一种基于对抗学习的多样本AutoMix数据增强方法和系统
本发明属于数据增强领域,具体的,涉及一种基于对抗学习的多样本automix数据增强方法和系统。
背景技术:
1、深度神经网络已经证实了在图像处理、视频处理等各个任务中的成功。但是这些强大的网络通常设计的非常复杂,需要数以万计的参数和庞大的数据库的支撑。然而,在一些特殊的领域,如医疗等,它们的数据库是轻量的,复杂的网络模型会变得过拟合,导致网络能力很差。为此,研究人员们提出了大量的数据增强方法来弥补监督数据的不足。实验证明,如果采用有效的数据增强的方法,可以显著提高深度神经网络的泛化能力,提高识别的准确率以及扩充大量的新数据。
2、mixup数据增强手段被广泛应用于提高深度神经网络的泛化能力。其中,mixup又可以分为手工制作的mixup增强和基于显著性引导的mixup增强。手工制作的mixup增强可以包括mixup算法、cutmix算法、fmix算法、recursivemix算法、smoothmix算法、manifoldmixup算法等;基于显著性引导的mixup增强可以包括saliencymix算法、snapmix算法、attentive-cutmix算法、puzzlemix算法、co-mix算法、transmix算法、tokenmix算法、mixpro算法等。
3、然而,手工制作的mixup增强方法是在不考虑其上下文和标签的情况下随机混合图像,因此,在混合图像中可能会遗漏目标对象,从而导致标签不匹配的问题;而利用图像中的显著性信息来混合样本和标签的mixup增强方法可以缓解这一问题。除此之外,由于图像的生成与目标任务(即分类)没有直接关系,因此,由人类先验知识即基于显著性的指导生成的图像可能对目标网络的训练并不有效。此外,不可能为目标训练生成所有可能的混合样本。因此,随机选择的合成样本可能不能代表分类任务,最终降低分类器的泛化。此外,生成的样本会重复输入到目标网络中,在长时间训练中不可避免地出现过拟合。
4、为了克服这些问题,基于mixup的自动增强方法通过一个具有良好复杂度和精度权衡的子网络生成增强图像。该方法包含两个子任务:mixup样本生成子任务和分类子任务,通过端到端方式最小化分类损失,对两个子任务进行了联合优化。但由于这两个子任务的优化目标是一致的,因此生成模块可能无法得到有效的引导,从而产生简单的混合样本来实现这一目标,从而限制了样本的多样化。因此,在这种简单的例子上训练的分类器容易发生过拟合,从而导致测试集上的泛化性能较差。另一个限制是,目前的自动mixup方法只是为了生成图像而混合两幅图像,不能有效地利用训练样本中产生的丰富和有鉴别性的信息。
技术实现思路
1、有鉴于此,本发明的目的是提供一种基于对抗学习的多样本automix数据增强方法和系统。
2、本发明的目的是通过以下技术方案实现的:
3、一种基于对抗学习的多样本automix数据增强方法,包括:
4、获取样本数据集s及其对应的标签;
5、利用adautomix模型对样本数据集进行数据增强,
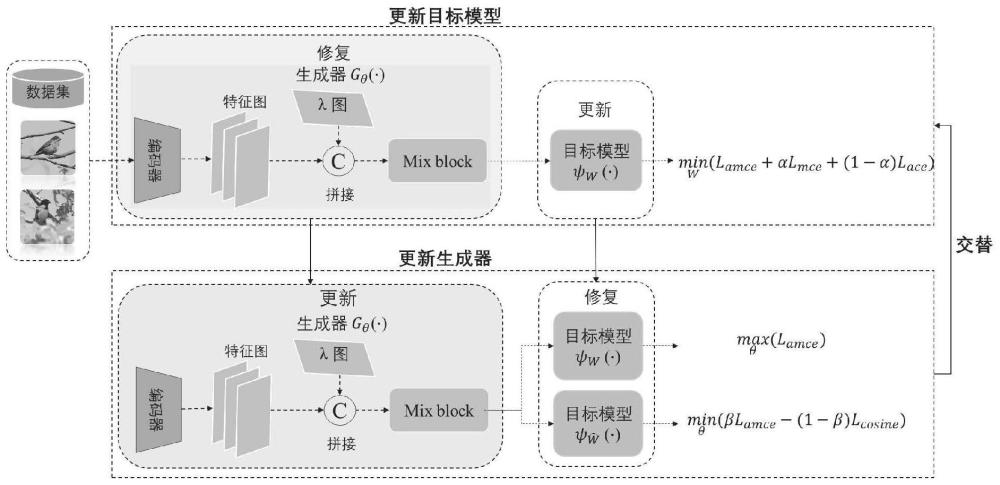
6、其中,所述adautomix模型包含混合样本生成模块和样本分类模块,
7、混合样本生成模块包括编码器和混合器,样本分类模块包括分类器,
8、所述混合样本生成模块从样本数据集s中任意选择n个样本组成多样本集x={x1,x2,...,xn},对于每个多样本集x,基于注意力机制生成混合样本xmix;
9、通过对抗学习联合优化混合样本生成模块和样本分类模块,其中,对抗学习的目标函数为:
10、
11、其中,
12、l1=lamce(ψω,y)+αlmce(ψω(xmix),ymix)+(1-α)lace(ψω,y),
13、
14、
15、
16、
17、
18、
19、e(·)表示期望值,lce表示交叉熵损失函数,lamce表示对抗损失函数,ψω表示样本经过分类器预测后验概率,xmix表示混合样本,ymix表示与混合样本xmix对应的混合标签,y表示多样本集x中的样本对应的标签集合,lmce表示混合损失函数,α和β表示正则项参数,表示利用教师模型得到的样本预测后验概率,λn表示与样本xn对应的混合比例,cosine表示余弦相似函数,lcosine表示余弦损失,ω*和θ*分别表示样本分类模块和混合样本生成模块中的网络参数ω和θ的最优值。
20、本发明还提供了一种基于对抗学习的多样本automix数据增强系统,该系统包括
21、样本数据获取模块,用于获取样本数据集s及其对应的标签;
22、数据增强模块,用于利用adautomix模型对样本数据集进行数据增强,其中,所述adautomix模型包含混合样本生成模块和样本分类模块,
23、混合样本生成模块包括编码器和混合器,样本分类模块包括分类器,
24、所述混合样本生成模块从样本数据集s中任意选择n个样本组成多样本集x={x1,x2,...,xn},对于每个多样本集x,基于注意力机制生成混合样本xmix;
25、通过对抗学习联合优化混合样本生成模块和样本分类模块,其中,对抗学习的目标函数为:
26、
27、其中,
28、l1=lamce(ψω,y)+αlmce(ψω(xmix),ymix)+(1-α)lace(ψω,y),
29、
30、
31、
32、
33、
34、
35、e(·)表示期望值,lce表示交叉熵损失函数,lamce表示对抗损失函数,ψω表示样本经过分类器预测后验概率,xmix表示混合样本,ymix表示与混合样本xmix对应的混合标签,y表示多样本集x中的样本对应的标签集合,lmce表示混合损失函数,α和β表示正则项参数,表示利用教师模型得到的样本预测后验概率,λn表示与样本xn对应的混合比例,cosine表示余弦相似函数,lcosine表示余弦损失,ω*和θ*分别表示样本分类模块和混合样本生成模块中的网络参数ω和θ的最优值。
36、进一步地,对于每个多样本集x,基于注意力机制生成混合样本xmix包括:
37、将所述多样本数据集x中的每个样本经过编码器进行编码,生成初始特征图,
38、将混合比例λ={λ1,λ2,...,λn}嵌入到初始特征图,生成嵌入特征图;
39、将嵌入特征图经过1×1卷积以进一步提取特征并通过自注意力机制确定所述每个样本的query值、key值和value值,分别记为qn、kn和vn,n=1,2,...,n,
40、将所述每个样本对应的qn、kn和vn经过交叉注意力模块,得到每个样本对应的权重矩阵pn;
41、将n个权重按照指定维度进行拼接,并将拼接后的结果与对应的样本进行点积,生成具有多个样本特征的混合样本xmix。
42、进一步地,所述每个样本对应的权重矩阵pn用公式表示为:
43、
44、其中,d表示设定的缩放因子,以对分子进行数值缩放从而使得pn达到正常数值而不是较大的数值,(·)t表示转置。
45、进一步地,编码器的参数根据样本分类模块中的分类器权重的指数平均移动进行更新,用公式表示为:
46、
47、其中,表示编码器参数,t表示训练时的迭代次数,ξ表示移动参数,ξ∈(0,1]。
48、进一步地,所述教师模型中的权值的更新为分类器权重的移动平均,用公式表示为:
49、
50、其中,t表示训练时的迭代次数,ξ表示移动参数,ξ∈(0,1]。
51、本发明的有益效果是:
52、本发明提供了一种基于对抗学习的在线数据增强方法,通过端到端的训练,可以自动生成混合样本;
53、本发明通过混合样本生成模块生成硬样本来增加目标网络(即分类网络)的损耗,使得目标网络通过这些硬样本进行训练,学习一种鲁棒的特征表示来提高分类准确度,并通过构建对抗网络框架,共同优化目标网络(即分类)训练和混合样本生成器;
54、本发明为了避免图像固有意义的崩溃,引入指数平均移动和余弦相似度来减少搜索空间;
55、本发明通过注意力机制进行混合样本生成,将多个样本而不是两个样本组合起来生成混合样本,该生成器的结构不随输入图像的增加而改变,有效地利用了训练样本中产生的丰富和有鉴别性的信息,从而使得生成的混合样本更加多样化。
56、本发明的其他优点、目标和特征在某种程度上将在随后的说明书中进行阐述,并且在某种程度上,基于对下文的考察研究对本领域技术人员而言将是显而易见的,或者可以从本发明的实践中得到教导。本发明的目标和其他优点可以通过下面的说明书来实现和获得。
- 还没有人留言评论。精彩留言会获得点赞!