一种基于人体网格恢复的三维重建方法
本发明涉及计算机视觉领域,特别是涉及一种基于人体网格恢复的三维重建方法。
背景技术:
1、与基于单帧的人体网格恢复算法不同,当神经网络的输入变为单目视频序列时,算法需要建模的是动态的时域人体运动。目前主流方法对此任务的处理主要分为两个阶段,即先使用神经网络对输入的图片或视频进行预处理,得到一些静态的中间表示,再通过对这些中间表示的进一步处理与建模,同时借助统计人体模型(如smpl模型),输出运动的三维人体网格参数。
2、以往的方法基本遵循编码器-解码器框架,通过不同结构的编码器(如循环神经网络、全局注意力网络、transformer等)对由预训练的卷积神经网络提取的图像特征序列进行人体运动规律的时域建模。这些方法的主要思想是设计更加合适的神经网络结构,来更好地捕获人体运动先验,但是它们却忽视了对不同样本之间的差异性进行针对性的判别学习,这可能会导致模型在遇到人体外形或姿态相似的样本时,无法精确恢复人体网格参数。
3、需要说明的是,在上述背景技术部分公开的信息仅用于对本申请的背景的理解,因此可以包括不构成对本领域普通技术人员已知的现有技术的信息。
技术实现思路
1、本发明的主要目的在于克服上述背景技术的缺陷,提供一种基于人体网格恢复的三维人体重建方法。
2、为实现上述目的,本发明采用以下技术方案:
3、一种基于人体网格恢复的三维重建方法,包括:
4、将包含一系列帧的视频序列作为输入,在视频帧中检测和提取人体特征,根据提取的人体特征,使用三维重建算法预测人体的形状和姿态,恢复出人体三维网格模型;
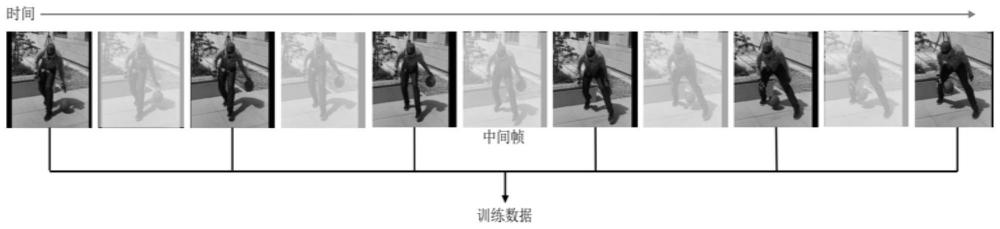
5、其中,将所述视频序列以中间帧为界分为过去帧和未来帧两部分,分别提取过去帧和未来帧的信息,将未来帧进行时域翻转,使用过去帧和时域翻转的未来帧为中间帧的参数预测提供过去和未来的信息;从而引入对比学习来增强特征提取。
6、进一步地:
7、对视频序列进行循环神经网络的时域数据增强,使用两个单向门控循环单元gru分别提取过去帧和未来帧的信息,对未来帧进行时域翻转,使得两个单向门控循环单元gru的最后一个输出都是与中间帧相邻一帧的特征。
8、根据所述两个单向门控循环单元gru的训练目标一致性,设计对比学习的代理任务和相应的损失函数,并进行时域数据增强,包括:(1)按特定步长进行时域抽帧来模拟人体不同的运动速度;(2)对过去帧和未来帧取不对称长度来增强网络对于过去和未来信息不对称情况的鲁棒性学习。
9、通过基于动量编码器的监督式对比特征提取器,来增强对过去帧和未来帧信息的提取和判别;其中,所述监督式对比特征提取器包括提取过去帧信息的编码器和提取未来帧信息的编码器,二者分别包括由单向gru组成的常规编码器和动量编码器,其中常规编码器在训练过程中正常更新参数,动量编码器参数进行动量更新;取动量编码器的最后一个输出构建动态字典,并采用队列方式更新其中的特征,常规编码器的最后一个输出会和字典中的特征值计算对比损失。
10、所述对比特征提取器基于moco v2结构,核心结构动量编码器和动态字典与mocov2中的相同,使用监督式的对比学习来训练网络。
11、所述基于动量编码器的监督式对比特征提取器使用个体判别作为代理任务,损失函数为含有动态字典的infonce损失。
12、通过基于自注意力机制的时域特征融合模块,来对单向gru的所有输出进行特征聚合,提取和利用过去帧和未来帧的信息,以辅助当前中间帧的人体参数预测。
13、所述基于注意力机制的时域特征融合模块为多级时域特征融合模块,包括空间信息聚合单元siau、基于自注意力机制的时间信息聚合单元tiau以及全局信息聚合单元giau,其中,所述空间信息聚合单元siau聚合来自输入帧的空间信息,所述基于自注意力机制的时间信息聚合单元tiau聚合来自时域编码器输出的时间信息,所述全局信息聚合单元giau将来自空间和时间信息聚合单元的信息进行融合。
14、一种计算机可读存储介质,存储有计算机程序,所述计算机程序由处理器执行时,实现所述的基于人体网格恢复的三维重建方法。
15、本发明具有如下有益效果:
16、本发明提出一种基于人体网格恢复的三维人体重建方法,其中,将所述视频序列以中间帧为界分为过去帧和未来帧两部分,分别提取过去帧和未来帧的信息,将未来帧进行时域翻转,使用过去帧和时域翻转的未来帧为中间帧的参数预测提供过去和未来的信息。由此,本发明引入对比学习来增强特征提取器的性能,提高模型对视频中人体姿态和形状的精确估计能力,通过上述方法对过去帧和未来帧的信息进行有效地提取和使用,模型可以更好地捕捉到人体运动的规律和特征,从而更准确地预测中间帧的人体参数。通过引入对比学习技术,能够增强网络对于样本特征的判别性学习,实现更加精确的视频三维人体重建。具体阐述如下:
17、针对现有算法重点学习三维人体运动先验,忽视了对不同人体样本之间的相似性和差异性进行针对性建模优化的问题,本发明提出了基于对比学习的三维人体重建方法。该方法通过引入对比训练机制,增强了网络对于人体运动样本特征的判别性学习,使得样本数据在特征空间中的分布更加易于人体参数的判别,从而提高网络对于不同人体运动样本的检测能力。
18、进一步地,本发明还设计了一个基于注意力机制的多级时域特征融合模块,从而有效地聚合来自时域编码器输出的特征,以提高模型对视频中人体姿态和形状的精确估计能力。
19、在主流数据集3dpw、mpi-inf-3dhp以及human3.6m上的预测精度和时域平滑度的性能表现,充分验证了本发明的有效性。本发明可为计算机视觉领域提供更加高效、准确和鲁棒的三维人体网格恢复算法,为各种应用场景提供更为强大的支持。
20、本发明实施例中的其他有益效果将在下文中进一步述及。
技术特征:
1.一种基于人体网格恢复的三维重建方法,其特征在于,包括:
2.如权利要求1所述的基于人体网格恢复的三维重建方法,其特征在于,对视频序列进行循环神经网络的时域数据增强,使用两个单向门控循环单元gru分别提取过去帧和未来帧的信息,对未来帧进行时域翻转,使得两个单向门控循环单元gru的最后一个输出都是与中间帧相邻一帧的特征。
3.如权利要求2所述的基于人体网格恢复的三维重建方法,其特征在于,根据所述两个单向门控循环单元gru的训练目标一致性,设计对比学习的代理任务和相应的损失函数,按特定步长进行时域抽帧来模拟人体不同的运动速度,过去帧和未来帧取不对称长度来增强网络对于过去和未来信息不对称情况的鲁棒性学习。
4.如权利要求3所述的基于人体网格恢复的三维重建方法,其特征在于,所述时域数据增强包括根据固定的步长从所述视频序列中抽取帧,或者从所述视频序列中删除未来帧,或者从所述视频序列中删除过去帧。
5.如权利要求2至4任一项所述的基于人体网格恢复的三维重建方法,其特征在于,通过基于动量编码器的监督式对比特征提取器,来增强对过去帧和未来帧信息的提取和判别;其中,所述监督式对比特征提取器包括提取过去帧信息的编码器和提取未来帧信息的编码器,二者分别包括由单向gru组成的常规编码器和动量编码器,其中常规编码器在训练过程中正常更新参数,动量编码器参数进行动量更新;取动量编码器的最后一个输出构建动态字典,并采用队列方式更新其中的特征,常规编码器的最后一个输出会和字典中的特征值计算对比损失。
6.如权利要求5所述的基于人体网格恢复的三维重建方法,其特征在于,所述对比特征提取器基于moco v2结构,核心结构动量编码器和动态字典与moco v2中的相同,使用监督式的对比学习来训练网络。
7.如权利要求5所述的基于人体网格恢复的三维重建方法,其特征在于,所述基于动量编码器的监督式对比特征提取器使用个体判别作为代理任务,损失函数为含有动态字典的infonce损失。
8.如权利要求2至7任一项所述的基于人体网格恢复的三维重建方法,其特征在于,通过基于自注意力机制的时域特征融合模块,来对单向gru的所有输出进行特征聚合,提取和利用过去帧和未来帧的信息,以辅助当前中间帧的人体参数预测。
9.如权利要求8所述的基于人体网格恢复的三维重建方法,其特征在于,所述基于注意力机制的时域特征融合模块为多级时域特征融合模块,包括空间信息聚合单元siau、基于自注意力机制的时间信息聚合单元tiau以及全局信息聚合单元giau,其中,所述空间信息聚合单元siau聚合来自输入帧的空间信息,所述基于自注意力机制的时间信息聚合单元tiau聚合来自时域编码器输出的时间信息,所述全局信息聚合单元giau将来自空间和时间信息聚合单元的信息进行融合。
10.一种计算机可读存储介质,存储有计算机程序,其特征在于,所述计算机程序由处理器执行时,实现如权利要求1至9任一项所述的基于人体网格恢复的三维重建方法。
技术总结
一种基于人体网格恢复的三维人体重建方法,包括:将包含一系列帧的视频序列作为输入,在视频帧中检测和提取人体特征,根据提取的人体特征,使用三维重建算法预测重建人体的形状和姿态,恢复出人体三维网格模型;其中,将所述视频序列以中间帧为界分为过去帧和未来帧两部分,分别提取过去帧和未来帧的信息,将未来帧进行时域翻转,使用过去帧和时域翻转的未来帧为中间帧的参数预测提供过去和未来的信息;从而引入对比学习来增强特征提取。本发明引入对比学习来增强特征提取器的性能,提高模型对视频中人体姿态和形状的精确估计能力。
技术研发人员:杨文明,杜耀耀,廖庆敏
受保护的技术使用者:清华大学深圳国际研究生院
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!