面向语义特性选择与注意力融合的视频描述生成方法及系统
本发明涉及自然语言处理与计算机视觉,特别涉及一种面向语义特性选择与注意力融合的视频描述生成方法及系统。
背景技术:
1、面向视频理解的视频描述任务需要从视频中提取出有意义的对象、场景、动作等高级语义信息,并据此生成逻辑清晰、语义通顺的文本内容。视频描述生成是一个涉及计算机视觉和自然语言处理的交叉领域问题,他可以将视频内容转化为文本或语义表示,可以帮助人们更加快速、高效地检索和管理海量视频资源。鉴于视频数据的时空特性与语义的多样性、复杂性,其主要挑战在于如何有效地将视频的视觉信息与自然语言描述相结合,以生成准确、流畅的描述。如何实现理解视频内容并描述其内容,已成为当前视频理解领域的研究热点。
2、频描述生成方法大致分为三类,主要有:基于手工特征提取的方法,基于深度学习的视频描述方法,基于强化学习的生成方法。其中,基于手工特征提取的方法,利用模板的技术来完成的,使得生成的描述性语句语法较为准确,但因为固定模板的存在使得描述性语句受到限制,让句子的生成变得极为不灵活且内容不丰富。基于深度学习的方法中,典型的研究框架为采用“编码器-解码器”范式对视频进行描述。基于强化学习的方法中,以gan网络为例,通过训练生成器和判别器,使生成器能够生成与真实数据相似的新数据,这种方法通常需要使用额外的数据集来训练gan模型。该三类方法在视频描述生成中仍然存在一些困难:1)视频中有大量静态语义对象,很多工作没有这些语义对象进行筛选,而是停留在视频帧级别特征上对视频内容进行分析,缺乏细粒度的语义对象选择。2)由于视频的运动特性,一些研究工作对于动作语义的捕获更为关注,突破了原有视频动作识别任务中只能根据视频内容输出有限动作类型的限制。但其更为关注动作语义,忽视了描述语句的其他组成部分,在句子结构、灵活性表达等方面都受到极大制约。3)在特征融合方面,大多数现有的方法只是简单地对不同模态的特征进行级联操作,缺乏高级语义之间的相关性挖掘,特征融合方式相对简单且效率低下。
技术实现思路
1、为此,本发明提供一种面向语义特性选择与注意力融合的视频描述生成方法及系统,解决现有技术中因缺乏细粒度语义对象选择、有限动作类型限制及缺乏高级语义之间相关性挖掘等影响视频描述应用的问题。
2、按照本发明所提供的设计方案,一方面,提供一种面向语义特性选择与注意力融合的视频描述生成方法,包含:
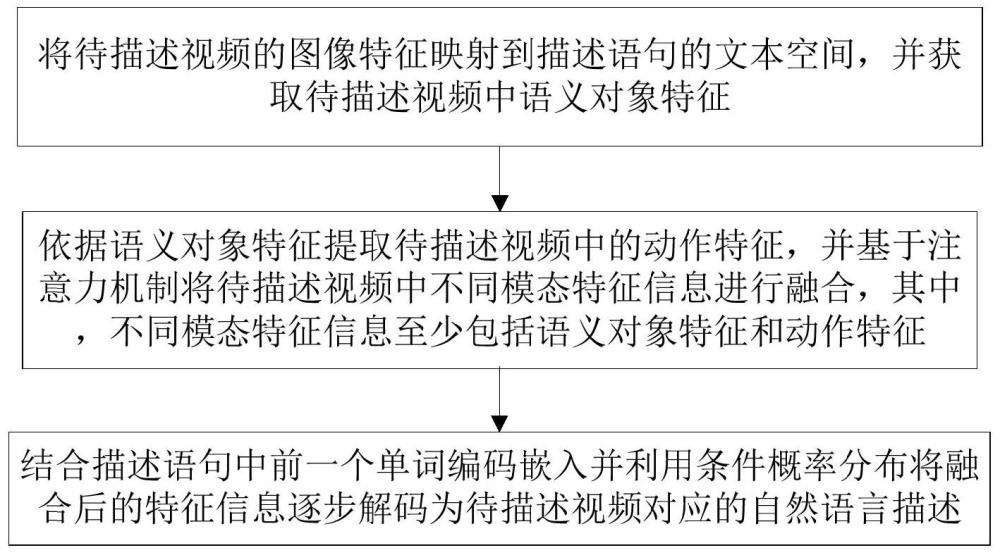
3、将待描述视频的图像特征映射到描述语句的文本空间,并获取待描述视频中语义对象特征;
4、依据语义对象特征提取待描述视频中的动作特征,并基于注意力机制将待描述视频中不同模态特征信息进行融合,其中,不同模态特征信息至少包括语义对象特征和动作特征;
5、结合描述语句中前一个单词编码嵌入并利用条件概率分布将融合后的特征信息逐步解码为待描述视频对应的自然语言描述。
6、作为本发明面向语义特性选择与注意力融合的视频描述生成方法,进一步地,将待描述视频的图像特征映射到描述语句的文本空间,包含:
7、首先,选取待描述视频中若干帧作为关键帧,将关键帧及其相邻区域的视频帧作为预训练对象检测器模型的输入,利用对象检测器模型获取待描述视频中的目标检测特征,其中,目标检测特征至少包括初始对象特征、初始动作特征和视频帧特征;
8、然后,利用编码器对初始对象特征进行编码输出;并针对编码输出结果,结合视频帧特征和初始动作特征并利用解码器将输入映射到描述语句文本空间,以选取并输出视频语义对象特征,其中,解码器包含:获取输入数据向量表示的lstm网络和将lstm网络输出映射到文本空间的全连接层。
9、作为本发明面向语义特性选择与注意力融合的视频描述生成方法,进一步地,全连接层中将lstm网络输出映射到文本空间,借助描述语句对网络进行监督学习,其学习过程包含:
10、首先,基于描述语句中实体和视频中实体两者最小化距离构建损失函数;
11、然后,利用描述语句并基于损失函数对lstm网络进行监督学习,以学习视频内容在文本空间的向量表示。
12、作为本发明面向语义特性选择与注意力融合的视频描述生成方法,进一步地,依据语义对象特征提取待描述视频中的动作特征,包含:
13、利用预训练的c3d三维卷积神经网络提取样本数据中的初始动作,并结合语义对象特征通过交叉注意力融合获取视频中的动作特征,其中,c3d三维卷积神经网络预训练中,将初始动作和动作相关特征拼接并利用lstm网络和全连接层将拼接特征映射到文本空间,通过最小化视频描述监督信号文本中相关动作特征和拼接映射到文本空间后特征之间的距离来对实现神经网络的学习优化。
14、作为本发明面向语义特性选择与注意力融合的视频描述生成方法,进一步地,基于注意力机制将待描述视频中不同模态特征信息进行融合,包含:
15、首先,使用加性注意力机制将动作特征和语义对象特征融合;
16、接着,使用多层注意力机制对融合后的特征进行深度层次特征提取,并获取相似度矩阵;
17、然后,利用softmax函数对相似度矩阵归一化并获取注意力权重,将注意力权重和深度层次提取特征进行加权平均,以获取不同模态特征的融合特征。
18、作为本发明面向语义特性选择与注意力融合的视频描述生成方法,进一步地,结合描述语句中前一个单词编码嵌入并利用条件概率分布将融合后的特征信息逐步解码为待描述视频对应的自然语言描述,包含:
19、首先,将融合特征转换为包含时间步的解码器输入向量序列;
20、然后,依据视觉特征和描述语句中前一个单词编码嵌入并利用预训练的lstm解码器来预测当前时刻单词,通过逐步解码直至生成完整描述句子或达到预定义最大句子长度,获取视频对应的自然语言描述。
21、作为本发明面向语义特性选择与注意力融合的视频描述生成方法,进一步地,lstm解码器训练过程,包含:
22、利用交叉熵损失设置训练损失函数,利用给定的视频和视频描述并基于训练损失函数对lstm解码器进行训练优化。
23、进一步地,本发明还提供一种面向语义特性选择与注意力融合的视频描述生成系统,包含:预处理模块、融合模块和输出模块,其中,
24、预处理模块,用于将待描述视频的图像特征映射到描述语句的文本空间,并获取待描述视频中语义对象特征;
25、融合模块,用于依据语义对象特征提取待描述视频中的动作特征,并基于注意力机制将待描述视频中不同模态特征信息进行融合,其中,不同模态特征信息至少包括语义对象特征和动作特征;
26、输出模块,用于将融合后的特征信息逐步解码为待描述视频对应的自然语言描述。
27、本发明的有益效果:
28、1、针对视频中有大量静态语义对象,很多工作没有这些语义对象进行筛选,而是停留在视频帧级别特征上对视频内容进行分析,缺乏细粒度的语义对象选择等的问题,通过高效的语义特征挑选并利用特征映射将图像特征映射到文本空间,促使模型从描述语句学习语义对象在文本空间的语义表示,能够有效缓解视觉空间和语义空间之间的语义偏差。
29、2、针对在特征融合方面,大多数现有的方法只是简单地对不同模态的特征进行级联操作,缺乏高级语义之间的相关性挖掘,特征融合方式相对简单且效率低下等的问题,通过特征融合编码动作特征并使用语义对象特征作为query查找动作特征,能够提高动作编码器输出的准确性。
30、3、并在msvd和msr-vtt数据集上的对比实验,通过实验结果表明本案方案达到了比较先进的结果;与此同时,大量的消融实验也能够验证本案方案的有效性,能够在多媒体视频自动描述场景中的应用部署,具有较好的应用前景。
- 还没有人留言评论。精彩留言会获得点赞!