一种基于多模态融合的三维脑图像分割算法的制作方法
本发明涉及图像分割,尤其涉及一种基于多模态融合的三维脑图像分割算法。
背景技术:
1、近年来随着深度学习的快速发展,使用深度学习的手段进行医学图像分割已经成为当下的热门趋势。在多模态医学成像技术不断发展的背景下,多模态医学图像分割方法也被广泛地研究。多模态医学图像分割是指将多模态图像的信息进行融合,从而提高分割性能。相较于单模态医学图像而言,多模态医学图像可以为医生提供丰富的互补信息,能降低信息不确定性、提高临床诊断与分割精度。医学图像本身具有数据量少,真是标签难以获取的特点,多模态医学图像相较于医学图像数据量更小。对于这样的小样本数据,如何进行充分的利用,在有效的数据条件下进行充分的训练从而达到良好的分割性能,提高分割精度以达到辅助诊断的目的,是目前亟待解决的问题。
技术实现思路
1、本发明的目的在于提供一种基于多模态融合的三维脑图像分割算法,从而解决现有技术中存在的前述问题。
2、为了实现上述目的,本发明采用的技术方案如下:
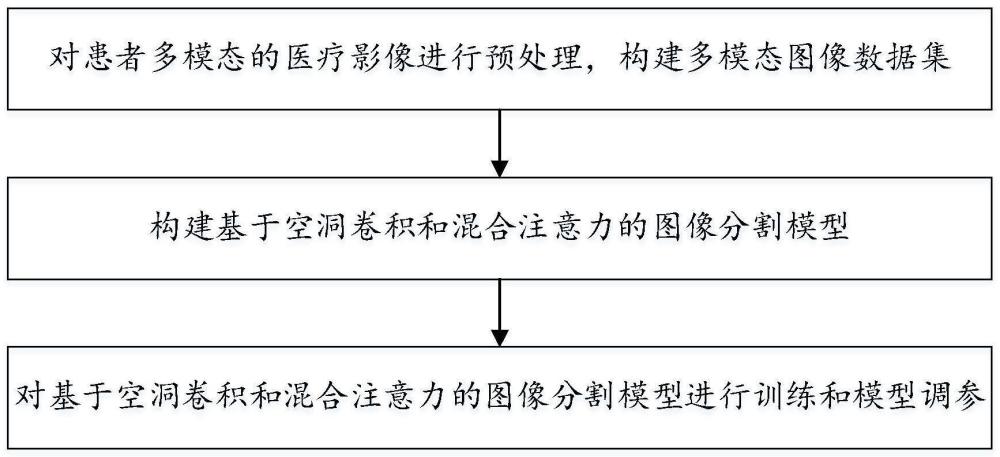
3、一种基于多模态融合的三维脑图像分割算法,包括如下步骤,
4、s1、对患者多模态的医疗影像进行预处理,构建多模态图像数据集;
5、s2、构建基于空洞卷积和混合注意力的图像分割模型;
6、所述基于空洞卷积和混合注意力的图像分割模型包括编码器和解码器,所述编码器包括两个并行的特征提取模块,特征提取模块由通道空洞模块和实例归一化层构成,所述通道空洞模块包括四个并行的卷积率不同的空洞卷积模块,在通道空洞模块中引入实例归一化层构成特征提取模块;所述解码器包括混合注意力模块和上采样模块,所述混合注意力模块包括通道注意力子模块和空间注意力子模块,所述通道注意力子模块使用自注意力机制,以适配全局平均池化特征和全局最大池化特征对于不同图像特征萃取阶段的不同,所述空间注意力子模块,基于通道注意力的映射,沿着通道轴用通道分离操作将通道提取特征进行分离;
7、s3、对基于空洞卷积和混合注意力的图像分割模型进行训练和模型调参;
8、利用多模态图像数据集对基于空洞卷积和混合注意力的图像分割模型进行训练,并利用由tversky损失函数和cross-entropy损失函数构成的总损失函数更新模型参数,以获取训练好的参数最优的模型;利用训练好的参数最优的模型进行图像分割。
9、优选的,患者的医疗影像包括t1、t1ce、t2、flair四个模态图像,每个模态图像使用不同的方式反映同一脑区域的状况;每个医疗影像都具备分割标签,所述分割标签包括四类,分别为背景、坏疽、浮肿和增强肿瘤。
10、优选的,步骤s1具体为,将患者的四个模态图像进行灰度标准化,保持背景区域为0,统一裁剪成同比大小,将处理后的四个模态图像合并成一个4d图像,并且和分割标签一起存成一个.h5文件,之后对其进行数据增强操作,构建多模态图像数据集。
11、优选的,根据各个模态图像的不同特点及成像原理,将t1和t1ce分成一组,t2图像与flair分成一组,将两组图像并行输入编码器中进行特征提取。
12、优选的,所述特征提取模块的最后还设置有dropout层,用于防止过拟合。
13、优选的,所述混合注意力模块的工作过程为,通道注意力子模块将通道注意力张量与原始输入张量相乘,获取通道特征,空间注意力子模块基于通道注意力映射将通道特征沿着通道轴分为两组,基于两组特征分别生成各自的二维空间注意力张量,将两组特征分别与各自的二维空间注意力张量相乘,获取两个空间特征,再将这两个空间特征相加获取最终特征。
14、优选的,所述总损失函数的计算方式如下,
15、loss=tverskyloss+αcrossentropyloss
16、其中,loss为总损失函数;tverskyloss为tversky损失函数;crossentropyloss为cross-entropy损失函数;α为系数,α≥0。
17、本发明的有益效果是:1、将多模态的医疗影像处理后合成一个文件进行保存,既保留了原有数据的影像信息,又压缩了大小,方便存储,也便于后续输入模型进行训练。2、基于多模态融合处理策略使用通道空洞卷积模块代替unet编码器进行特征提取,能够对各模态的信息得到更充分的利用,提高各通道的提取能力再进行特征融合,利用更多的输入像素,提高模型的映射能力,丰富图像的特征表达。3、在unet网络结构的解码器部分引入轻量的混合注意力模块架构,不增加计算资源,又对特征的提取和处理起到了更好的效果,对模型表现和模型复杂度起到了一个平衡作用。
技术特征:
1.一种基于多模态融合的三维脑图像分割算法,其特征在于:包括如下步骤,
2.根据权利要求1所述的基于多模态融合的三维脑图像分割算法,其特征在于:患者的医疗影像包括t1、t1ce、t2、flair四个模态图像,每个模态图像使用不同的方式反映同一脑区域的状况;每个医疗影像都具备分割标签,所述分割标签包括四类,分别为背景、坏疽、浮肿和增强肿瘤。
3.根据权利要求1所述的基于多模态融合的三维脑图像分割算法,其特征在于:步骤s1具体为,将患者的四个模态图像进行灰度标准化,保持背景区域为0,统一裁剪成同比大小,将处理后的四个模态图像合并成一个4d图像,并且和分割标签一起存成一个.h5文件,之后对其进行数据增强操作,构建多模态图像数据集。
4.根据权利要求2所述的基于多模态融合的三维脑图像分割算法,其特征在于:根据各个模态图像的不同特点及成像原理,将t1和t1ce分成一组,t2图像与flair分成一组,将两组图像并行输入编码器中进行特征提取。
5.根据权利要求1所述的基于多模态融合的三维脑图像分割算法,其特征在于:所述特征提取模块的最后还设置有dropout层,用于防止过拟合。
6.根据权利要求1所述的基于多模态融合的三维脑图像分割算法,其特征在于:所述混合注意力模块的工作过程为,通道注意力子模块将通道注意力张量与原始输入张量相乘,获取通道特征,空间注意力子模块基于通道注意力映射将通道特征沿着通道轴分为两组,基于两组特征分别生成各自的二维空间注意力张量,将两组特征分别与各自的二维空间注意力张量相乘,获取两个空间特征,再将这两个空间特征相加获取最终特征。
7.根据权利要求1所述的基于多模态融合的三维脑图像分割算法,其特征在于:所述总损失函数的计算方式如下,
技术总结
本发明公开了一种基于多模态融合的三维脑图像分割算法,包括S1、对患者多模态的医疗影像进行预处理,构建多模态图像数据集;S2、构建基于空洞卷积和混合注意力的图像分割模型;S3、对图像分割模型进行训练和模型调参。优点是:将多模态的医疗影像处理后合成一个文件进行保存,既保留了原有数据的影像信息,又压缩了大小,方便存储,也便于后续输入模型进行训练。使用通道空洞卷积模块代替UNet编码器进行特征提取,能够对各模态的信息得到更充分的利用,提高各通道的提取能力再进行特征融合,利用更多的输入像素,提高模型的映射能力,丰富图像的特征表达。引入轻量的混合注意力模块架构,不增加计算资源,又对特征的提取和处理起到了更好的效果。
技术研发人员:孙佳钰,彭扬,张睿,李宏军,吴怿迪
受保护的技术使用者:北京友普信息技术有限公司
技术研发日:
技术公布日:2024/3/21
- 还没有人留言评论。精彩留言会获得点赞!