一种基于马尔可夫链模型的代码克隆检测方法
本发明属于代码克隆检测,具体涉及一种基于马尔可夫链模型的代码克隆检测方法。
背景技术:
1、软件系统内部或软件系统之间相似的代码片段称为克隆的代码片段。当开发人员通过复制、粘贴和修改来重用代码时,就会创建克隆。开发人员需要检测和管理他们的克隆,以保持软件质量、检测和防止新的错误及降低开发风险和成本等。代码克隆检测的目的是挖掘出功能相似的代码片段,在软件工程中引起了广泛的关注。
2、根据相似度类型的不同,可将代码克隆分为四种类型:(1)type-1类型的代码克隆是指除了不同的空白、布局和注释其它完全相同的代码片段;(2)type-2类型的代码克隆是指除了type-1克隆的差异、标识符名称和词法值不同之外,代码片段完全相同:(3)type-3类型的代码克隆是语法相似的代码片段,但在语句级别有所不同;除了type-1和type-2克隆的差异之外,这些片段之间还会相互添加、修改或删除语句;(4)type-4类型的代码克隆是指语法上不同的代码片段实现相同的功能,即语义克隆类型。
3、目前已经提出了很多检测代码克隆的方法。例如,ccfinder通过词法分析从输入代码中提取令牌序列,并应用几种基于规则的转换将令牌序列转换为规则形式,以检测type-1和type-2克隆。为了检测更多类型的克隆,设计了另一个最先进的基于令牌的工具sourcerercc。它在不同的方法中捕获令牌的重叠相似性,以检测type-3类型克隆。sourcerercc是最具可扩展性的代码克隆检测器,它可以扩展到非常大的代码(例如250m行代码)。然而,由于缺乏对程序语义的考虑,这些基于令牌的方法不能处理type-4克隆,即语义克隆。为了解决这些问题,研究人员进行程序分析,将代码片段的语义提炼成图或树来表示,例如ast、pdg、cfg等,并进行树匹配或图匹配,以测量给定代码之间的相似性。这种基于树匹配或图匹配的代码克隆检测方法,与基于令牌的检测方法相比,在检测type-4类型的代码克隆上具有更高的效率,但由于图匹配和树匹配时间复杂度非常高,消耗时间过长,它们无法扩展到大规模的代码。
技术实现思路
1、针对目前代码克隆检测方法难度大、效率低的问题,本发明目的旨在提供一种基于马尔可夫链模型的代码克隆检测方法,在提高检测准确率的同时,能够极大减少时间开销,并提高可扩展性。
2、由于树匹配有较大的时间开销,本发明将ast中有序相连的两个节点看作初始状态,与之相连的下一个节点看作下一状态,以此建立二阶马尔可夫链模型来描述节点之间的状态转换。通过将树状的结构转换成易于分析的状态转移概率矩阵来减少时间开销。通过计算相似性距离,获得ast之间所有状态的距离向量,进而对得到的距离向量的每个特征进行特征过滤和筛选来减少时间开销,提高可扩展性。最后根据得到的特征训练一个分类器,来实现简洁有效的语义代码克隆检测。该方法主要由五个阶段组成:ast生成、状态矩阵构建、特征提取、特征选择和分类。
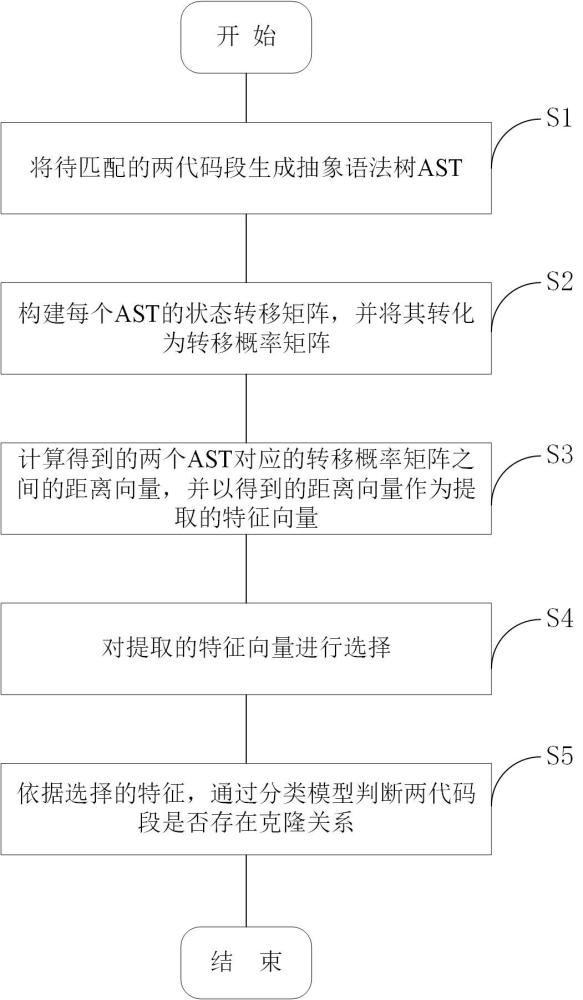
3、基于上述分析,本发明提供的基于马尔可夫链模型的代码克隆检测方法,其包括以下步骤:
4、s1 将待匹配的两代码段生成抽象语法树ast;
5、s2 对于每个ast,将ast中的节点按照连续的三个节点为一组进行拆分;基于马尔可夫链,构建每个ast的状态转移矩阵,并将其转化为转移概率矩阵;
6、s3 计算得到两个ast对应的状态转移概率矩阵之间的距离向量,并以得到的距离向量作为提取的特征向量;
7、s4 对提取的特征向量进行选择;
8、s5 依据选择的特征,通过分类模型判断两代码段是否存在克隆关系。
9、上述步骤s1,此阶段的目的是应用静态分析工具得到两个代码段对应的ast。此阶段的输入为程序源代码,输出为ast。
10、上述步骤s2,此阶段的目的是基于马尔可夫链原理将ast转换为状态转移概率矩阵。此阶段的输入为ast,输出为状态转移概率矩阵。在具体实现方式中,步骤s2包括以下分步骤:
11、s21将ast中的节点按照连续的三个节点为一组进行拆分;前两个连续的节点作为马尔可夫链状态转换的初始状态,另外一个节点作为马尔可夫链状态转换中的另一状态;
12、s22 基于马尔可夫链状态转换中的两个状态构建状态转移矩阵;
13、s23 将状态转移矩阵转化为转移概率矩阵。
14、上述步骤s21中,以节点类型表征节点状态。对于ast,其包含叶节点和非叶节点,叶节点包含14种令牌类型,非叶节点包含57种代码语法类型,并添加一个null类型来表示未包含在14种令牌类型的其他令牌类型;因此,对于一个节点有72种类型,定义72种状态。而对于连续的两个节点,一般只存在493种类型,因此有493种初始状态。
15、上述步骤s22中,状态转移矩阵中的元素matrix[i][j]的值表示ast中第i个初始状态转换为第j个下一状态的次数。
16、上述步骤s23中,假设状态转移矩阵为m1,则状态转移概率矩阵m2元素的计算公式为:
17、;
18、式中,k表示状态转移矩阵m1的列数(也即下一状态的数量)。
19、上述步骤s3,此阶段的目的是计算两个状态转移概率矩阵的距离向量。此阶段的输入是两个矩阵,输出是它们的特征向量。本发明中,将两个ast的转移概率矩阵的对应行向量进行距离计算,得到的距离值构成距离向量。为了提高检测精度,本发明采用两种以上的距离计算方法计算两个ast对应的转移概率矩阵之间的距离向量,并将不同方法计算得到的距离向量在维度上进行拼接。
20、上述步骤s4,此阶段的目的是对特征提取阶段得到的特征向量进行选择。本发明通过训练集确定若干对检测有影响的若干特征。
21、本发明基于训练集得到的样本特征向量进行过滤和筛选。此阶段的输入是包含全部特征的特征向量,输出是选择后的特征数量较少、包含有用信息较多的特征向量。在具体实现方式中,特征过滤是基于统计值的筛选方法,主要通过计算特征和特征目标变量之间的相关性、自相关性、发散性等统计指标,来移除某些不相关或冗余的特征。本发明中,采用至少一个特征过滤算法对提取的特征向量进行过滤;所述特征过滤算法包括t-test、归一化互信息(normalized mutual information)、距离相关性(distance correlation)等。优选实现方式中,首先采用三个特征过滤算法分别对提取的特征向量进行过滤;然后对过滤后的特征对应的计算结果做归一化处理,即得到每一种算法过滤后每一个特征在[0,1]内的得分情况;接着,对三种算法过滤后的特征向量取并集;同时得到每一个特征对应三种算法计算结果归一化后的平均值;依据得到的平均值大小,对过滤后的特征按照从大到小进行排序,完成特征过滤。之后,采用机器学习算法对过滤后的特征进行筛选;所述机器学习算法为随机森林算法(randomforest)、knn-1、knn-3、决策树(decisiontree)、极端梯度提升分类算法(xgboost classifier)或迭代算法(adaboost)等经典机器学习算法。依据不同算法的f1分数,选择f1分数最大且达到平稳时所需特征数量最少的算法作为特征筛选使用的算法,依据该算法确定的特征作为后续代码克隆检测中特征选择依据。
22、上述步骤s5,此阶段的目的是确定两个程序在语义上是否相似。此阶段的输入为经特征选择后的特征向量,输出为报告检测结果,即存在克隆关系或不存在克隆关系。本发明中,采用的分类模型可以为随机森林算法、knn-1、knn-3、决策树、极端梯度提升分类算法或迭代算法等。
23、与现有技术相比,本发明提供的基于马尔可夫链模型的代码克隆检测方法具有以下有益效果:
24、1)本发明基于马尔可夫链原理,利用ast中的语义信息,首先对节点类型进行划分,然后利用连续三个节点之间的信息来构建节点状态的转移概率矩阵,再基于两段代码的转移概率矩阵,以两者的距离向量作为特征向量,这样能够在充分保留代码语义信息的同时消除复杂的树匹配;
25、2)本发明对得到的特征向量的每个特征进行过滤和筛选,来减少时间开销;
26、3)本发明利用代码语法类型和令牌类型来表征节点,能够提高方法适用的可扩展性;
27、4)本发明大幅提高了克隆检测准确率,其中对type4类型克隆检测效果提升尤为明显。
- 还没有人留言评论。精彩留言会获得点赞!