一种基于分流的分布式数据脱敏系统及其方法与流程
本发明涉及数据脱敏,具体涉及一种基于分流的分布式数据脱敏系统及其方法。
背景技术:
1、目前的分布式数据脱敏方法主要分为四种类型,第一种是基于分表的方式,第二种是基于切片的方式,第三种是基于分数据块的方式,第四种是基于代理的方式,但他们各有缺陷或者有一定的前提:
2、基于分表的方式,这种方法能够做到的数据分发粒度较粗,一个数据库表只能分配在一个节点上处理,假如数据库中的表数据量本身是很不平均的,整个节点集群就得不到很高的利用率;
3、基于切片的方式,这种方法对数据源有要求,一般是要求数据库的存储文件本身就是能够分割的,而当今普遍使用的关系型数据库如oracle的存储文件是不能进行分割的,也就无法利用这种方法进行分布式脱敏处理;
4、基于分数据块的方式,这种方法对数据源同样有要求,一般需要数据库提供对数据的切分方式,例如使用oracle的rowid,或者如数据表本身存在id主键值就使用这个主键值,但大多数数据库都没有rowid特性,且实际数据库表的设计多样复杂,不可能每一个都存在可使用切分的id值,即便存在id值,但id值本身也可能不是连续的,无法做到快速均衡切分,也就依然无法利用这种方法进行分布式脱敏处理;
5、基于代理的方式,代理服务器需要在应用层通过数据库驱动和数据源通信,因为代理服务程序一般运行于系统协议栈,并且还需要首先把通信数据还原成真实数据才能分发,其本身成为了通信瓶颈。
6、基于此,本发明设计了一种基于分流的分布式数据脱敏系统及其方法以解决上述问题。
技术实现思路
1、针对现有技术所存在的上述缺点,本发明提供了一种基于分流的分布式数据脱敏系统及其方法。
2、为实现以上目的,本发明通过以下技术方案予以实现:
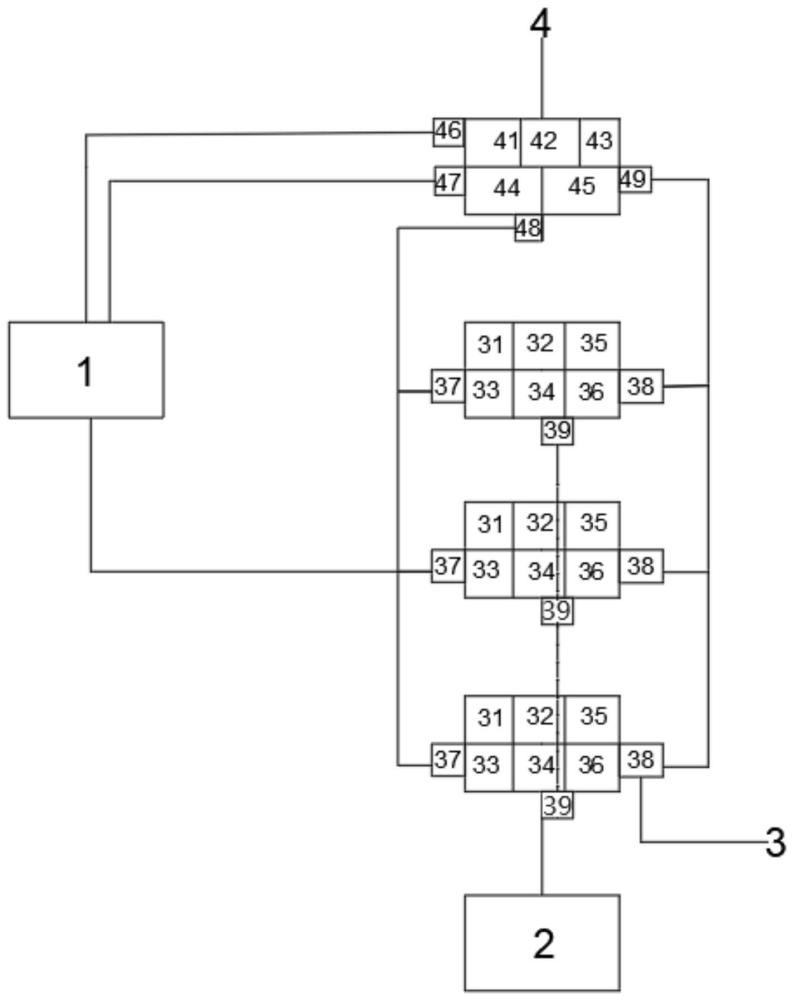
3、一种基于分流的分布式数据脱敏系统,包括数据源、目标库、工作节点和领导节点,所述领导节点与数据源、工作节点均连接,所述工作节点与数据源、目标库均连接;
4、所述数据源用于储存多组数据表;
5、所述目标库用于写入脱敏后的数据表;
6、所述领导节点用于设置数据表的行数阈值以及用于获取所述数据源数据表的行数,领导节点根据数据表的行数与行数阈值进行比较,来决定数据表的处理方式,处理方式包括将数据表的数据获取任务分配至单一工作节点或将数据表的返回流量分流至多个工作节点;
7、所述工作节点有多个,用于收到数据表的数据获取任务时对数据表数据的获取、收到分流的数据表的返回流量的校正和解析、以及两种情况下得到的数据表数据的脱敏处理;
8、当所述领导节点将数据表的数据获取任务分配至单个工作节点工作时,工作节点直接从数据源获取该数据表的数据并进行脱敏处理后写入目标库;
9、当所述领导节点将数据表的返回流量分流至多个工作节点时,由领导节点从数据源读取数据表的数据并直接对返回流量进行切分为若干个序列号段,并将切分后的序列号段逐一分流至多个工作节点进行处理,每个工作节点对收到的序列号段进行校正解析和脱敏处理并对脱敏处理后的数据同步保序写入目标库。
10、更进一步的,所述领导节点的单元包括:
11、数据表阈值单元,其用于设定数据表行数阈值并根据行数阈值判定数据表的处理方式;
12、数据表分配单元,其用于数据表行数不超过行数阈值时对数据表的数据获取任务进行分配到工作节点;
13、数据获取单元,其用于数据表行数超过行数阈值时对数据进行数据获取;
14、数据分流单元,其用于数据表行数超过行数阈值时对数据源返回的数据表流量切分为若干个序列号段;
15、所述领导节点的接口包括:
16、数据表扫描接口,其用于得到数据源中每个数据表行数;
17、数据获取接口,其用于向数据源读取数据表数据;
18、分配任务和检测接口,其用于发送数据表的数据获取任务到单个工作节点;
19、数据分流接口,其用于把切分的序列号段发送到多个工作节点。
20、更进一步的,所述数据分流单元将数据表的返回流量切分为若干个长度相同的序列号段。
21、更进一步的,所述工作节点的单元包括:
22、数据表获取单元,其用于接收到数据表的数据获取任务时,向数据源中获取该数据表的数据;
23、数据预解析单元,其用于接收到分流的数据表的返回流量序列号段时,对序列号段预解析并进行完整性判断;
24、数据校正单元,其用于对预解析序列号段后的尾部不完整的数据生成修复序列号段,并将修复序列号段单播到需要的其他工作节点,或者对还不能预解析的序列号段发出需要修复序列号段的组播请求;
25、数据解析单元,其用于序列号段校正后,对序列号段进行完全解析;
26、数据脱敏单元,其用于对由自身获取的数据表的数据或者对收到的序列号段完全解析后得到的数据进行脱敏处理;
27、数据入库单元,其用于单个数据表数据脱敏后的直接写入目标库,或接收分流的序列号段进行解析脱敏后的同步写入目标库。
28、更进一步的,所述工作节点的接口包括:
29、任务接收接口,其用于接收数据表的数据获取任务并向数据源发送读取该表的请求和接收数据源返回该表的数据;
30、接收流量校正同步接口,其用于接收数据分流接口分流的序列号段,并和其他接收流量校正同步接口之间互相同步校正数据;
31、入库接口,其用于把脱敏后的数据写入目标库,并和其他入库接口同步组播入库完成消息。
32、更进一步的,所述领导节点还包括工作节点检测单元,所述工作节点检测单元用于对工作节点的运行状态监测。
33、更进一步的,所述分配任务和检测接口还用于配合工作节点检测单元发送检测请求;
34、所述任务接收接口还用于响应分配任务和检测接口的检测请求。
35、为了更好地实现本发明的目的,本发明还提供了一种基于分流的分布式数据脱敏方法,包括以下步骤:
36、步骤一,通过数据表阈值单元设置数据表行数阈值;
37、步骤二,通过数据表扫描接口获取数据源的数据表行数:
38、步骤三,数据表阈值单元通过判定该数据表行数是否大于行数阈值;
39、步骤四,若数据表阈值单元判断为否,则数据表分配单元通过分配任务和检测接口将数据表的数据获取任务分配至某个任务接收接口;
40、任务接收接口接收分配的任务后数据表获取单元通过任务接收接口从数据源获取该数据表的数据;
41、数据脱敏单元对获取的该数据表的数据进行脱敏处理;
42、数据入库单元将脱敏后的数据表数据通过入库接口写入目标库中;
43、步骤五,若数据表阈值单元判断为是,则数据获取单元通过数据获取接口向数据源发起数据表读取请求,并把请求的返回流量分流至多个接收流量校正同步接口;
44、数据获取接口从数据源接受该数据表的返回流量,数据分流单元将该数据表的返回流量进行切分为若干个序列号段,其中包括序列号从零起的序列号段和非零起的序列号段,通过数据分流接口将这些序列号段进行分流到多个接收流量校正同步接口;
45、步骤六,数据获取接口将向数据源发送回复确认;
46、步骤七,接收流量校正同步接口接收到序列号段,第一次判断接收的序列号段是否从零起;
47、第一次判断,若是:
48、步骤八,数据预解析单元对序列号段进行解析并判断其最后一行信息的完整性;
49、步骤九,若数据预解析单元判断该序列号段数据为完整,数据校正单元通过接收流量校正同步接口向其他接收流量校正同步接口发送“可以”的组播消息;
50、步骤十,数据解析单元解析该序列号段;
51、步骤十一,数据脱敏单元对解析后的序列号段进行脱敏处理;
52、步骤十二,若数据预解析单元判断为该序列号段数据不完整,数据校正单元将该段序列号段中不完整的部分分离出来,并生成修复序列号段,通过接收流量校正同步接口将修复序列号段单播发送至定向工作节点的接收流量校正同步接口;
53、步骤十三,第二次判断脱敏后的序列号段是否从零起;
54、第二次判断,若是:
55、步骤十四,则数据入库单元通过入库接口将脱敏后的序列号段写入目标库;
56、步骤十五,随后入库接口向其他入库接口发出该序列号段“完成”的组播消息;
57、第二次判断,若否:
58、步骤十六,则入库接口等待接收上一序列号段“完成”的组播消息,该入库接口接收后跳回步骤十四;
59、第一次判断,若否:
60、步骤十七,数据校正单元通过接收流量校正同步接口向其他接收流量校正同步接口发出“等待”的组播消息;
61、步骤十八,当接收流量校正同步接口收到“可以”的组播消息后跳回步骤八;
62、步骤十九,当接收流量校正同步接口接收到修复序列号段后,数据校正单元对收到的修复序列号段和自身的序列号段组合并跳回步骤八。
63、还包括以下步骤:
64、步骤二十,工作节点检测单元通过分配任务和检测接口向任务接收接口发送检测请求;
65、步骤二十一,任务接收接口接收到检测请求并回复分配任务和检测接口;
66、分配任务和检测接口接收到任务接收接口的回复;
67、工作节点检测单元对回复的任务接收接口的工作节点标记为可用;
68、步骤二十二,分配任务和检测接口发送检测请求连续三次没回复;
69、工作节点检测单元对没有回复的任务接收接口的工作节点标记为不可用;
70、步骤二十三,工作节点检测单元对分流至标记为不可用的工作节点并且没有通过入库接口发出“完成”的组播消息的序列号段,则通过数据分流接口将该序列号段重新分配到其他的工作节点的接收流量校正同步接口。
71、采用下列公式:修复序列号段的最大长度为fix(len)=l,修复序列号段流量占比为q=1/m,t=m*s,sum(t)=m*s*n,其中m的值是指序列号段中的数据行数,m的默认值为10000并可以手动配置,l表示数据表每行数据最大的长度;
72、单个工作节点一个序列号段校正时需要循环次数为m,s表示循环一次需要的时间,t表示单个工作节点校正耗时,sum(t)表示n个工作节点的总校正耗时,由于节点间校正需要同步,而节点间解析和脱敏可以并行,设一行解析需要时间为s1,一行脱敏时间需要s2,则一个序列号段解析耗时t1=m*s1、脱敏耗时t2=m*s2,则n个工作节点对序列号段的校正耗时占比为
73、
74、本发明具有以下技术效果:
75、本发明使用时,领导节点根据表行数设定阈值决定数据表的处理方式为直接分配到某个工作节点单独处理还是数据表流量切分为序列号段后分配到多个工作节点处理;该方式可以分表亦可以基于分流的对数据源进行切分的方式,直接对原始流量进行序列号段切分而非对应用数据进行切分,对数据源不设要求,能够最大限度适配各种数据源。
- 还没有人留言评论。精彩留言会获得点赞!