一种基于双向反馈的协同深度强化学习方法及系统与流程
本发明涉及物联网控制系统和机器学习与强化学习,尤其涉及一种基于双向反馈的协同深度强化学习方法及系统。
背景技术:
1、物联网(internet of things,简称iot)是指通过各种信息传感器、射频识别技术、全球定位系统、红外感应器、激光扫描器等各种装置与技术,实时采集任何需要监控、连接、互动的物体或过程,采集其声、光、热、电、力学、化学、生物、位置等各种需要的信息,通过各类网络接入,实现物与物、物与人的泛在连接,实现对物品和过程的智能化感知、识别和管理。物联网是一个基于互联网、传统电信网等的信息承载体,它让所有能够被独立寻址的普通物理对象形成互联互通的网络。物联网通过专有或通用网络把各类设备接入各类平台达到通信和控制的目的,是互联网的延伸,物联网平台一般通过物模型与设备进行,一种典型的物联网应用包括车辆无人驾驶的实现。现有的物联网设备不断借助物模型向平台上报事件和属性,同时平台可以调用设备服务下放指令。但物模型模型一般限于设备基本能力,缺乏设备动态建模能力和最优控制模式,同时控制器不能通过积累经验数据持续提升。
2、机器学习可以自动从数据中发现规律和模式,在计算机视觉、自然语言处理、信息推荐和自动驾驶等领域有着重要的应用。强化学习是机器学习的一种重要范式,强化学习系统一般包含智能学习体和环境,智能学习体不断与环境进行交互、不断地观测环境状态信息和获取环境激励。智能学习体的目标就是通过不断调整输入环境的动作信号,期望获取到最大的累积激励。强化学习已有着广泛的应用,大量创造性应用已出现在游戏、金融、决策和规划等领域,例如alphago、alphago zero和gpt等具体模型应用都是强化学习取得成功的重要案例。
3、监督学习也是机器学习的重要范式,监督学习通过建立算法和输入大量带有标签即知道输入和结果的数据调整算法参数达到回归或者分类的目的。新兴的模仿学习是一种重要的监督学习方式,通过分析人类在环境中的动作来模仿人的动作从而形成策略。模仿学习本质是一种监督学习方式,学习算法通过对人类操作数据的学习模仿智能学习体的策略。
4、但是,强化学习在复杂的环境中很难发现最优策略、发现的策略不能得到合理解释,各类参数难以调整和估计,同时忽略一个最重要的知识来演:人类积累的知识和人对环境的快速学习适应能力。没有有效集成人类的知识和学习使强化学习在复杂环境中不能获取最佳效果。另一方面,模仿学习本身不系统,学习所得的策略不能够回避人类学习的前置偏见、不能对学习策略进一步有效提升、不能够通过环境的交互获取策略调整、不能持续不断的提升经验、不能够获取期望的累积最大收益。
5、由此可知,现有技术缺少针对物联网应用领域的综合集成人类学习和机器学习范式,两类学习所得结果无法有效集成或进行相互参考辅助提升,不能实现同时纳入强大的人类学习能力和机器学习强大的算法模型能力。
技术实现思路
1、为解决现有技术的不足,本发明提出一种基于双向反馈的协同深度强化学习方法及系统,首先通过深度神经网络学习人类探索的策略,然后通过策略评估和迭代来进一步对策略进行提升,同时不断地与环境交互持续提升策略,有效地解决了强化学习不能有效纳入人类知识的问题,特别适用于训练用于部署在物联网平台的控制器,实现下发最优控制器指令达到预定目标。
2、为实现以上目的,本发明所采用的技术方案包括:
3、一种基于双向反馈的协同深度强化学习方法,其特征在于,包括:
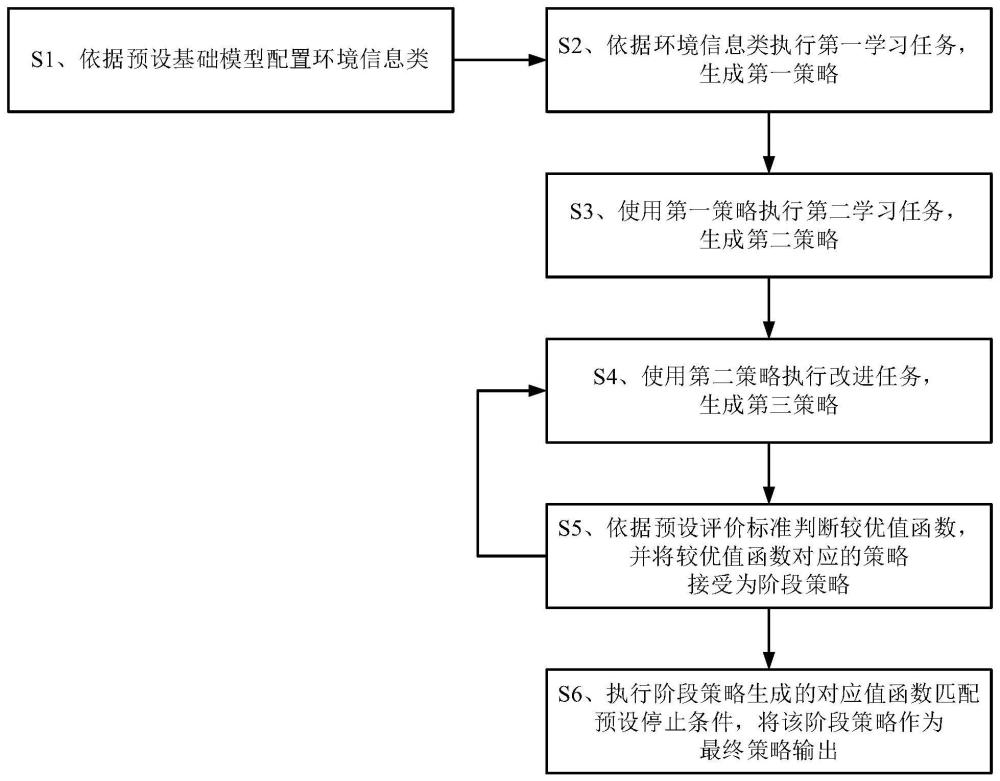
4、s1、依据预设基础模型配置环境信息类,所述基础模型包括有限马尔科夫模型,所述环境信息类包括系统状态信息、激励信号、预设的概率转移矩阵和对应控制动作的控制信号输入;
5、s2、依据环境信息类执行第一学习任务,生成第一策略,所述第一学习任务包括基于人工操作数据的监督学习任务;
6、s3、使用第一策略执行第二学习任务,生成第二策略,所述第二学习任务包括基于输入策略的强化学习迭代任务;
7、s4、使用第二策略执行改进任务,生成第三策略,所述改进任务包括基于人工操作数据的输入策略修订任务;
8、s5、分别执行第二策略和第三策略生成对应的第二值函数和第三值函数,依据预设评价标准判断第三值函数是否优于第二值函数,并将较优值函数对应的策略接受为阶段策略;
9、s6、使用阶段策略作为新的第二策略重复执行步骤s4至s5,直至执行阶段策略生成的对应值函数匹配预设停止条件,将该阶段策略作为最终策略输出。
10、进一步地,所述方法还包括:
11、s7、使用阶段策略更新环境信息类,并依据更新后的环境信息类重新执行步骤s2至s3生成环境更新的第二策略;
12、s8、使用环境更新的第二策略作为输入策略重新执行步骤s4至s5生成环境更新的阶段策略,并使用环境更新的阶段策略执行步骤s6。
13、进一步地,所述系统状态信息包括标准矢量数据和多通道数据。
14、进一步地,所述预设基础模型为包括标准神经网络和卷积神经网络的混合深度神经网络。
15、进一步地,所述使用阶段策略更新环境信息类包括执行阶段策略生成对应值函数,使用对应值函数更新概率转移矩阵。
16、进一步地,所述人工操作数据包括历史记录数据和/或人工输入数据。
17、本发明还涉及一种基于双向反馈的协同深度强化学习系统,其特征在于,包括:
18、环境信息管理模块,用于依据预设基础模型配置环境信息类;
19、监督学习模块,用于依据环境信息类执行第一学习任务,生成第一策略;
20、强化学习模块,用于使用输入策略执行第二学习任务,生成第二策略;
21、策略改进模块,用于使用输入策略执行改进任务,生成第三策略;
22、策略评价模块,用于分别执行第二策略和第三策略生成对应的第二值函数和第三值函数,依据预设评价标准判断第三值函数是否优于第二值函数,并将较优值函数对应的策略接受为阶段策略;
23、策略输出模块,用于判断执行阶段策略生成的对应值函数是否匹配预设停止条件,并将匹配预设停止条件的阶段策略作为最终策略输出。
24、本发明还涉及一种计算机可读存储介质,其特征在于,所述存储介质上存储有计算机程序,所述计算机程序被处理器执行时实现上述的方法。
25、本发明还涉及一种电子设备,其特征在于,包括处理器和存储器;
26、所述存储器,用于存储环境信息类、第一策略、第二策略和第三策略;
27、所述处理器,用于通过调用环境信息类、第一策略、第二策略和第三策略,执行上述的方法。
28、本发明还涉及一种计算机程序产品,包括计算机程序和/或指令,其特征在于,该计算机程序和/或指令被处理器执行时实现上述方法的步骤。
29、本发明的有益效果为:
30、采用本发明所述基于双向反馈的协同深度强化学习方法及系统,能够在强化学习过程中有效纳入人类控制知识,提升了强化学习效率,保证了学习策略的高效性,加速了强化学习收敛速度,辅助提升强化学习最优策略发现能力。同时本发明协同深度强化学习方案能够借助策略函数进行人机交替学习,构造出有效纳入人类知识学习和机器强化学习的策略,包含人机两种知识总结在策略函数中,通过策略函数交替迭代统一了知识的集成和学习提升。进一步地,本发明方案还有效集成了未知环境的探索,把环境估计和人机协同统一在一个框架中,提升了协同深度强化学习方法的实用性。本发明方法执行中混合深度神经网络可以有效编码和训练各类状态信息,适用于部署最优控制器到物联网平台端,控制器通过物联网与环境设备进行远程交互控制,有效帮助提高策略升级变动灵活性和降低了设备端计算资源要求。
- 还没有人留言评论。精彩留言会获得点赞!