一种基于端边云架构的神经网络多任务推理方法和装置
本发明涉及一种基于深度强化学习的神经网络多任务端边云协同推理方法和装置,属于动态调度。
背景技术:
1、深度学习近几年在各领域得到了广泛应用,然而,深度学习的推理是一项耗时的工作,尤其是在资源受限的本地设备上。当有多个深度学习任务需要同时在同一台机器上推理时,任务需要等待前一任务完成才能继续推理,延迟变得尤为明显。
2、由于本地设备的计算能力较弱,边缘计算是缓解本地压力的一项技术,边缘设备具有较快的推理速度,并通过将边缘服务器部署在离本地设备比较近的地方来降低数据传输时延。然而,仅有边缘设备往往不足以解决推理延迟高的问题,此时可以考虑加入云端设备,云端设备具有比边缘设备更快的推理速度,但缺点在于数据传输至云端的传输耗时更长。神经网络的推理可以利用上述的端边云协同架构,首先确定神经网络推理任务的分割点,将分割点前的本地推理中间结果传输至边缘或云设备继续推理。当有多个任务同时需要推理时,还可以通过合理安排端边云的任务分割点和执行顺序来最小化总完成时间。采用端边云协同的架构可以有效解决神经网络多任务推理延迟的问题,但仍需要在传输时延和推理速度进行有效平衡,以更好满足实时性的需要,因此需要快速决定每个任务的分割点和任务执行顺序。
3、柔性车间调度算法可以简述为:车间有一批存有既定工序的工件,每个工件中的每一道工序有一个或多个机器可以进行加工,需要确定每一台机床的加工工序及其加工顺序以达到一个或者多个加工目标。多个推理任务的神经网络如果已经确定切割点,那么获取每个任务在端边云三台机器上的推理时间,就可以将问题建模成柔性车间调度算法问题,工序为切割点前后的两道工序,机器为本地、边缘、云,可以采用深度强化学习进行求解。然而,现有研究不求解每个任务各自的切割点,独立求解切割点存在以下问题:
4、1.切割状态难以表示。如果想一次性求解所有任务的切割点,以alexnet为例,每个任务有20个可供选择的分割点,进行k个任务的编排,那么输出就有20的k次方的可能性,这在任务数量较大的时是不可接受的。动作空间难以通过多层感知机表示,神经网络也难以学习到相关知识。
5、2.需要预训练多个柔性车间调度模型。如果采用逐一确定切割点的办法,当任务数量变化时,问题具有不同尺寸,柔性车间调度问题的强化学习方案泛化性能普遍不佳,需要训练多个尺寸的柔性车间调度模型。
6、3.数据分布不合理。柔性车间调度问题的训练数据不易于获取,现有技术大多是通过产生随机数的方法生成训练数据,对于神经网络多任务端边云协同推理的特定场景拟合不佳。
7、4.实时性不佳。如果采用遍历所有切割可能性的方法,不能满足实时性需求。
技术实现思路
1、本发明要克服现有技术的上述不足,提供一种基于端边云架构的神经网络多任务推理方法和装置,同时求解任务分割和任务调度。
2、本发明通过端边云协同推理的方式减少一批任务的推理总时间,首先将不同任务根据神经网络的分层进行不同的分割,再进一步进行对应任务执行机器及执行顺序的调度,将任务发送到对应的端侧,完成推理的整个过程。本发明公开了计算任务分割和任务调度的原理,通过端边云协同完成一批任务的推理,减少推理的总时间。
3、本发明的目的是通过以下技术方案来实现的:一种基于端边云架构的神经网络多任务推理方法,包括以下步骤:
4、步骤1:将用于推理的深度神经网络模型,数据集同步至本地、边缘、云设备
5、步骤2:根据本地、边缘、云设备的硬件环境,数据集及网络传输条件,计算出每一层的输入张量大小以及每一层在不同设备上的推理时间。
6、步骤3:将模型切割成两个部分,计算神经网络在切割点前在本地推理的总时间,计算在切割点后在边缘或云设备上推理的总时间。
7、步骤4:多任务推理包含多个相同尺寸的推理任务,不同任务可以有不同的切割点。每个任务首先在本地运行至切割点,得到中间结果后发送至边缘或云设备上继续运行,得出最终的推理结果。同一设备同一时间只能运行一项任务,每个任务在得到最终推理结果后完成。求解目标是所有任务完成总时间的最小值
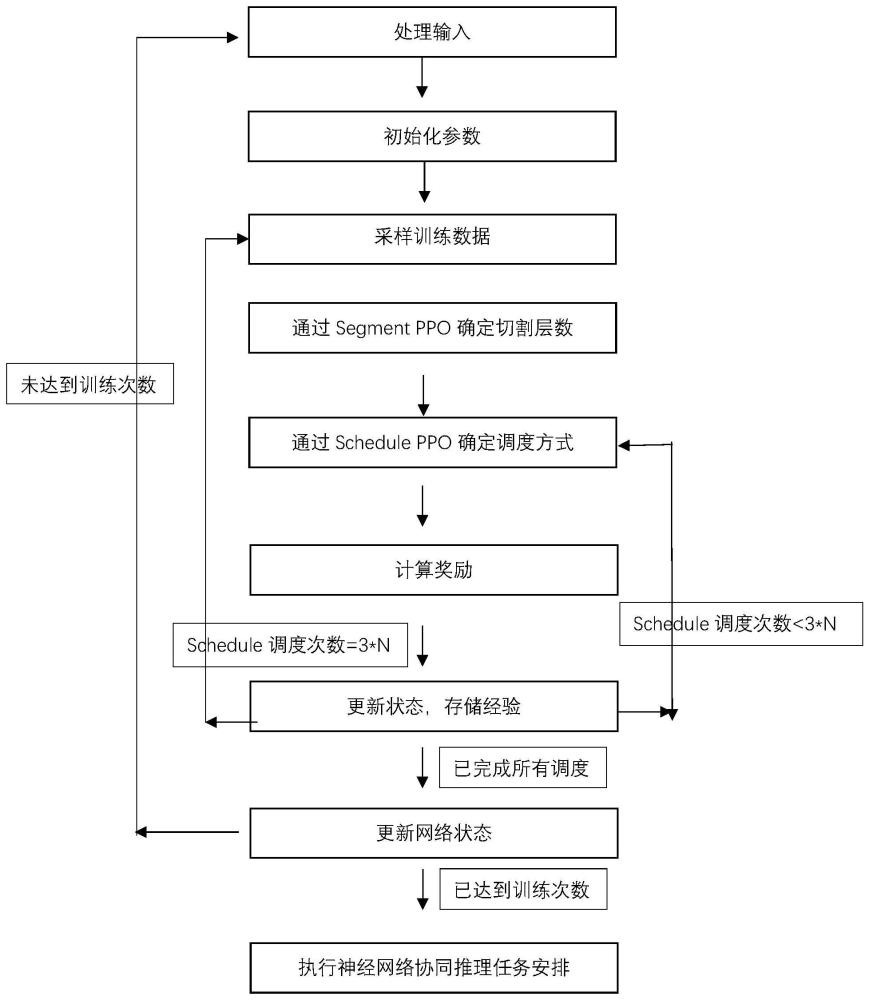
8、步骤5:训练深度强化学习模型,并应用训练好的深度强化学习模型,决定分割点、执行机器和执行顺序,实现步骤4)的目标,保证业务场景的实时性,提高推理的效率。
9、进一步地,步骤1所述的深度神经网络模型包括用于图片识别的alexnet、vgg、googlenet、resnet和用于目标检测的ssd、yolo、r-cnn、fast r-cnn。
10、进一步地,所述步骤3)中,本地设备的推理总时间是网络第一层至切割层的叠加时间,边缘或云设备的推理总时间是切割层至最后一层的叠加时间,且需要叠加中间结果传输至边缘或云上的处理时间,具体定义如下:
11、具体定义如下:
12、表示神经网络在第i层的推理时间,其计算方式为计算量/不同机器的推理速率。
13、si为第i层的参数大小;
14、bedge,bcloud为本地至边缘、本地至的网络传输速度。
15、计算任务在不同切割层数l时,在本地、云、边缘上的运行时间,其中,本地、云上的运行时间需要计算参数从本地传递至对应网络上的时间。
16、
17、
18、
19、进一步地,步骤4)所述求解目标,最小化总完成时间的表述如下:
20、确定在第l层切割的任务首先在本地设备上运行s1阶段,运行时间为完成后选择边缘/云设备的其中一个完成s2阶段,运行时间为或
21、用dji表示任务j的si阶段开始时间,用cji表示任务j的si阶段完工时间
22、
23、
24、其中dj2>cj1,dj1,dj2时刻对应的机器必须空闲。
25、假设多任务的任务个数为k,那么最终所求的完工时间
26、cmax=max(cj2)j∈1,2…,k (1.6),
27、目标是最小化cmax,也就是最小化总完成时间。
28、进一步地,步骤5所述的深度强化学习模型的结构如下:
29、深度强化学习模型包含两个子模块,即segment ppo和schedule ppo。其中segment ppo决定任务的切割层数,schedule决定任务的执行机器及执行顺序。两个网络的结构总体一致,均为输入层、输个隐藏层和输出层的结构,均采用actor-critic架构,并采用广义优势估计和clip提高学习效率和稳定性;其中segment ppo输入层的输入维数和定义的segment状态的维数保持一致,schedule ppo从当前所有已确定切割层数的任务中选择对应的工序及机器进行调度,输入层的输入维数和定义的schedule状态的维数保持一致;隐藏层segment ppo和schedule ppo均采用多层全连接层;双输出子网包括动作选择网络和状态价值函数网络,动作选择网络由actor计算,输出维度评估当前状态下每个动作a的相对优劣,状态价值函数网络v由critic计算,负责评估状态s的价值,协助actor调整策略。其中segment ppo的ppo输出维度为当前神经网络可供选择的切割层数,schedule ppo的输出维度为多任务个数及可供选择机器的乘积,即k*3。两个ppo网络共享reward以及critic。
30、本发明的第二个方面涉及一种基于端边云架构的神经网络多任务推理装置,包括存储器和一个或多个处理器,所述存储器中存储有可执行代码,所述一个或多个处理器执行所述可执行代码时,用于实现本发明的基于端边云架构的神经网络多任务推理方法。
31、本发明的第三个方面涉及一种计算机可读存储介质,其上存储有程序,该程序被处理器执行时,实现本发明的基于端边云架构的神经网络多任务推理方法。
32、本发明提出double-ppo算法,综合考虑了神经网络切割segment和车间调度schedule两个子问题,将两个子问题合并成一个问题进行计算,用一个大模型来训练深度强化学习,解决了车间调度训练数据来源、泛化能力差带来的多次训练以及状态难以定义的问题。
33、本发明优点如下:
34、1.本发明采用double-ppo算法,将两个子模块segment-ppo,schedule-ppo合并到一个模型中求解,两个子ppo共享reward以及critic,并互相传递全局状态特征以获得更好的动作选择函数,解决了传统ppo只能有一个动作输出的问题。
35、2.精细定义了segment和schedule的状态,提出了不同于现有研究的状态表达,可以更加有效的表述神经网络端边云切割场景下的状态,利于神经网络学习。
36、3.另外,reward的设置同时参考了segment和schedule的价值,能为深度强化学习提供更准确的指引。
- 还没有人留言评论。精彩留言会获得点赞!