基于ElasticSearch的关系型数据库的数据管理方法和设备与流程
本发明属于大数据领域,具体涉及一种基于elastic search的关系型数据库的数据管理方法及其对应的数据管理设备。
背景技术:
1、当前在大数据的时代,企业通常需要基于关系型数据库的数据为用户提供服务,但随着企业规模的扩大,数据量也在日益增大。与此同时,面对较大数据量的检索时,关系型数据库往往达不到高效检索的要求。目前企业普遍的解决方案是数据库分表分区或者增加字段索引,这种方式可以提升查询效率,但是仍无法满足针对大数据量下对任意字段的精确检索和关键词检索。
2、为了解决这些问题,部分企业希望将关系型数据库中的数据同步到elasticserach,并利用其强大的分布式检索功能提供检索服务。为了实现这一目标,目前主流的数据管理方案有数据双写、基于sql抽取、logstash同步等。但是这些方案存在程序硬编码、操作的复杂性高的缺点,且不能支持对多种关系型数据库根据配置创建索引,因而在现阶段仍难以推广应用。
技术实现思路
1、为了解决多个关系型数据库的管理难度大,成本高,难以实现分布式检索的问题,本发明提供一种基于elastic search的关系型数据库的数据管理方法及设备。
2、本发明采用以下技术方案实现:
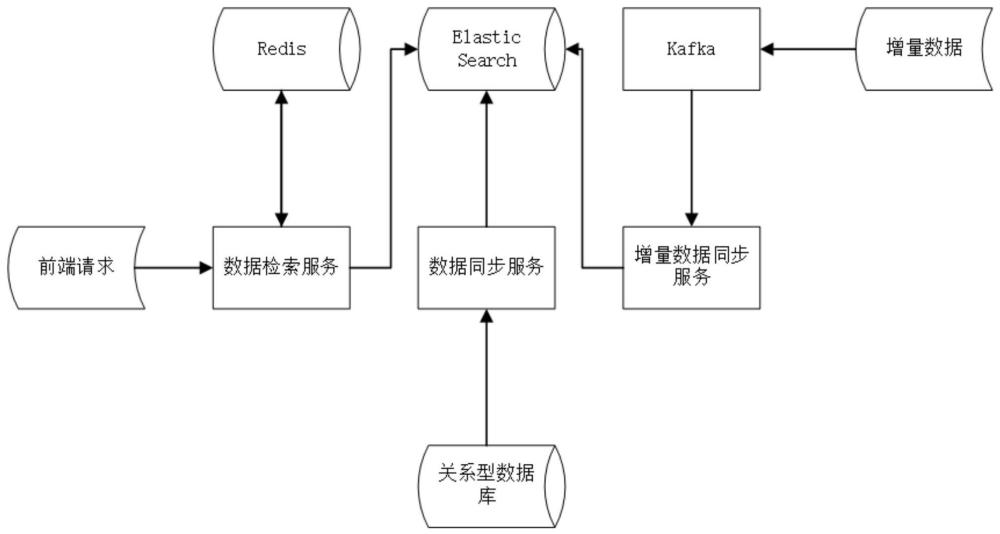
3、一种基于elastic search的关系型数据库的数据管理方法,其用于将多个关系型数据库的基础档案同步到elastic search,并提供对应分布式快速检索功能。该数据管理方法支持的服务内容包括数据全量同步,数据增量同步和数据检索。
4、一、数据全量同步
5、首先,基于spring boot框架的applicationrunner在启动时扫描并获取所有标注esindex的类,作为需要创建索引的数据集。然后,根据数据集据检查elastic search中是否存在具体的索引,如果不存在则读取索引配置,根据数据集中类的索引配置注解补充索引的名称、分片、刷新周期。接着,接收到同步任务的调度之后,读取配置的数据源信息,流式读取数据。最后,使用生产者消费者模型读写数据。
6、二、数据增量同步
7、创建增量数据同步服务监听kafka约定的主题;基础档案变更时,前置程序推送变更的类型和变更的内容到kafka,增量数据同步服务根据消费kafka的变更信息同步更新elastic search的数据,进而将增量数据从kafka经由增量数据同步服务同步到elasticsearch存储。其中,所述变更类型包括新增、删除、修改。
8、三、数据检索
9、前端根据用户输入的检索条件向后端发起查询请求,后端服务根据接收的请求参数去判断参数是否需要分词检索,并通过获取需要检索的字段上设置的分词策略,设置对应的检索规则。其中,ngram策略不进行检索条件分词,其余策略使用分词。检索会根据用户的单位权限封装查询参数,并向elastic search发起分页查询。查询出的结果根据查询条件缓存到redis服务端并返回至用户。
10、作为本发明进一步的改进,在数据全量同步过程中,当监听到配置的索引未创建时,自动根据设置的索引模板创建对应的索引,并通过任务执行管理里配置的执行策略,执行档案数据同步的任务。当程序启动并扫描到配置的索引在elastic search中不存在时,会读取resources文件夹下面的setting.xml作为索引模板,补充配置的索引名称和分词,完成索引的创建。其中,可配置的分词策略包括:自定义ngram分词,中文ik分词,默认分词。
11、作为本发明进一步的改进,任务执行管理是一个分布式任务调度平台,通过配置执行器与任务可以按照设置的执行策略执行指定的任务,用于档案数据同步方法的任务调度。
12、作为本发明进一步的改进,在数据全量同步的数据写入阶段,读取数据源的配置信息,通过对应的驱动建立与数据源的连接,按照配置的地址、用户名、密码、连接池等信息初始化数据源连接池;并使用流式读取的方式分批处理数据写入elastic search。
13、作为本发明进一步的改进,数据同步时,系统会根据配置创建指定线程数的线程池,如果没有指定,则默认创建cpu*3线程数的线程池用于处理数据。
14、作为本发明进一步的改进,数据全量同步服务的执行步骤如下:
15、s1:创建一个固定capacity的阻塞队列,创建的线程池持续监听队列中是否有数据集写入:是则根据数据元素的元数据信息将具体的数据集写入指定的索引中;否则阻塞等待写入。
16、s2:根据配置的sql语句建立的数据源通过流式查询拉取数据;读取配置文件中配置的数据集的大小作为默认读取的数据集合大小,查询完的数据集作为一个resultset集进行数据处理,转换成具体的对象实体集合。
17、s3:将处理后的对象实体集合放入创建的阻塞队列中,经由线程池处理后存储在elastic search的数据库中。
18、s4:当阻塞队列中的数据全部入库后,自动发送一个中断信号以关闭线程池;系统在收到中断信号后,停止执行线程池中的所有工作线程并销毁线程池。
19、作为本发明进一步的改进,数据检索服务的执行步骤如下:
20、s01:用户输入检索的条件,包括设备资产编号、设备通讯地址、配送站名称、配送站编号等信息,前端根据查询条件封装请求报文,并携带用户的单位编码请求对应的后端服务。
21、s02:后端服务根据接收的请求参数去判断参数是否需要分词检索,通过获取需要检索的字段上设置的分词策略,设置对应的检索规则。其中,ngram策略不进行检索条件分词,其余策略使用分词。
22、s03:根据用户的单位权限封装查询参数,并向elastic search发起分页查询。
23、s04:后端根据获取到的查询数据,将检索条件作为key写入redis,每次检索会先根据条件去redis读取缓存,缓存命中则直接返回命中的结果。
24、作为本发明进一步的改进,步骤s03中,在针对用户权限进行档案信息过滤时,先根据用户的单位编码获取其子集单位编码,然后以空格隔开拼接成filter里的match查询参数。最后,elastic search匹配其单位编码符合的档案数据并返回。
25、作为本发明进一步的改进,步骤s04中,采用哈希作为缓存的数据类型,根据单位编码、分页大小和关键词生成redis的key,分页页码作为哈希中key的字段,检索内容作为value。在redis中写入缓存时,同步设置过期时间。
26、本发明还包括一种基于elastic search的关系型数据库的数据管理设备,其包括存储器、处理器以及存储在存储器上并可在处理器上运行的计算机程序,处理器执行所述计算机程序时,创建出一个用于执行如前述的基于elastic search的关系型数据库的数据管理方法的数据管理系统,进而实现将多个关系型数据库的内容全量同步或增量同步到elastic search中,并提供分布式检索功能以响应用户发出的数据检索请求。
27、本发明提供的技术方案,具有如下有益效果:
28、本发明支持通过配置和模板文件指定创建索引的结构,当监听到索引不存在时会根据模板自动创建索引,能够很好的支持配置新的索引。本发明支持通过配置指定关系型数据库,满足多种数据库同步elastic search,可以支持多个数据库的平滑切换。
29、本发明使用生产者消费者模型处理数据,使用阻塞队列用户存储数据,提升了数据同步的效率,满足大批量数据下的同步功能。本发明提供了通过消息队列的方式实现数据增量同步的方式,当存在增量数据时能够很好的进行解耦。
30、本发明提供了通过前端参数映射成具体的java类,并根据java类生成具体的检索语句的功能。本发明提供了对查询结果按照策略进行缓存的功能,可以支持并发性和实时性要求较高的业务场景。
- 还没有人留言评论。精彩留言会获得点赞!