一种农业知识问答方法、装置、存储介质及设备与流程
本技术涉及自然语言处理,尤其涉及一种农业知识问答方法、装置、存储介质及设备。
背景技术:
1、随着农业和科学技术的迅速发展,智慧农业的应用范围越来越广。在农业生产中,农户存在大量关于农业知识的问题。例如,小麦叶子黄了该怎么办等。
2、目前,农户获得农业知识问题的答案的方式通常有三种:一种是通过专家资源来获取问题的答案,该方式依赖于专家的主观判断,由于专家队伍人员水平经验不一,存在一定程度的误判、误答等情况。第二种是直接通过搜索引擎进行网络资源搜索来获取问题的答案,该方式需要农户自行输入查询问题,由于农户知识水平不一,可能无法对其想提出的问题进行正确描述,也无法对查询到的答案进行正确性判断,导致查询结果准确率较低。第三种是通过第三方搭建的农业专业知识图谱来获取农业问题的答案,但该方式仅适用于基础知识的问答,对于农户提出的复杂问题还是需要转由专家进行回答,影响答复效率和准确率。可见,现有的前述几种农户获得农业知识问题的答案的方式均会导致回复的效率和准确率较低,进而降低了农户的问答体验。
技术实现思路
1、本技术实施例的主要目的在于提供一种农业知识问答方法、装置、存储介质及设备,能够提高对于用户提出的农业相关问题的答复效率和准确率,进而提高用户的问答体验。
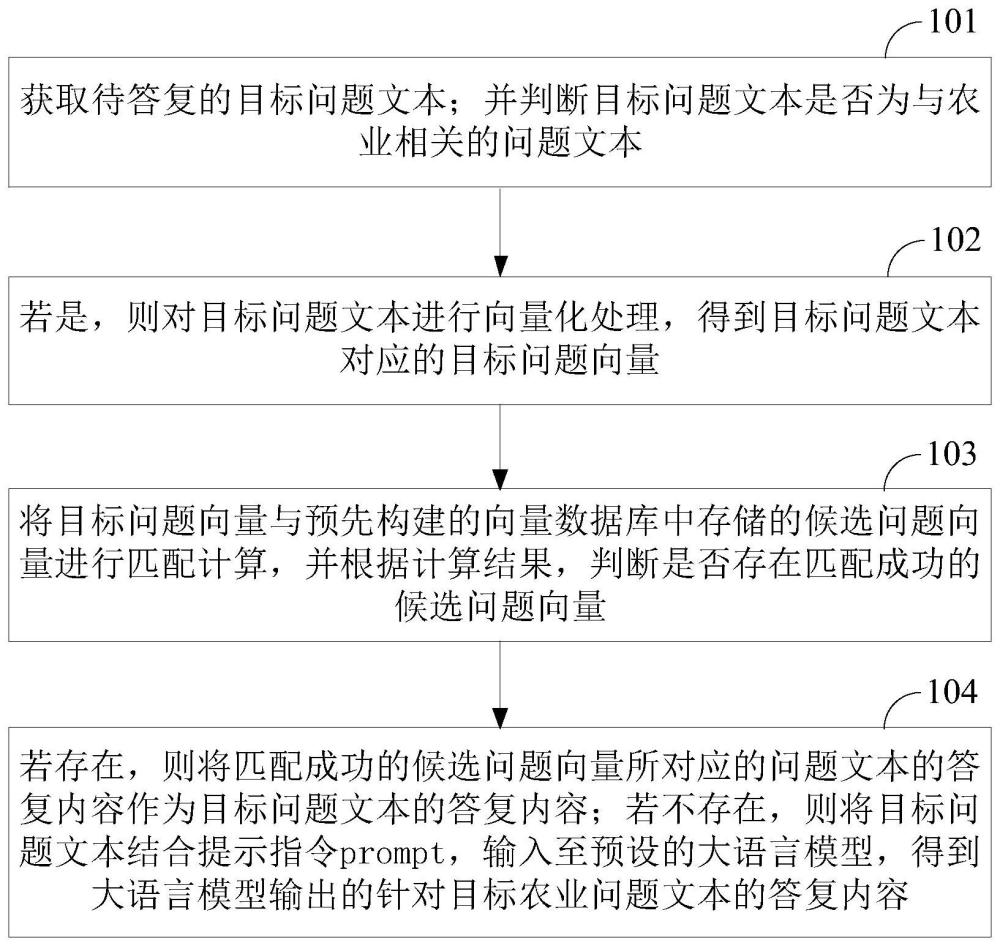
2、本技术实施例提供了一种农业知识问答方法,包括:
3、获取待答复的目标问题文本;并判断所述目标问题文本是否为与农业相关的问题文本;
4、若是,则对所述目标问题文本进行向量化处理,得到所述目标问题文本对应的目标问题向量;
5、将所述目标问题向量与预先构建的向量数据库中存储的候选问题向量进行匹配计算,并根据计算结果,判断是否存在匹配成功的候选问题向量;
6、若存在,则将匹配成功的候选问题向量所对应的问题文本的答复内容作为所述目标问题文本的答复内容;若不存在,则将所述目标问题文本结合提示指令prompt,输入至预设的大语言模型,得到大语言模型输出的针对所述目标农业问题文本的答复内容。
7、一种可能的实现方式中,所述判断所述目标问题文本是否为与农业相关的问题文本,包括:
8、利用预先构建的农业问题分类模型,对所述目标问题文本进行分类识别,以根据识别结果判断出所述目标问题文本是否为与农业相关的问题文本;
9、其中,所述农业问题分类模型是基于n层转换器模型transformer,利用大规模的样本问题数据集和目标损失函数进行训练得到的;所述n为大于1的正整数;所述目标损失函数的取值用于约束模型参数的更新,以提高模型训练过程中对于难例样本问题数据的分类准确度。
10、一种可能的实现方式中,所述目标损失函数为基于二分类交叉熵的一种的损失函数。
11、一种可能的实现方式中,所述对所述目标问题文本进行向量化处理,得到所述目标问题文本对应的目标问题向量,包括:
12、利用预先构建的农业文本向量生成模型,对所述目标问题文本进行向量化处理,得到所述目标问题文本对应的目标问题向量;
13、其中,所述农业文本向量生成模型是基于掩码自编码器的面向检索的语言模型retromae,利用大规模的样本问题数据集进行预训练后,再通过农业行业数据集进行微调训练得到的。
14、一种可能的实现方式中,所述将所述目标问题向量与预先构建的向量数据库中存储的候选问题向量进行匹配计算,并根据计算结果,判断是否存在匹配成功的候选问题向量:
15、分别计算所述目标问题向量与预先构建的向量数据库中存储的每一候选问题向量之间的相似度,并判断是否存在高于预设阈值的相似度;
16、若存在,则将高于预设阈值的相似度所对应的候选问题向量作为匹配成功的候选问题向量;若不存在,则确定向量数据库中不存在匹配成功的候选问题向量。
17、一种可能的实现方式中,所述向量数据库的构建方式如下:
18、获取与农业相关的数据,并利用预设的大语言模型对与农业相关的非结构化的数据进行实体识别和实体关系抽取,得到识别出的实体结果和抽取出的实体关系结果;
19、利用识别出的实体结果和抽取出的实体关系结果,以及与农业相关的结构化的数据和半结构化数据,构建三元组数据;
20、以所述三元组数据中实体关系为关键值,生成常规问题文本;并将所述常规问题文本结合提示指令prompt,输入至预设的大语言模型,得到大语言模型输出的与所述常规问题文本相同语义但不同表达方式的相近问题文本;
21、将所述常规问题文本和相近问题文本分别进行向量化处理,得到所述常规问题文本和所述相近问题文本对应的问题向量;并利用所述问题向量构成向量数据库。
22、一种可能的实现方式中,所述方法还包括:
23、根据所述三元组数据中实体关系与实体的对应关系,生成所述常规问题文本和所述相近问题文本对应的答复内容。
24、本技术实施例还提供了一种农业知识问答装置,包括:
25、第一获取单元,用于获取待答复的目标问题文本;并判断所述目标问题文本是否为与农业相关的问题文本;
26、向量化单元,用于若判断出所述目标问题文本是与农业相关的问题文本,则对所述目标问题文本进行向量化处理,得到所述目标问题文本对应的目标问题向量;
27、匹配单元,用于将所述目标问题向量与预先构建的向量数据库中存储的候选问题向量进行匹配计算,并根据计算结果,判断是否存在匹配成功的候选问题向量;
28、获得单元,用于若判断出存在匹配成功的候选问题向量,则将匹配成功的候选问题向量所对应的问题文本的答复内容作为所述目标问题文本的答复内容;若判断出不存在匹配成功的候选问题向量,则将所述目标问题文本结合提示指令prompt,输入至预设的大语言模型,得到大语言模型输出的针对所述目标农业问题文本的答复内容。
29、一种可能的实现方式中,所述第一获取单元具体用于:
30、利用预先构建的农业问题分类模型,对所述目标问题文本进行分类识别,以根据识别结果判断出所述目标问题文本是否为与农业相关的问题文本;
31、其中,所述农业问题分类模型是基于n层转换器模型transformer,利用大规模的样本问题数据集和目标损失函数进行训练得到的;所述n为大于1的正整数;所述目标损失函数的取值用于约束模型参数的更新,以提高模型训练过程中对于难例样本问题数据的分类准确度。
32、一种可能的实现方式中,所述目标损失函数为基于二分类交叉熵的一种的损失函数。
33、一种可能的实现方式中,所述向量化单元具体用于:
34、利用预先构建的农业文本向量生成模型,对所述目标问题文本进行向量化处理,得到所述目标问题文本对应的目标问题向量;
35、其中,所述农业文本向量生成模型是基于掩码自编码器的面向检索的语言模型retromae,利用大规模的样本问题数据集进行预训练后,再通过农业行业数据集进行微调训练得到的。
36、一种可能的实现方式中,所述匹配单元包括:
37、计算子单元,用于分别计算所述目标问题向量与预先构建的向量数据库中存储的每一候选问题向量之间的相似度,并判断是否存在高于预设阈值的相似度;
38、匹配子单元,用于若存在高于预设阈值的相似度,则将高于预设阈值的相似度所对应的候选问题向量作为匹配成功的候选问题向量;若不存在,则确定向量数据库中不存在匹配成功的候选问题向量。
39、一种可能的实现方式中,所述装置还包括:
40、第二获取单元,用于获取与农业相关的数据,并利用预设的大语言模型对与农业相关的非结构化的数据进行实体识别和实体关系抽取,得到识别出的实体结果和抽取出的实体关系结果;
41、构建单元,用于利用识别出的实体结果和抽取出的实体关系结果,以及与农业相关的结构化的数据和半结构化数据,构建三元组数据;
42、第一生成单元,用于以所述三元组数据中实体关系为关键值,生成常规问题文本;并将所述常规问题文本结合提示指令prompt,输入至预设的大语言模型,得到大语言模型输出的与所述常规问题文本相同语义但不同表达方式的相近问题文本;
43、构成单元,用于将所述常规问题文本和相近问题文本分别进行向量化处理,得到所述常规问题文本和所述相近问题文本对应的问题向量;并利用所述问题向量构成向量数据库。
44、一种可能的实现方式中,所述装置还包括:
45、第二生成单元,用于根据所述三元组数据中实体关系与实体的对应关系,生成所述常规问题文本和所述相近问题文本对应的答复内容。
46、本技术实施例还提供了一种农业知识问答设备,包括:处理器、存储器、系统总线;
47、所述处理器以及所述存储器通过所述系统总线相连;
48、所述存储器用于存储一个或多个程序,所述一个或多个程序包括指令,所述指令当被所述处理器执行时使所述处理器执行上述农业知识问答方法中的任意一种实现方式。
49、本技术实施例还提供了一种计算机可读存储介质,所述计算机可读存储介质中存储有指令,当所述指令在终端设备上运行时,使得所述终端设备执行上述农业知识问答方法中的任意一种实现方式。
50、本技术实施例还提供了一种计算机程序产品,所述计算机程序产品在终端设备上运行时,使得所述终端设备执行上述农业知识问答方法中的任意一种实现方式。
51、本技术实施例提供的一种农业知识问答方法、装置、存储介质及设备,首先获取待答复的目标问题文本;并判断目标问题文本是否为与农业相关的问题文本,若是,则对目标问题文本进行向量化处理,得到目标问题文本对应的目标问题向量;然后将目标问题向量与预先构建的向量数据库中存储的候选问题向量进行匹配计算,并根据计算结果,判断是否存在匹配成功的候选问题向量;若存在,则将匹配成功的候选问题向量所对应的问题文本的答复内容作为目标问题文本的答复内容;若不存在,则将目标问题文本结合提示指令prompt,输入至预设的大语言模型,得到大语言模型输出的针对目标农业问题文本的答复内容。
52、可见,由于本技术是先对用户提出的与农业相关的目标问题文本进行向量化处理,然后再利用预先构建的向量数据库进行更为精确的向量匹配,从而能够有效提高对于目标问题的答复效率和准确率,并且还能够在向量未匹配成功时利用大语言模型为用户提供更为准确的生成式答复内容,进而提高了目标用户的问答体验。
- 还没有人留言评论。精彩留言会获得点赞!