问语句,并根据预设的匹配规则匹配出与申请访问语句对应的目标访问数据标识;
18、s2.2:数据管理者根据哈希函数对目标数据标识进行映射,获取目标访问数据的一致性读点,并将目标访问数据的一致性读点转发至数据数据库实例;
19、s2.3:数据库实例接收目标访问数据的一致性读点,将目标访问数据的一致性读点对应的存储位置进行标识,设置读点,并创建数据副本;
20、s2.4:数据库实例将反馈信息发送至数据消费者,数据库消费者将读点作为版本号直接从存储层读取存储实例所保存的数据,并在读取结束后及时释放反馈信息;
21、所述s2.4中所述反馈信息包括读点和数据副本;
22、所述s3具体步骤如下:
23、s3.1:数据库实例收集所有事务的读点,根据读点的日志序列号进行递增排序,将最小的日志序列号作为数据库实例最小值定位;
24、s3.2:数据管理者收集所有数据库实例的数据库实例最小值定位,对数据库实例最小值定位进行排序,获取最小值,将最小值发送至存储实例,存储实例对小于最小值的日志进行应用和回收操作,不再支持小于最小值版本的页面读请求;
25、一种存储介质,所述存储介质中存储有指令,当计算机读取所述指令时,使所述计算机执行所述的一种基于云原生分布式数据库的跨节点数据访问优化方法;
26、一种电子设备,包括处理器和所述的存储介质,所述处理器执行所述存储介质中所述的一种基于云原生分布式数据库的跨节点数据访问优化方法。
27、与现有技术相比,本发明的有益效果是:
28、1.本发明实现数据消费实例直接从存储实例读取其它实例数据,解决读写冲突问题,减少一次网络转发,从而提升性能表现;
29、2.本发明对延迟不敏感的数仓类产品实现了云原生架构融合可以有效减少网络io,降低延迟,提升吞吐,使云原生分布式数据库架构拥有和经典云原生架构接近的延迟和性能表现。
- 还没有人留言评论。精彩留言会获得点赞!